Artificial Intelligence
How to Deploy Deep Learning Models with AWS Lambda and Tensorflow
Deep learning has revolutionized how we process and handle real-world data. There are many types of deep learning applications, including applications to organize a user’s photo archive, make book recommendations, detect fraudulent behavior, and perceive the world around an autonomous vehicle.
In this post, we’ll show you step-by-step how to use your own custom-trained models with AWS Lambda to leverage a simplified serverless computing approach at scale. During this process, we’ll introduce you to some of the core AWS services that you can use to run your inference using serverless.
We’ll look at image classification: There are many high-performing open source models available. Image classification allows us to use two of the most commonly used network types in deep learning: Convolutional Neural Networks and Fully-Connected Neural Networks (also called Vanilla Neural Networks).
We’ll show you where to place your trained model in AWS and how to package your code in a manner that AWS Lambda can execute on inference command.
We discuss the following AWS services in this blog post: AWS Lambda, Amazon Simple Storage Service (S3), AWS CloudFormation, Amazon CloudWatch and AWS Identity and Access Management (IAM). Languages and deep learning frameworks used include Python and TensorFlow. The processes described here can be applied using any other deep learning frameworks, such as MXNet, Caffe, PyTorch, CNTK, and others.
Overall Architecture
AWS Architecture
From a process perspective, the development and deployment of deep learning systems should not be different than developing and deploying traditional software solutions.
The following diagram depicts one possible development life cycle:
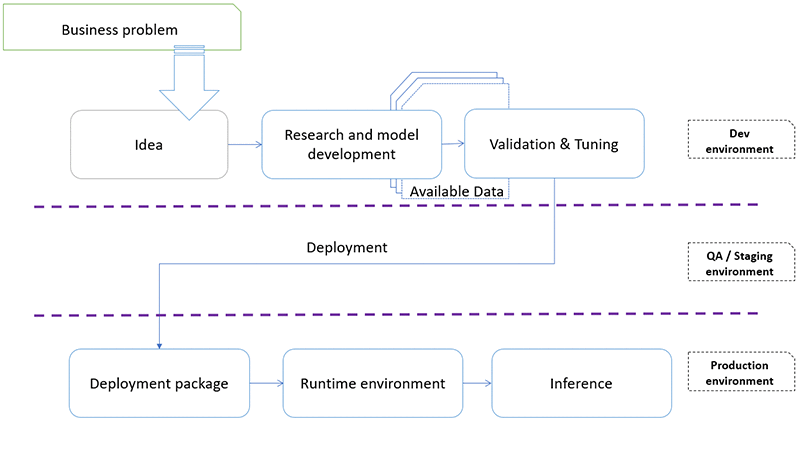
As you can see from the diagram, the usual software development processes go through multiple stages, from idea inception and modeling in a development environment to final deployment of models in production. In most cases, the development phase has many quick iterations that require constant changes to the environment. Usually, this would impact the nature and quantity of resources used during software/model development. Having the ability to quickly build/rebuild/tear down the environment is essential for agile development. Rapid changes in the software that is built should be followed by infrastructure adjustments. One of the pre-requisites for agile development and accelerated innovation is the ability to manage infrastructure via code (known as IaC: infrastructure as code).
The automation of software design management, building, and deployment is part of Continuous Integration and Continuous Delivery (CI/CD). While this post is not going to dive into the details of well-orchestrated CI/CD pipelines, it should be on the mind of any devops team that wants to build repeatable processes that foster development/deployment agility and process automation.
AWS brings many services and practices to the community that simplify the development tasks. Whenever an environment gets built using automation code, it can be easily involved and replicated in a matter of minutes, for example, for building staging and production systems from the template used for the development environment.
Further, AWS significantly simplifies the design of complex solutions using a number of computer science and software engineering concepts via fully-managed services including streaming, batching, queueing, monitoring and alerting, real-time event driven systems, serverless computing, and many more. For this post, we’ll explore the world of serverless computing for deep learning, which helps you avoid heavy-lifting tasks such as server provisioning and management. These tasks will be done by AWS services, shielding data scientists and software developers from unnecessary complexities like making sure to have enough computing capacity, making sure to retry upon system failures, etc.
For this post, we’ll focus on a staging-like environment that mimics a production system.
Amazon S3-based use case
For this use case, we’ll simulate the process of an image being stored in an Amazon Simple Storage Service (S3) bucket. An S3 bucket, where objects reside, has the capability to notify the rest of the AWS Cloud ecosystem about an object PUT event. In most cases, either an Amazon Simple Notification Service (SNS) notification mechanism is used or user code placed inside an AWS Lambda function is automatically triggered. For simplicity’s sake, we’ll use a Lambda function trigger on an S3 object PUT event. As you may have noticed, we are dealing with some very sophisticated concepts, with very little actually being done by a scientist/developer.
