Artificial Intelligence
Customizing coding companions for organizations

Generative AI models for coding companions are mostly trained on publicly available source code and natural language text. While the large size of the training corpus enables the models to generate code for commonly used functionality, these models are unaware of code in private repositories and the associated coding styles that are enforced when developing with them. Consequently, the generated suggestions may require rewriting before they are appropriate for incorporation into an internal repository.
We can address this gap and minimize additional manual editing by embedding code knowledge from private repositories on top of a language model trained on public code. This is why we developed a customization capability for Amazon CodeWhisperer. In this post, we show you two possible ways of customizing coding companions using retrieval augmented generation and fine-tuning.
Our goal with CodeWhisperer customization capability is to enable organizations to tailor the CodeWhisperer model using their private repositories and libraries to generate organization-specific code recommendations that save time, follow organizational style and conventions, and avoid bugs or security vulnerabilities. This benefits enterprise software development and helps overcome the following challenges:
- Sparse documentation or information for internal libraries and APIs that forces developers to spend time examining previously written code to replicate usage.
- Lack of awareness and consistency in implementing enterprise-specific coding practices, styles and patterns.
- Inadvertent use of deprecated code and APIs by developers.
By using internal code repositories for additional training that have already undergone code reviews, the language model can surface the use of internal APIs and code blocks that overcome the preceding list of problems. Because the reference code is already reviewed and meets the customer’s high bar, the likelihood of introducing bugs or security vulnerabilities is also minimized. And, by carefully selecting of the source files used for customization, organizations can reduce the use of deprecated code.
Design challenges
Customizing code suggestions based on an organization’s private repositories has many interesting design challenges. Deploying large language models (LLMs) to surface code suggestions has fixed costs for availability and variable costs due to inference based on the number of tokens generated. Therefore, having separate customizations for each customer and hosting them individually, thereby incurring additional fixed costs, can be prohibitively expensive. On the other hand, having multiple customizations simultaneously on the same system necessitates multi-tenant infrastructure to isolate proprietary code for each customer. Furthermore, the customization capability should surface knobs to enable the selection of the appropriate training subset from the internal repository using different metrics (for example, files with a history of fewer bugs or code that is recently committed into the repository). By selecting the code based on these metrics, the customization can be trained using higher-quality code which can improve the quality of code suggestions. Finally, even with continuously evolving code repositories, the cost associated with customization should be minimal to help enterprises realize cost savings from increased developer productivity.
A baseline approach to building customization could be to pretrain the model on a single training corpus composed of of the existing (public) pretraining dataset along with the (private) enterprise code. While this approach works in practice, it requires (redundant) individual pretraining using the public dataset for each enterprise. It also requires redundant deployment costs associated with hosting a customized model for each customer that only serves client requests originating from that customer. By decoupling the training of public and private code and deploying the customization on a multi-tenant system, these redundant costs can be avoided.
How to customize
At a high level, there are two types of possible customization techniques: retrieval-augmented generation (RAG) and fine-tuning (FT).
- Retrieval-augmented generation: RAG finds matching pieces of code within a repository that is similar to a given code fragment (for example, code that immediately precedes the cursor in the IDE) and augments the prompt used to query the LLM with these matched code snippets. This enriches the prompt to help nudge the model into generating more relevant code. There are a few techniques explored in the literature along these lines. See Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks, REALM, kNN-LM and RETRO.
- Fine-tuning: FT takes a pre-trained LLM and trains it further on a specific, smaller codebase (compared to the pretraining dataset) to adapt it for the appropriate repository. Fine-tuning adjusts the LLM’s weights based on this training, making it more tailored to the organization’s unique needs.
Both RAG and fine-tuning are powerful tools for enhancing the performance of LLM-based customization. RAG can quickly adapt to private libraries or APIs with lower training complexity and cost. However, searching and augmenting retrieved code snippets to the prompt increases latency at runtime. Instead, fine-tuning does not require any augmentation of the context because the model is already trained on private libraries and APIs. However, it leads to higher training costs and complexities in serving the model, when multiple custom models have to be supported across multiple enterprise customers. As we discuss later, these concerns can be remedied by optimizing the approach further.
