Artificial Intelligence
Category: Learning Levels

Speed up your time series forecasting by up to 50 percent with Amazon SageMaker Canvas UI and AutoML APIs
We’re excited to announce that Amazon SageMaker Canvas now offers a quicker and more user-friendly way to create machine learning models for time-series forecasting. SageMaker Canvas is a visual point-and-click service that enables business analysts to generate accurate machine learning (ML) models without requiring any machine learning experience or having to write a single line of code. SageMaker […]
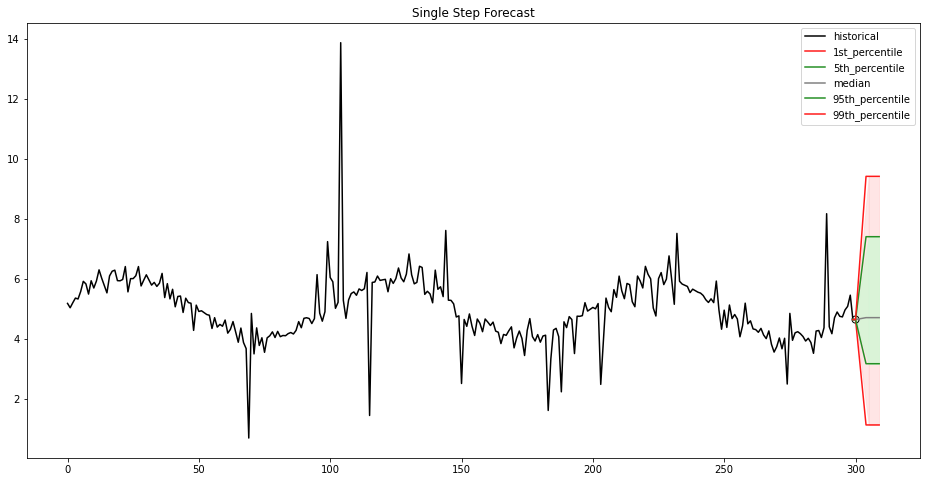
Robust time series forecasting with MLOps on Amazon SageMaker
In the world of data-driven decision-making, time series forecasting is key in enabling businesses to use historical data patterns to anticipate future outcomes. Whether you are working in asset risk management, trading, weather prediction, energy demand forecasting, vital sign monitoring, or traffic analysis, the ability to forecast accurately is crucial for success. In these applications, […]

Create a Generative AI Gateway to allow secure and compliant consumption of foundation models
In the rapidly evolving world of AI and machine learning (ML), foundation models (FMs) have shown tremendous potential for driving innovation and unlocking new use cases. However, as organizations increasingly harness the power of FMs, concerns surrounding data privacy, security, added cost, and compliance have become paramount. Regulated and compliance-oriented industries, such as financial services, […]
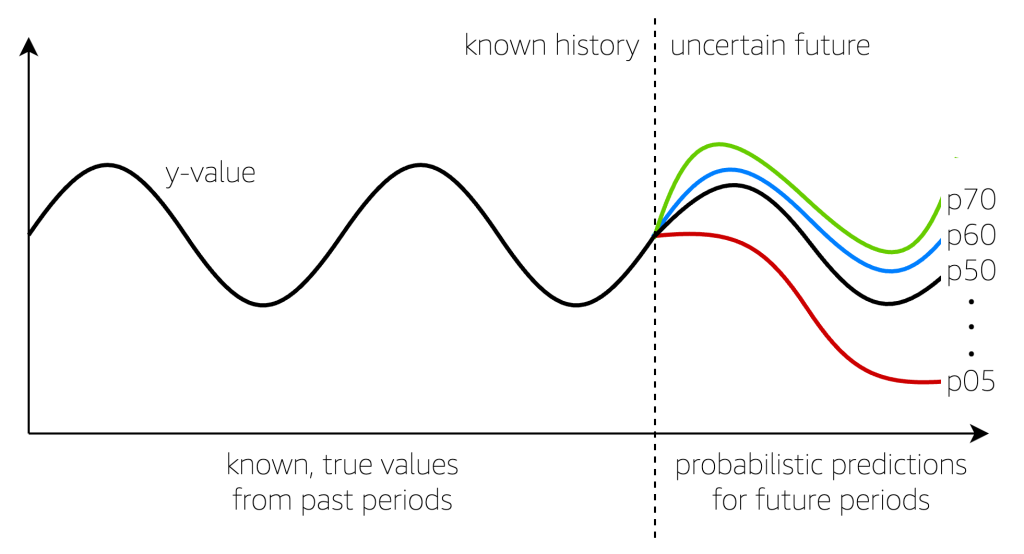
Beyond forecasting: The delicate balance of serving customers and growing your business
Companies use time series forecasting to make core planning decisions that help them navigate through uncertain futures. This post is meant to address supply chain stakeholders, who share a common need of determining how many finished goods are needed over a mixed variety of planning time horizons. In addition to planning how many units of […]

A generative AI-powered solution on Amazon SageMaker to help Amazon EU Design and Construction
The Amazon EU Design and Construction (Amazon D&C) team is the engineering team designing and constructing Amazon Warehouses across Europe and the MENA region. The design and deployment processes of projects involve many types of Requests for Information (RFIs) about engineering requirements regarding Amazon and project-specific guidelines. These requests range from simple retrieval of baseline […]

MDaudit uses AI to improve revenue outcomes for healthcare customers
MDaudit provides a cloud-based billing compliance and revenue integrity software as a service (SaaS) platform to more than 70,000 healthcare providers and 1,500 healthcare facilities, ensuring healthcare customers maintain regulatory compliance and retain revenue. Working with the top 60+ US healthcare networks, MDaudit needs to be able to scale its artificial intelligence (AI) capabilities to […]

Build and deploy ML inference applications from scratch using Amazon SageMaker
As machine learning (ML) goes mainstream and gains wider adoption, ML-powered inference applications are becoming increasingly common to solve a range of complex business problems. The solution to these complex business problems often requires using multiple ML models and steps. This post shows you how to build and host an ML application with custom containers […]

Improve throughput performance of Llama 2 models using Amazon SageMaker
We’re at an exciting inflection point in the widespread adoption of machine learning (ML), and we believe most customer experiences and applications will be reinvented with generative AI. Generative AI can create new content and ideas, including conversations, stories, images, videos, and music. Like most AI, generative AI is powered by ML models—very large models […]

Train and deploy ML models in a multicloud environment using Amazon SageMaker
In this post, we demonstrate one of the many options that you have to take advantage of AWS’s broadest and deepest set of AI/ML capabilities in a multicloud environment. We show how you can build and train an ML model in AWS and deploy the model in another platform. We train the model using Amazon SageMaker, store the model artifacts in Amazon Simple Storage Service (Amazon S3), and deploy and run the model in Azure.

Orchestrate Ray-based machine learning workflows using Amazon SageMaker
Machine learning (ML) is becoming increasingly complex as customers try to solve more and more challenging problems. This complexity often leads to the need for distributed ML, where multiple machines are used to train a single model. Although this enables parallelization of tasks across multiple nodes, leading to accelerated training times, enhanced scalability, and improved […]