Artificial Intelligence
Deploy shadow ML models in Amazon SageMaker
Amazon SageMaker helps data scientists and developers prepare, build, train, and deploy high-quality machine learning (ML) models quickly by bringing together a broad set of capabilities purpose-built for ML. SageMaker accelerates innovation within your organization by providing purpose-built tools for every step of ML development, including labeling, data preparation, feature engineering, statistical bias detection, AutoML, training, tuning, hosting, explainability, monitoring, and workflow automation.
You can use a variety of techniques to deploy new ML models to production, so choosing the right strategy is an important decision. You must weigh the options in terms of the impact of change on the system and on the end users. In this post, we show you how to deploy using a shadow deployment strategy.
Shadow deployment
Shadow deployment consists of releasing version B alongside version A, fork version A’s incoming requests, and send them to version B without impacting production traffic. This is particularly useful to test production load on a new feature and measure model performance on a new version without impacting current live traffic.
A rollout of the application is triggered when stability and performance meet the requirements.
Shadow deployment has the following advantages:
- You can evaluate model performance without impacting production traffic or workload.
- There is no impact on the customer or production workload behavior. You can explore synchronous as well as asynchronous approaches.
- You can check to see if the stability and performance of the application meets your requirements, which reduce risk.
However, shadow deployment brings the following challenges:
- Increased cost due to additional resources needed to support the new model version in parallel with the current live model.
- Increased complexity to set up over deployment strategies, such as update in place.
- You have to carefully design and implement performance testing. Performance testing could include the system performance (load testing, latency, and so on) and model performance (model metrics comparison).
Solution overview
In this post, we look at three different options for deploying models using a shadow deployment strategy:
- An offline approach using Amazon SageMaker Model Monitor data capture enabled on model version 1 to capture the request and response. Then we use a batch transform to invoke model version 2 and perform a comparison and analysis against version 1.
- A synchronous approach in which we perform shadow deployment for real-time inferences for ML models using AWS services such as Amazon API Gateway, AWS Lambda, and SageMaker.
- An extension of the synchronous approach, the difference being that model version 2 is invoked asynchronously.
Deploy models with an offline approach
In this section, we explore the offline process, as shown in the following diagram.
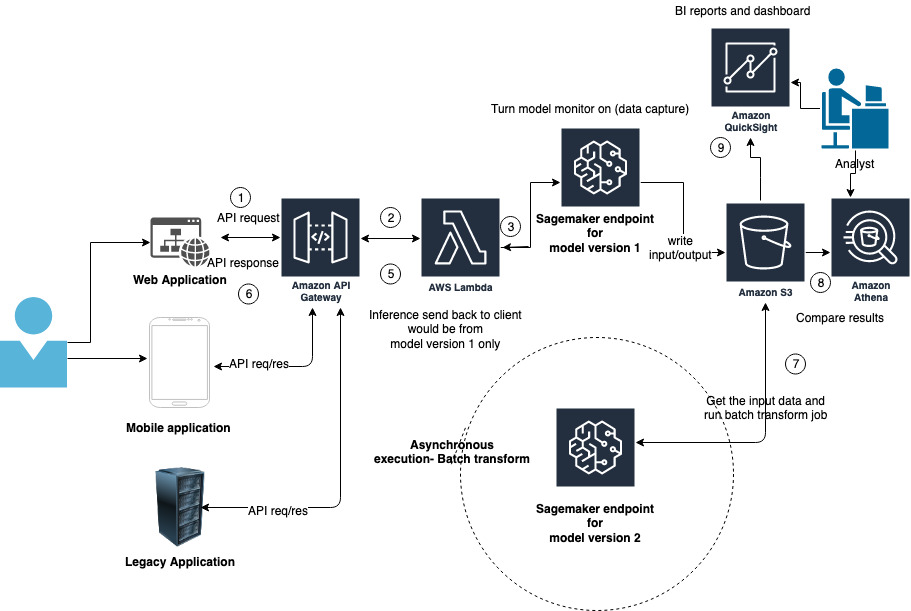
In this option, we use the data capture utility in Model Monitor. Model Monitor continuously monitors the quality of SageMaker ML models in production. With Model Monitor, you can set alerts that notify you when deviations in model quality occur. Early and proactive detection of these deviations enables you to take corrective actions, such as retraining models, auditing upstream systems, or fixing quality issues without having to monitor models manually or build additional tooling.