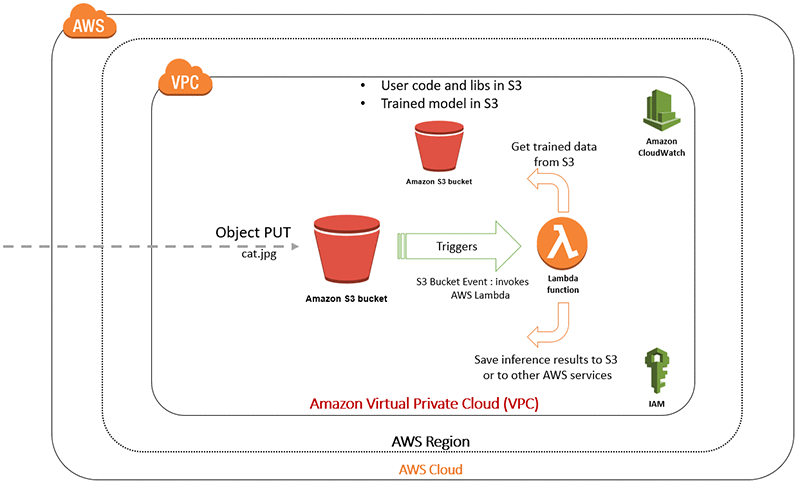
Our trained machine learning model, developed in Python TensorFlow, resides in an S3 bucket. For our simulation, we’ll upload a cat image to an arbitrary bucket that has bucket event notifications turned on. Our Lambda function will be subscribed to these S3 bucket notification events.
For this post, all cloud infrastructure will be built using AWS CloudFormation, which provides a fast and flexible interface to create and launch AWS services. This can also be done manually using the AWS Management Console or using an AWS Command Line Interface (AWS CLI), as another method for designing and launching AWS resources.
Deep learning code
Nowadays, an easy and efficient way to allow the rapid development of AI-based systems is to take existing models and fine-tune them for your use case, especially with state-of-the-art models available publicly.
Let’s look at deploying a powerful pre-trained Inception-v3 model for image classification.
Inception-v3 Architecture

The Inception-v3 architecture shown here indicates layer types using color. It isn’t important that you understand each and every part of the model. It is important, however, to realize that this is a truly deep network that would require prohibitive amounts of time and resources (data and compute) to train from scratch.
We can leverage TensorFlow’s Image Recognition tutorial to download a pre-trained Inception-v3 model.
First, create a Python 2.7 virtualenv or an Anaconda environment and install TensorFlow for CPU (we will not need GPUs at all).
Locate the classify_image.py in the root of the zip file provided with this blog post (DeepLearningAndAI-Bundle.zip) and execute in your shell:
This will download a pre-trained Inception-v3 model and run it on an example image (of a panda), which verifies the implementation is correct.
This creates a directory structure similar to the following:
Now, one would have to take this model file, all the necessary compiled Python packages, and create a bundle that AWS Lambda can execute. To simplify these steps, we are providing all the necessary binaries for your convenience. You can follow the below steps to have the demo up and running in a few minutes.
As a part of the demo bundle, we are providing a large model file. Since the file is quite large (> 90 MB), we will need to load it during AWS Lambda inference execution from Amazon S3. Looking at the provided inference code (classify_image.py), you may have noticed that we placed model downloading outside of the handler function. We do this to take advantage of AWS Lambda container reuse. Any code executed outside of the handler method will be invoked only once upon container creation and kept in memory across calls to the same Lambda container, making subsequent calls to Lambda faster.
An AWS Lambda pre-warming action is when you proactively initiate AWS Lambda before your first production run. This helps you avoid a potential issue with an AWS Lambda “cold start,” in which large models need to be loaded from S3 on every “cold” Lambda instantiation. After AWS Lambda is operational, it is beneficial to keep it warm in order to assure a fast response for the next inference run. As long AWS Lambda is activated once in a few minutes, even if done using some type of a ping notification, it will keep it warm when Lambda needs to run inference task.
Now, we need to zip the code and all necessary packages together. Normally, you have to compile all necessary packages on an Amazon Linux EC2 instance before using them with AWS Lambda. (This is described in http://docs.aws.amazon.com/lambda/latest/dg/lambda-python-how-to-create-deployment-package.html). However, in this blog post we provide compiled files, as well as a complete deeplearning-bundle.zip file that contains all of the code described earlier and necessary packages that are ready to use with AWS Lambda.
Deploying with AWS Lambda
Here are the main steps to get you started:
- Download the DeepLearningAndAI-Bundle.zip.
