Artificial Intelligence
Improve transcription accuracy of customer-agent calls with custom vocabulary in Amazon Transcribe
Many AWS customers have been successfully using Amazon Transcribe to accurately, efficiently, and automatically convert their customer audio conversations to text, and extract actionable insights from them. These insights can help you continuously enhance the processes and products that directly improve the quality and experience for your customers.
In many countries, such as India, English is not the primary language of communication. Indian customer conversations contain regional languages like Hindi, with English words and phrases spoken randomly throughout the calls. In the source media files, there can be proper nouns, domain-specific acronyms, words, or phrases that the default Amazon Transcribe model isn’t aware of. Transcriptions for such media files can have inaccurate spellings for those words.
In this post, we demonstrate how you can provide more information to Amazon Transcribe with custom vocabularies to update the way Amazon Transcribe handles transcription of your audio files with business-specific terminology. We show the steps to improve the accuracy of transcriptions for Hinglish calls (Indian Hindi calls containing Indian English words and phrases). You can use the same process to transcribe audio calls with any language supported by Amazon Transcribe. After you create custom vocabularies, you can transcribe audio calls with accuracy and at scale by using our post call analytics solution, which we discuss more later in this post.
Solution overview
We use the following Indian Hindi audio call (SampleAudio.wav) with random English words to demonstrate the process.
We then walk you through the following high-level steps:
- Transcribe the audio file using the default Amazon Transcribe Hindi model.
- Measure model accuracy.
- Train the model with custom vocabulary.
- Measure the accuracy of the trained model.
Prerequisites
Before we get started, we need to confirm that the input audio file meets the transcribe data input requirements.
A monophonic recording, also referred to as mono, contains one audio signal, in which all the audio elements of the agent and the customer are combined into one channel. A stereophonic recording, also referred to as stereo, contains two audio signals to capture the audio elements of the agent and the customer in two separate channels. Each agent-customer recording file contains two audio channels, one for the agent and one for the customer.
Low-fidelity audio recordings, such as telephone recordings, typically use 8,000 Hz sample rates. Amazon Transcribe supports processing mono recorded and also high-fidelity audio files with sample rates between 16,000–48,000 Hz.
For improved transcription results and to clearly distinguish the words spoken by the agent and the customer, we recommend using audio files recorded at 8,000 Hz sample rate and are stereo channel separated.
You can use a tool like ffmpeg to validate your input audio files from the command line:
In the returned response, check the line starting with Stream in the Input section, and confirm that the audio files are 8,000 Hz and stereo channel separated:
When you build a pipeline to process a large number of audio files, you can automate this step to filter files that don’t meet the requirements.
As an additional prerequisite step, create an Amazon Simple Storage Service (Amazon S3) bucket to host the audio files to be transcribed. For instructions, refer to Create your first S3 bucket.Then upload the audio file to the S3 bucket.
Transcribe the audio file with the default model
Now we can start an Amazon Transcribe call analytics job using the audio file we uploaded.In this example, we use the AWS Management Console to transcribe the audio file.You can also use the AWS Command Line Interface (AWS CLI) or AWS SDK.
- On the Amazon Transcribe console, choose Call analytics in the navigation pane.
- Choose Call analytics jobs.
- Choose Create job.