For shadow deployment, we enable data capture and turn on Model Monitor for a real-time inference endpoint for model version 1 to capture data from requests and responses. Then we store the captured data in an Amazon Simple Storage Service (Amazon S3) bucket. We use the file that data capture generates (input data) and batch transform to get inference for model version 2. Optionally, we can use Amazon Athena and Amazon QuickSight to prepare a dashboard and gain insights from the inferences or simply run a hash compare between the two inference data outputs to show the differences.
You can find the complete example on GitHub.
Deploy models with a synchronous approach
We now dive deep and demonstrate how to perform shadow deployment for real-time inferences with an ML model using AWS services such as API Gateway, Lambda, and SageMaker.
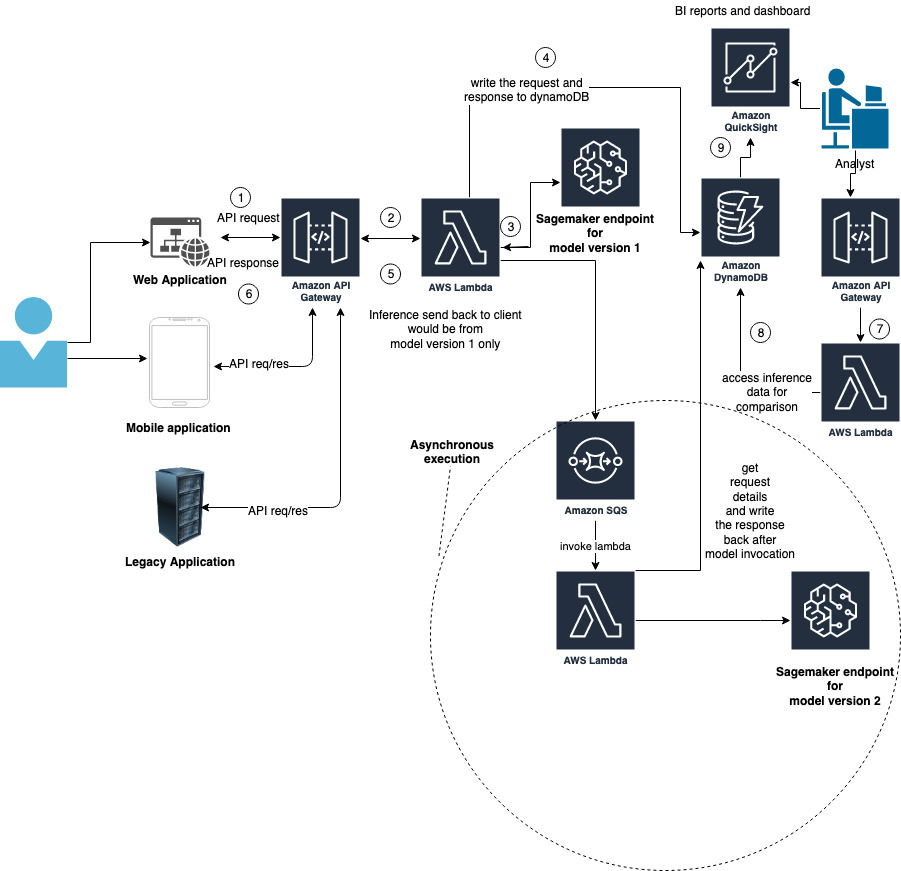
The following diagram shows our proposed architecture.