Retrieval augmented generation
There are a few steps involved in RAG:
Indexing
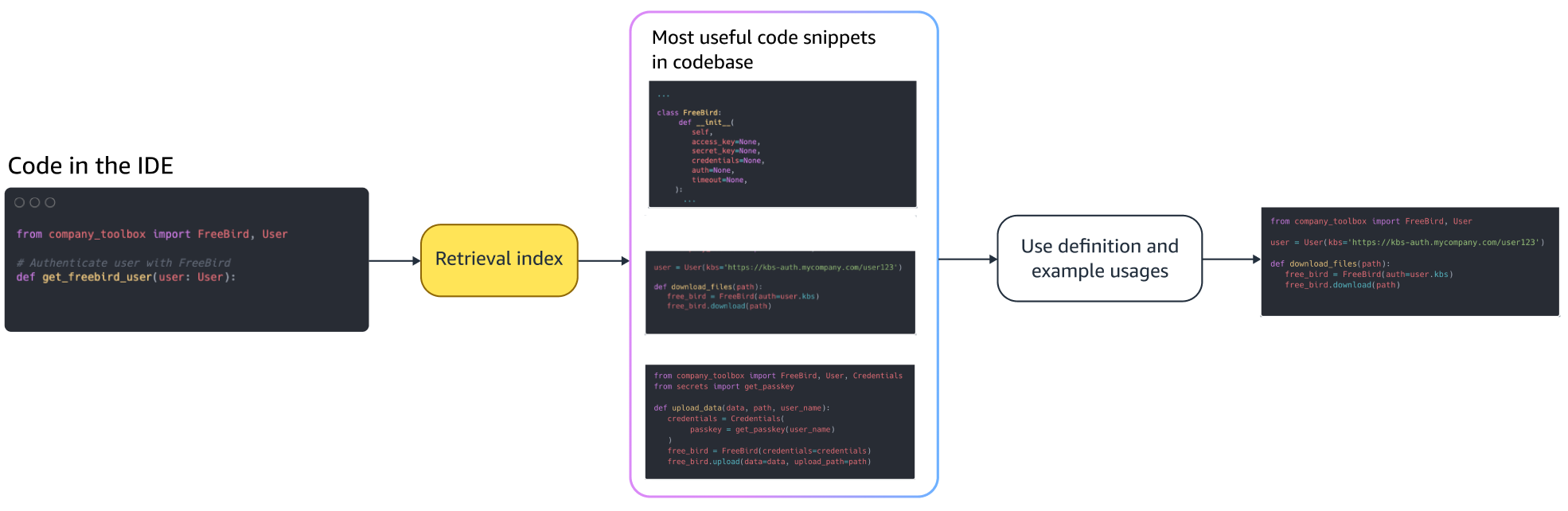
Given a private repository as input by the admin, an index is created by splitting the source code files into chunks. Put simply, chunking turns the code snippets into digestible pieces that are likely to be most informative for the model and are easy to retrieve given the context. The size of a chunk and how it is extracted from a file are design choices that affect the final result. For example, chunks can be split based on lines of code or based on syntactic blocks, and so on.
Administrator Workflow

Contextual search
Search a set of indexed code snippets based on a few lines of code above the cursor and retrieve relevant code snippets. This retrieval can happen using different algorithms. These choices might include:
- Bag of words (BM25) – A bag-of-words retrieval function that ranks a set of code snippets based on the query term frequencies and code snippet lengths.
BM25-based retrieval

The following figure illustrates how BM25 works. In order to use BM25, an inverted index is built first. This is a data structure that maps different terms to the code snippets that those terms occur in. At search time, we look up code snippets based on the terms present in the query and score them based on the frequency.
- Semantic retrieval [Contriever, UniXcoder] – Converts query and indexed code snippets into high-dimensional vectors and ranks code snippets based on semantic similarity. Formally, often k-nearest neighbors (KNN) or approximate nearest neighbor (ANN) search is often used to find other snippets with similar semantics.
