Artificial Intelligence
Category: Learning Levels

Create a virtual stock technical analyst using Amazon Bedrock Agents
n this post, we create a virtual analyst that can answer natural language queries of stocks matching certain technical indicator criteria using Amazon Bedrock Agents.

How Crexi achieved ML models deployment on AWS at scale and boosted efficiency
Commercial Real Estate Exchange, Inc. (Crexi), is a digital marketplace and platform designed to streamline commercial real estate transactions. In this post, we will review how Crexi achieved its business needs and developed a versatile and powerful framework for AI/ML pipeline creation and deployment. This customizable and scalable solution allows its ML models to be efficiently deployed and managed to meet diverse project requirements.

How 123RF saved over 90% of their translation costs by switching to Amazon Bedrock
This post explores how 123RF used Amazon Bedrock, Anthropic’s Claude 3 Haiku, and a vector store to efficiently translate content metadata, significantly reduce costs, and improve their global content discovery capabilities.
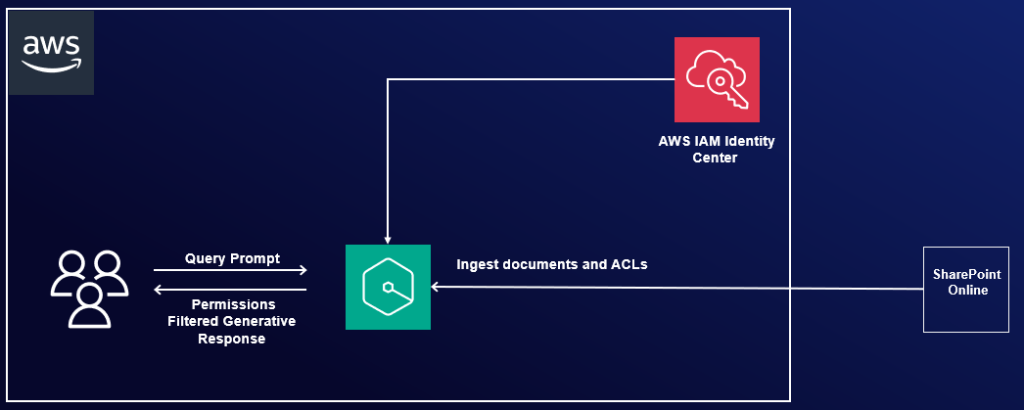
Connect SharePoint Online to Amazon Q Business using OAuth 2.0 ROPC flow authentication
In this post, we explore how to integrate Amazon Q Business with SharePoint Online using the OAuth 2.0 ROPC flow authentication method. We provide both manual and automated approaches using PowerShell scripts for configuring the required Azure AD settings. Additionally, we demonstrate how to enter those details along with your SharePoint authentication credentials into the Amazon Q console to finalize the secure connection.

Accelerating Mixtral MoE fine-tuning on Amazon SageMaker with QLoRA
In this post, we demonstrate how you can address the challenges of model customization being complex, time-consuming, and often expensive by using fully managed environment with Amazon SageMaker Training jobs to fine-tune the Mixtral 8x7B model using PyTorch Fully Sharded Data Parallel (FSDP) and Quantized Low Rank Adaptation (QLoRA).

Governing the ML lifecycle at scale, Part 3: Setting up data governance at scale
This post dives deep into how to set up data governance at scale using Amazon DataZone for the data mesh. The data mesh is a modern approach to data management that decentralizes data ownership and treats data as a product. It enables different business units within an organization to create, share, and govern their own data assets, promoting self-service analytics and reducing the time required to convert data experiments into production-ready applications.

Enhance speech synthesis and video generation models with RLHF using audio and video segmentation in Amazon SageMaker
In this post, we show you how to implement an audio and video segmentation solution using SageMaker Ground Truth. We guide you through deploying the necessary infrastructure using AWS CloudFormation, creating an internal labeling workforce, and setting up your first labeling job. By the end of this post, you will have a fully functional audio/video segmentation workflow that you can adapt for various use cases, from training speech synthesis models to improving video generation capabilities.

Using responsible AI principles with Amazon Bedrock Batch Inference
In this post, we explore a practical, cost-effective approach for incorporating responsible AI guardrails into Amazon Bedrock Batch Inference workflows. Although we use a call center’s transcript summarization as our primary example, the methods we discuss are broadly applicable to a variety of batch inference use cases where responsible considerations and data protection are a top priority.
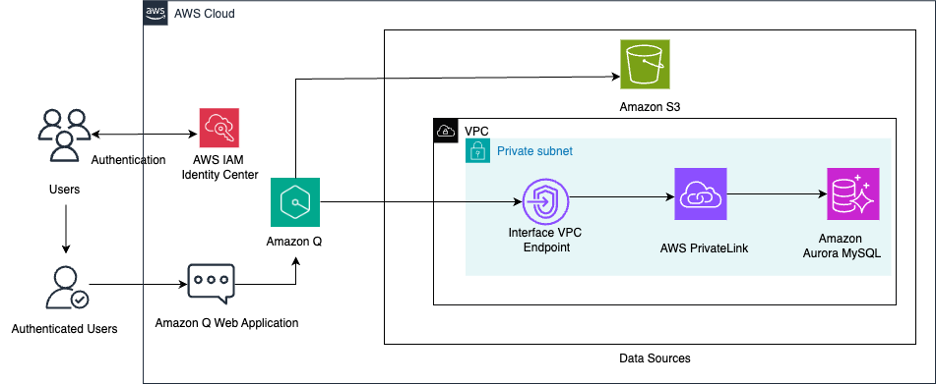
Unify structured data in Amazon Aurora and unstructured data in Amazon S3 for insights using Amazon Q
In today’s data-intensive business landscape, organizations face the challenge of extracting valuable insights from diverse data sources scattered across their infrastructure. Whether it’s structured data in databases or unstructured content in document repositories, enterprises often struggle to efficiently query and use this wealth of information. In this post, we explore how you can use Amazon […]

Automate Q&A email responses with Amazon Bedrock Knowledge Bases
In this post, we illustrate automating the responses to email inquiries by using Amazon Bedrock Knowledge Bases and Amazon Simple Email Service (Amazon SES), both fully managed services. By linking user queries to relevant company domain information, Amazon Bedrock Knowledge Bases offers personalized responses.