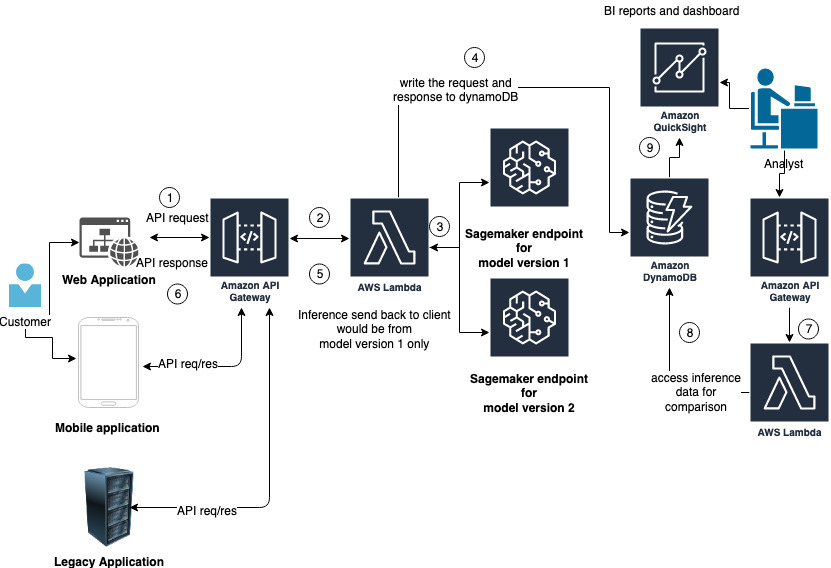
The architecture includes the following components:
- A customer calls an API to get inference. This could be through a web application, mobile application, or even a legacy on-premises application.
- This API is hosted in API Gateway, and calls a Lambda function on the backend.
- The Lambda function calls two SageMaker endpoints: one for each version model.
- The request and response from both the endpoints are written to DyanomoDB for future comparison and analysis.
- The inference from the model 1 endpoint is responded back to the API.
- The API response is sent to the client who invoked the API.
Now that we have talked about the customer experience, let’s talk about the analysis and comparison.
- We set up a DynamoDB viewer to see the inference from both model endpoints.
- This is via an API hosted in API Gateway, which calls a Lambda function on the backend. The function gets the records from DynamoDB, which includes the request and the responses from both endpoints.
- Optionally, you can use QuickSight to prepare a dashboard and gain insights from the inferences and other supporting data sources like customer data, request types, and business domain details. This isn’t incorporated in the AWS Cloud Development Kit (AWS CDK) setup but can easily be added.
In our example, we use a binary classification ML problem in which we predict if the data input is cancerous or not (malignant or benign). You can extend this architecture and concept to your own ML problem in a similar manner.
Prerequisites
To implement this solution, install the AWS CDK on your device. For instructions, see Working with the AWS CDK in Python.
Set up the solution
Complete the following steps:
- Clone the project to your device:
- Navigate to the project root directory and create your virtual environment:
- Activate the environment:
- Install the dependent packages:
- Verify the setup:
This should generate an AWS CloudFormation template.
- Create a notebook instance in SageMaker.
- Upload the notebook from the Git project.

- Run the notebook to build, train, and deploy your model versions.
- Make sure to comment out the last cell in the notebook, which deletes the endpoint.

- Then you can choose Run All on the cell.