Semantic retrieval
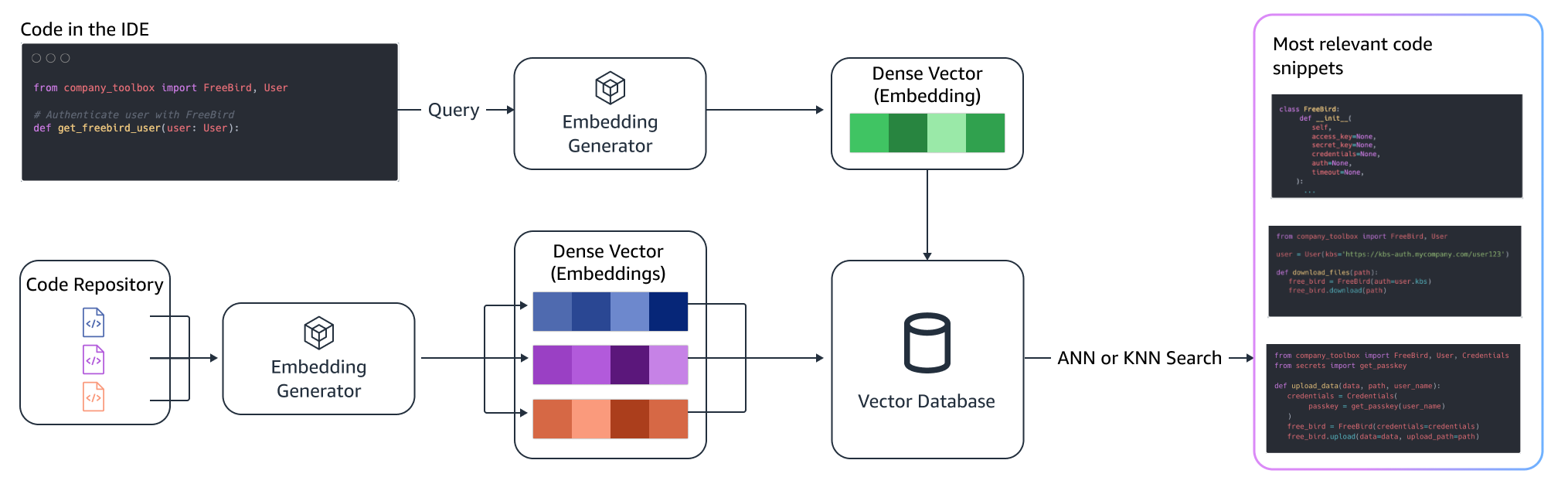
BM25 focuses on lexical matching. Therefore, replacing “add” with “delete” may not change the BM25 score based on the terms in the query, but the retrieved functionality may be the opposite of what is required. In contrast, semantic retrieval focuses on the functionality of the code snippet even though variable and API names may be different. Typically, a combination of BM25 and semantic retrievals can work well together to deliver better results.
Augmented inference
When developers write code, their existing program is used to formulate a query that is sent to the retrieval index. After retrieving multiple code snippets using one of the techniques discussed above, we prepend them to the original prompt. There are many design choices here, including the number of snippets to be retrieved, the relative placement of the snippets in the prompt, and the size of the snippet. The final design choice is primarily driven by empirical observation by exploring various approaches with the underlying language model and plays a key role in determining the accuracy of the approach. The contents from the returned chunks and the original code are combined and sent to the model to get customized code suggestions.
Developer workflow

Fine tuning:
Fine-tuning a language model is done for transfer learning in which the weights of a pre-trained model are trained on new data. The goal is to retain the appropriate knowledge from a model already trained on a large corpus and refine, replace, or add new knowledge from the new corpus — in our case, a new codebase. Simply training on a new codebase leads to catastrophic forgetting. For example, the language model may “forget” its knowledge of safety or the APIs that are sparsely used in the enterprise codebase to date. There are a variety of techniques like experience replay, GEM, and PP-TF that are employed to address this challenge.
Fine tuning
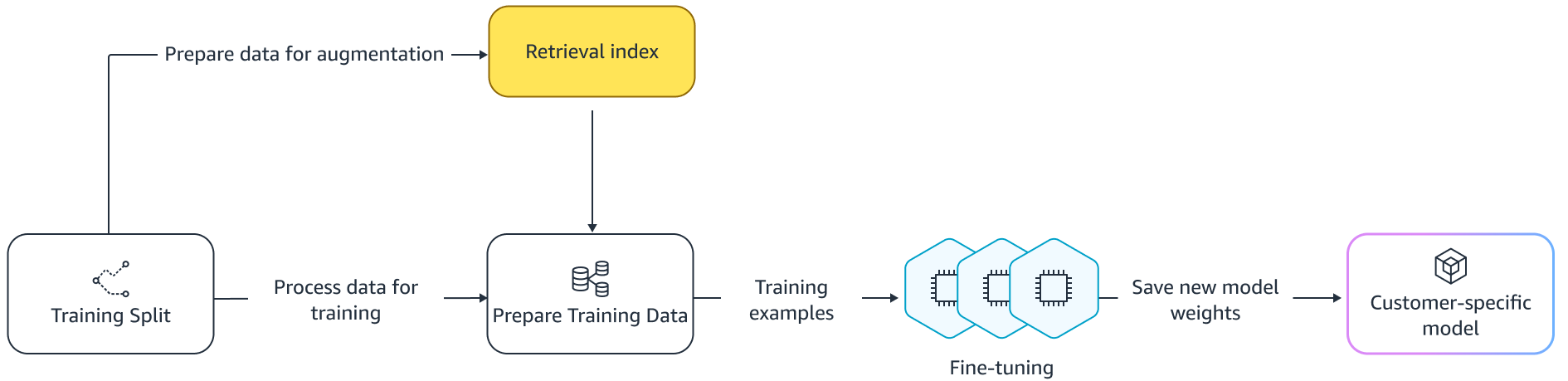
There are two ways of fine-tuning. One approach is to use the additional data without augmenting the prompt to fine-tune the model. Another approach is to augment the prompt during fine-tuning by retrieving relevant code suggestions. This helps improve the model’s ability to provide better suggestions in the presence of retrieved code snippets. The model is then evaluated on a held-out set of examples after it is trained. Subsequently, the customized model is deployed and used for generating the code suggestions.