- Unzip and copy the files into your Amazon S3 bucket. We’ll call this dl-model-bucket. This folder will contain everything you need to run this demo, such as:
- classify_image.py
- classify_image_graph_def.pb
- deeplearning-bundle.zip
- DeepLearning_Serverless_CF.json
- cat-pexels-photo-126407.jpeg (royalty free image for testing)
- dog-pexels-photo-59523.jpeg (royalty free image for testing)
- Run a CloudFormation script to create all necessary resources in AWS, including your test S3 bucket, let’s call it deeplearning-test-bucket (you might need to use some other name if this bucket name is taken). Step-by-step instructions are below.
- Upload an image to your test bucket.
- Go to Amazon Cloud Watch Logs for your Lambda inference function and validate inference results.
Here is a step-by-step guide to run the CloudFormation script:
- Go to the AWS CloudFormation console and choose the Create new stack button.
- At the ‘Specify an Amazon S3 template URL’ provide the link to the CloudFormation script (json). Choose Next.
- Enter the required values for the CloudFormation Stack name, test bucket name (where you will upload your images for recognition, we called it deeplearning-test-bucket), and the bucket where you have the model and the code.

- Choose Next. Skip the Options page. Go to the Review page. At the bottom of the page, you should accept the acknowledgment. Choose the Create button. You should see a CREATE_IN_PROGRESS status and shortly after, you will see a CREATE_COMPLETE status.

At this point, the CloudFormation script has built the entire solution, including the AWS Identity and Access Management (IAM) role, DeepLearning Inference Lambda function, and permissions for the S3 bucket to trigger our Lambda function when the object is PUT into the test bucket.
Looking at the AWS Lambda service, you’ll see the new DeepLearning_Lambda function. AWS CloudFormation has fully-configured all the necessary parameters and has added the necessary environment variables used during inference.
A new test bucket should have been created. In order to test our deep learning inference capabilities, upload an image to the previously created S3 bucket: deeplearning-test-bucket.
Getting inference results
To execute the code you’ve written, just upload any image to the Amazon S3 bucket created by the CloudFormation script. This action would trigger our inference Lambda function.
The following is an example where we upload a test image to our test bucket.
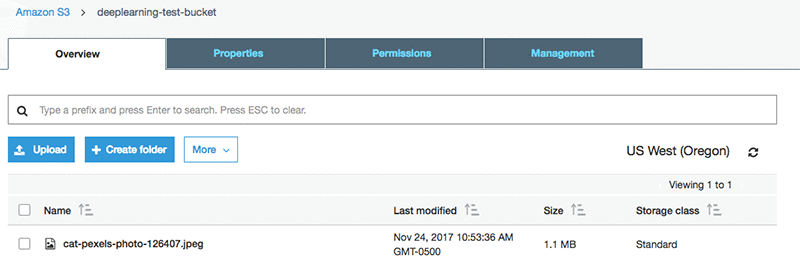
At this point, the S3 bucket has triggered our inference Lambda function. For this blog post, we’ll head to CloudWatch Logs to view the inference outcome. In the console, at the AWS Lambda service screen, choose Monitoring, and then choose View Logs. Note that when you actually work with inference results, they should be stored in one of our persistence stores, such as Amazon DynamoDB or Amazon OpenSearch Service, where you can easily index images and associated labels.

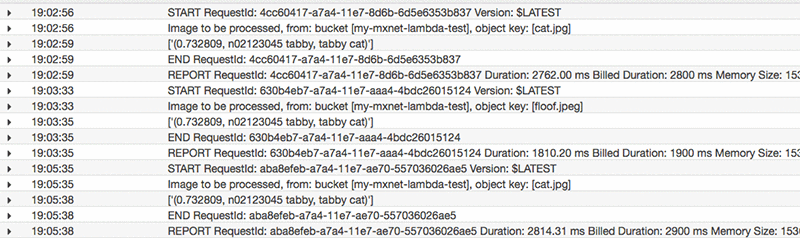
In this log, you can see the model loading that is done during Lambda container construction. In subsequent calls, as long as the container is still “warm,” only inference will occur (the model is already in memory), reducing total runtime. The following screenshot shows subsequent Lambda function executions.
Tips for deep learning in a serverless environment
Using a serverless environment provides a number of opportunities for simplifying the deployment of your development and production code. Steps for packaging your code and its dependencies vary between runtime environments, so learn them well to avoid issues during first-time deployment. Python is very popular language for data scientists building machine learning models. To maximize performance while running on AWS Lambda, Python libraries relying on legacy C and Fortran should be built and installed on Amazon Elastic Compute Cloud (EC2) using an Amazon Linux Amazon Machine Image (AMI) (whose built files can then be exported). In this blog post, we have done this already. Feel free to leverage those libraries to build your final deployment package. Further, pre-compiled Lambda bundles can frequently be found online, for example at https://github.com/ryfeus/lambda-packs.