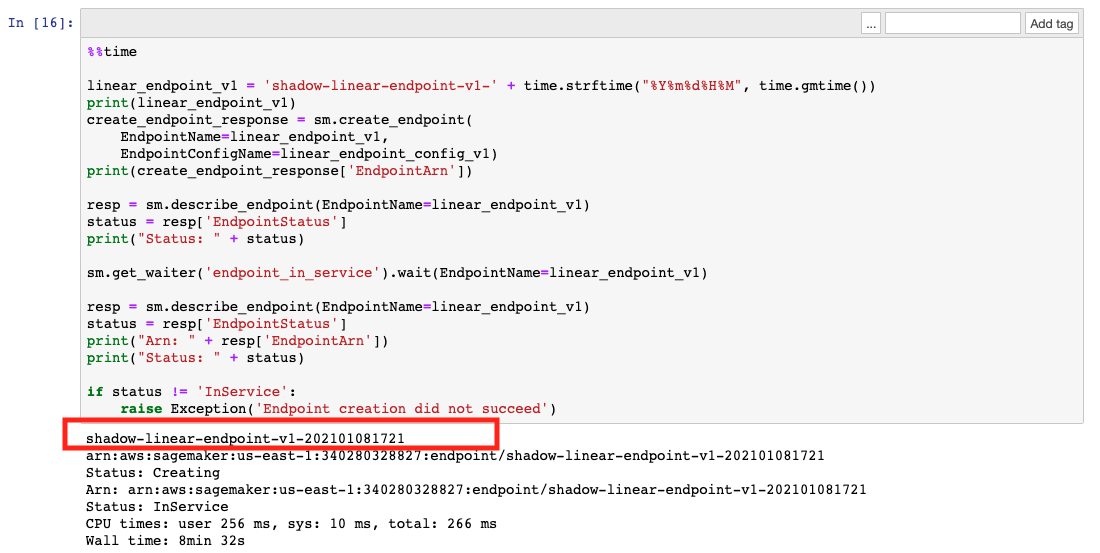
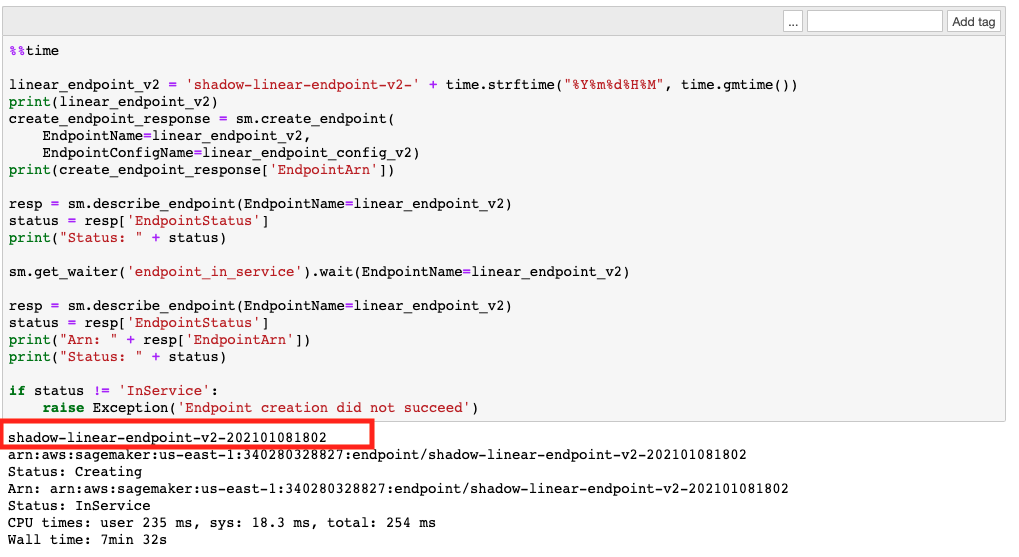
This fetches and sets up the data, and performs training with two sets of hyperparameters, which results in two different models (cell 8 and cell 9 in the notebook). We host these two different models in two different endpoints.
- Note the version 1 endpoint from your notebook.
- Note the version 2 endpoint from your notebook.
- Deploy the CloudFormation stack after changing the parameters to your deployed model versions:
Replace the endpoint with the correct endpoint per your notebook output. Optionally, if you already have an endpoint deployed, you can use that.