Despite the advantages of using dedicated LLMs for generating code on private repositories, the costs can be prohibitive for small and medium-sized organizations. This is because dedicated compute resources are necessary even though they may be underutilized given the size of the teams. One way to achieve cost efficiency is serving multiple models on the same compute (for example, SageMaker multi-tenancy). However, language models require one or more dedicated GPUs across multiple zones to handle latency and throughput constraints. Hence, multi-tenancy of full model hosting on each GPU is infeasible.
We can overcome this problem by serving multiple customers on the same compute by using small adapters to the LLM. Parameter-efficient fine-tuning (PEFT) techniques like prompt tuning, prefix tuning, and Low-Rank Adaptation (LoRA) are used to lower training costs without any loss of accuracy. LoRA, especially, has seen great success at achieving similar (or better) accuracy than full-model fine-tuning. The basic idea is to design a low-rank matrix that is then added to the matrices with the original matrix weight of targeted layers of the model. Typically, these adapters are then merged with the original model weights for serving. This leads to the same size and architecture as the original neural network. Keeping the adapters separate, we can serve the same base model with many model adapters. This brings the economies of scale back to our small and medium-sized customers.
Low-Rank Adaptation (LoRA)

Measuring effectiveness of customization
We need evaluation metrics to assess the efficacy of the customized solution. Offline evaluation metrics act as guardrails against shipping customizations that are subpar compared to the default model. By building datasets out of a held-out dataset from within the provided repository, the customization approach can be applied to this dataset to measure effectiveness. Comparing the existing source code with the customized code suggestion quantifies the usefulness of the customization. Common measures used for this quantification include metrics like edit similarity, exact match, and CodeBLEU.
It is also possible to measure usefulness by quantifying how often internal APIs are invoked by the customization and comparing it with the invocations in the pre-existing source. Of course, getting both aspects right is important for a successful completion. For our customization approach, we have designed a tailor-made metric known as Customization Quality Index (CQI), a single user-friendly measure ranging between 1 and 10. The CQI metric shows the usefulness of the suggestions from the customized model compared to code suggestions with a generic public model.
Summary
We built Amazon CodeWhisperer customization capability based on a mixture of the leading technical techniques discussed in this blog post and evaluated it with user studies on developer productivity, conducted by Persistent Systems. In these two studies, commissioned by AWS, developers were asked to create a medical software application in Java that required use of their internal libraries. In the first study, developers without access to CodeWhisperer took (on average) ~8.2 hours to complete the task, while those who used CodeWhisperer (without customization) completed the task 62 percent faster in (on average) ~3.1 hours.
In the second study with a different set of developer cohorts, developers using CodeWhisperer that had been customized using their private codebase completed the task in 2.5 hours on average, 28 percent faster than those who were using CodeWhisperer without customization and completed the task in ~3.5 hours on average. We strongly believe tools like CodeWhisperer that are customized to your codebase have a key role to play in further boosting developer productivity and recommend giving it a run. For more information and to get started, visit the Amazon CodeWhisperer page.
About the authors
 Qing Sun is a Senior Applied Scientist in AWS AI Labs and work on AWS CodeWhisperer, a generative AI-powered coding assistant. Her research interests lie in Natural Language Processing, AI4Code and generative AI. In the past, she had worked on several NLP-based services such as Comprehend Medical, a medical diagnosis system at Amazon Health AI and Machine Translation system at Meta AI. She received her PhD from Virginia Tech in 2017.