Model training usually requires intensive calculations and use of expensive GPUs in dedicated hardware. Thankfully, inference is much less computationally intensive than training, allowing for the use of CPUs and the leveraging of the Lambda serverless computational model. If you do require GPU for your inference, you can consider using containers services such as Amazon ECS or Kubernetes, which can give you more control on your inference environment. For more details, see this post: https://aws.amazon.com/blogs/ai/deploy-deep-learning-models-on-amazon-ecs/ .
As you migrate to serverless architectures more and more for your project, you’ll soon learn about the opportunities and challenges that come with this method of computing:
- Serverless significantly simplifies usage of compute infrastructure, avoiding the complexity of managing a VPC, subnets, security, building and deploying Amazon EC2 servers, and so on.
- AWS handles capacity for you.
- Cost effective – you are charged only when you use compute resources in 100ms increments.
- Exception handling – AWS handles retries and storing problematic data/messages in Amazon SQS/Amazon SNS for later processing.
- All logs are collected and stored within Amazon CloudWatch Logs.
- Performance can be monitored using the AWS X-Ray tool.
If you are planning to process larger files/objects, make sure to use an input stream approach instead of loading the entire content in memory. In our work, we often process very large files (even over 20 GB) with an AWS Lambda function utilizing traditional file/object streaming approaches. To improve network I/O, make sure to use compression as it will significantly reduce file/object size in most cases (especially with CSV and JSON encoding).
Although this blog post uses the Inception-v3 model (with a maximum memory usage of ~400 MiB), lower memory options are available such as MobileNets and SqueezeNet. If you want to explore other models or have compute/memory/accuracy constraints, a very good analysis of different models can be found in Canziani et al. This analysis is actually the reason we focused on Inception-v3 in this post. We believe it provides an excellent tradeoff between accuracy, compute requirements, and memory usage.
Debugging a Lambda function is not the same as debugging in a traditional local host/laptop-based development. Instead, we suggest that you create your local host code (which should be easy to debug) before you finally promote it to a Lambda function. Only a few small changes are needed to switch from a laptop environment to AWS Lambda, such as:
- Replacing the use of local file references – replace them with, for example, an S3 object.
- Reading environment variables – these can be abstracted to have the same logic.
- Printing to console – you can still use your print functions but they will be redirected to CloudWatch Logs and you will see them within a few seconds.
- Debugging – A debugger is not possible for AWS Lambda, but as stated before, use all of your tools for developing on the host and deploy the result only when you have it properly running on your host environment.
- Runtime instrumentation – enable the AWS X-Ray service to be able to gain insights into the runtime data to identify issues and find the optimization opportunities.
Deploying to AWS Lambda is trivial once you have your code and dependencies in a single ZIP file. CI/CD tools, like the ones that we mentioned at the beginning of this post, can make this step simpler and, more importantly, fully-automated. Any time there are code changes detected, a CI/CD pipeline will automatically build and deploy the result to the requested environment quickly, as per your configuration. In addition, AWS Lambda supports versioning and aliasing, which let you quickly switch between different variations of your Lambda function. This could be beneficial when you work between different environments, such as research, development, staging and production. Once you publish a version, it is immutable, avoiding undesirable changes to your code.
Conclusion
In summary, this post covers deep learning with your own custom-trained models at scale in a serverless environment with AWS Lambda.
Additional Readings
- Amazon SageMaker – Accelerating Machine Learning
- Seamlessly Scale Predictions with AWS Lambda and MXNet
- Updated AWS Deep Learning AMIs: New Versions of TensorFlow, Apache MXNet, Keras, and PyTorch
About the Authors
 Boris Ivanovic is a Master’s of Computer Science student at Stanford University, specializing in artificial intelligence. He was a Prime Air SDE Intern during the summer of 2017, working to safely get packages to customers in 30 minutes or less using unmanned aerial vehicles.
Boris Ivanovic is a Master’s of Computer Science student at Stanford University, specializing in artificial intelligence. He was a Prime Air SDE Intern during the summer of 2017, working to safely get packages to customers in 30 minutes or less using unmanned aerial vehicles.
 Zoran Ivanovic is a Big Data Principal Consultant with AWS Professional Services in Canada. After 5 years of experience leading one of the largest big data teams in Amazon, he moved to AWS to share his experience with larger enterprise customers who are interested in leveraging AWS services to build their mission-critical systems in the cloud.
Zoran Ivanovic is a Big Data Principal Consultant with AWS Professional Services in Canada. After 5 years of experience leading one of the largest big data teams in Amazon, he moved to AWS to share his experience with larger enterprise customers who are interested in leveraging AWS services to build their mission-critical systems in the cloud.