In our example, we use the following code:
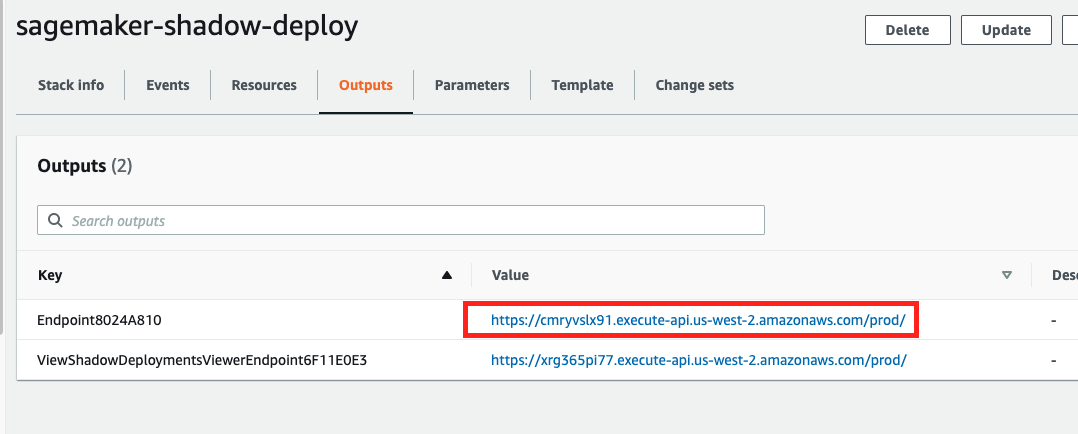
- After the stack is successfully deployed, go to the Outputs tab for the stack to get the endpoint (or copy it from the terminal).
Test the solution
The following stack output shows two endpoint URLs:

Use the URL sagemaker-shadow-deploy.ViewShadowDeploymentsViewerEndpointxxx in your browser to see the model inference results.
For more details, see the GitHub repository.
Expand on the asynchronous approach
Another asynchronous approach is shown in the following diagram. Instead of invoking the second model endpoint in the same Lambda function, you can put a message in an Amazon Simple Queue Service (Amazon SQS) queue with the request ID. The queue triggers a Lambda function that fetches the request details and payload from the DynamoDB table and invokes the second model endpoint. The function also logs the response in the DynamoDB table, thereby closing the loop for the request.
Conclusion
You can follow this simple architecture using AWS services to host shadow deployment. If your model isn’t in AWS, you can import it in SageMaker and host the endpoint. Depending on your business use case, you can use a synchronous or asynchronous approach for shadow deployment. We took a classification business problem and built two different models, and demonstrated how to perform shadow deployment using AWS services. Visit the GitHub sample project and try out the shadow deployment approach for your model.
About the Authors
 Ram Vittal is an enterprise solutions architect at AWS. Ram has been helping customers solve challenges across several areas such as security, governance, big data, and machine learning. He has delivered thought leadership on big data, machine learning, and cloud strategies. Ram holds professional and specialty AWS Certifications and has a master’s degree in Computer Engineering. In his spare time, he enjoys tennis and photography.
Ram Vittal is an enterprise solutions architect at AWS. Ram has been helping customers solve challenges across several areas such as security, governance, big data, and machine learning. He has delivered thought leadership on big data, machine learning, and cloud strategies. Ram holds professional and specialty AWS Certifications and has a master’s degree in Computer Engineering. In his spare time, he enjoys tennis and photography.
 Neelam Koshiya is an enterprise solutions architect at AWS. Her current focus is to help enterprise customers with their cloud adoption journey for strategic business outcomes. In her spare time, she enjoys reading and being outdoors.
Neelam Koshiya is an enterprise solutions architect at AWS. Her current focus is to help enterprise customers with their cloud adoption journey for strategic business outcomes. In her spare time, she enjoys reading and being outdoors.
 Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.
Raghu Ramesha is a Software Development Engineer (AI/ML) with the Amazon SageMaker Services SA team. He focuses on helping customers migrate ML production workloads to SageMaker at scale. He specializes in machine learning, AI, and computer vision domains, and holds a master’s degree in Computer Science from UT Dallas. In his free time, he enjoys traveling and photography.