Qing Sun is a Senior Applied Scientist in AWS AI Labs and work on AWS CodeWhisperer, a generative AI-powered coding assistant. Her research interests lie in Natural Language Processing, AI4Code and generative AI. In the past, she had worked on several NLP-based services such as Comprehend Medical, a medical diagnosis system at Amazon Health AI and Machine Translation system at Meta AI. She received her PhD from Virginia Tech in 2017.
 Arash Farahani is an Applied Scientist with Amazon CodeWhisperer. His current interests are in generative AI, search, and personalization. Arash is passionate about building solutions that resolve developer pain points. He has worked on multiple features within CodeWhisperer, and introduced NLP solutions into various internal workstreams that touch all Amazon developers. He received his PhD from University of Illinois at Urbana-Champaign in 2017.
Arash Farahani is an Applied Scientist with Amazon CodeWhisperer. His current interests are in generative AI, search, and personalization. Arash is passionate about building solutions that resolve developer pain points. He has worked on multiple features within CodeWhisperer, and introduced NLP solutions into various internal workstreams that touch all Amazon developers. He received his PhD from University of Illinois at Urbana-Champaign in 2017.
 Xiaofei Ma is an Applied Science Manager in AWS AI Labs. He joined Amazon in 2016 as an Applied Scientist within SCOT organization and then later AWS AI Labs in 2018 working on Amazon Kendra. Xiaofei has been serving as the science manager for several services including Kendra, Contact Lens, and most recently CodeWhisperer and CodeGuru Security. His research interests lie in the area of AI4Code and Natural Language Processing. He received his PhD from University of Maryland, College Park in 2010.
Xiaofei Ma is an Applied Science Manager in AWS AI Labs. He joined Amazon in 2016 as an Applied Scientist within SCOT organization and then later AWS AI Labs in 2018 working on Amazon Kendra. Xiaofei has been serving as the science manager for several services including Kendra, Contact Lens, and most recently CodeWhisperer and CodeGuru Security. His research interests lie in the area of AI4Code and Natural Language Processing. He received his PhD from University of Maryland, College Park in 2010.
 Murali Krishna Ramanathan is a Principal Applied Scientist in AWS AI Labs and co-leads AWS CodeWhisperer, a generative AI-powered coding companion. He is passionate about building software tools and workflows that help improve developer productivity. In the past, he built Piranha, an automated refactoring tool to delete code due to stale feature flags and led code quality initiatives at Uber engineering. He is a recipient of the Google faculty award (2015), ACM SIGSOFT Distinguished paper award (ISSTA 2016) and Maurice Halstead award (Purdue 2006). He received his PhD in Computer Science from Purdue University in 2008.
Murali Krishna Ramanathan is a Principal Applied Scientist in AWS AI Labs and co-leads AWS CodeWhisperer, a generative AI-powered coding companion. He is passionate about building software tools and workflows that help improve developer productivity. In the past, he built Piranha, an automated refactoring tool to delete code due to stale feature flags and led code quality initiatives at Uber engineering. He is a recipient of the Google faculty award (2015), ACM SIGSOFT Distinguished paper award (ISSTA 2016) and Maurice Halstead award (Purdue 2006). He received his PhD in Computer Science from Purdue University in 2008.
 Ramesh Nallapati is a Senior Principal Applied Scientist in AWS AI Labs and co-leads CodeWhisperer, a generative AI-powered coding companion, and Titan Large Language Models at AWS. His interests are mainly in the areas of Natural Language Processing and Generative AI. In the past, Ramesh has provided science leadership in delivering many NLP-based AWS products such as Kendra, Quicksight Q and Contact Lens. He held research positions at Stanford, CMU and IBM Research, and received his Ph.D. in Computer Science from University of Massachusetts Amherst in 2006.
Ramesh Nallapati is a Senior Principal Applied Scientist in AWS AI Labs and co-leads CodeWhisperer, a generative AI-powered coding companion, and Titan Large Language Models at AWS. His interests are mainly in the areas of Natural Language Processing and Generative AI. In the past, Ramesh has provided science leadership in delivering many NLP-based AWS products such as Kendra, Quicksight Q and Contact Lens. He held research positions at Stanford, CMU and IBM Research, and received his Ph.D. in Computer Science from University of Massachusetts Amherst in 2006.