- For Name, enter a name.
- For Language settings, select Specific language.
- For Language, choose Hindi, IN (hi-IN).
- For Model type, select General model.
- For Input file location on S3, browse to the S3 bucket containing the uploaded audio file.
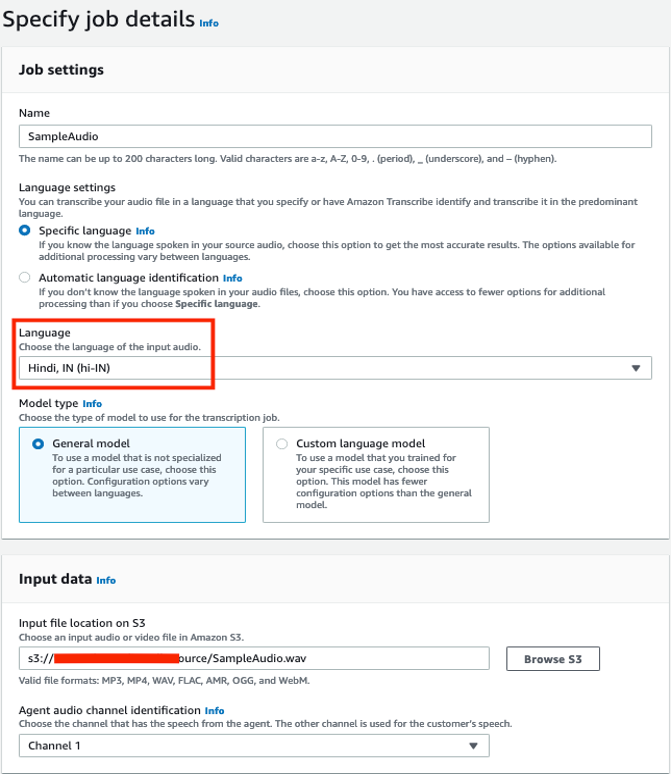
- In the Output data section, leave the defaults.
- In the Access permissions section, select Create an IAM role.
- Create a new AWS Identity and Access Management (IAM) role named HindiTranscription that provides Amazon Transcribe service permissions to read the audio files from the S3 bucket and use the AWS Key Management Service (AWS KMS) key to decrypt.

- In the Configure job section, leave the defaults, including Custom vocabulary deselected.
- Choose Create job to transcribe the audio file.

When the status of the job is Complete, you can review the transcription by choosing the job (SampleAudio).

The customer and the agent sentences are clearly separated out, which helps us identify whether the customer or the agent spoke any specific words or phrases.
Measure model accuracy
Word error rate (WER) is the recommended and most commonly used metric for evaluating the accuracy of Automatic Speech Recognition (ASR) systems. The goal is to reduce the WER as much possible to improve the accuracy of the ASR system.
To calculate WER, complete the following steps. This post uses the open-source asr-evaluation evaluation tool to calculate WER, but other tools such as SCTK or JiWER are also available.
- Install the
asr-evaluationtool, which makes the wer script available on your command line.
Use a command line on macOS or Linux platforms to run the wer commands shown later in the post. - Copy the transcript from the Amazon Transcribe job details page to a text file named
hypothesis.txt.
When you copy the transcription from the console, you’ll notice a new line character between the wordsAgent :, Customer :,and the Hindi script.
The new line characters have been removed to save space in this post. If you choose to use the text as is from the console, make sure that the reference text file you create also has the new line characters, because the wer tool compares line by line. - Review the entire transcript and identify any words or phrases that need to be corrected:
Customer : हेलो,
Agent : गुड मोर्निग इंडिया ट्रेवल एजेंसी सेम है। लावन्या बात कर रही हूँ किस तरह से मैं आपकी सहायता कर सकती हूँ।
Customer : मैं बहुत दिनों उनसे हैदराबाद ट्रेवल के बारे में सोच रहा था। क्या आप मुझे कुछ अच्छे लोकेशन के बारे में बता सकती हैं?
Agent :हाँ बिल्कुल। हैदराबाद में बहुत सारे प्लेस है। उनमें से चार महीना गोलकुंडा फोर सलार जंग म्यूजियम और बिरला प्लेनेटोरियम मशहूर है।
Customer : हाँ बढिया थैंक यू मैं अगले सैटरडे और संडे को ट्राई करूँगा।
Agent : एक सजेशन वीकेंड में ट्रैफिक ज्यादा रहने के चांसेज है।
Customer : सिरियसली एनी टिप्स चिकन शेर
Agent : आप टेक्सी यूस कर लो ड्रैब और पार्किंग का प्राब्लम नहीं होगा।
Customer : ग्रेट आइडिया थैंक्यू सो मच।The highlighted words are the ones that the default Amazon Transcribe model didn’t render correctly. - Create another text file named
reference.txt, replacing the highlighted words with the desired words you expect to see in the transcription:
Customer : हेलो,
Agent : गुड मोर्निग सौथ इंडिया ट्रेवल एजेंसी से मैं । लावन्या बात कर रही हूँ किस तरह से मैं आपकी सहायता कर सकती हूँ।
Customer : मैं बहुत दिनोंसे हैदराबाद ट्रेवल के बारे में सोच रहा था। क्या आप मुझे कुछ अच्छे लोकेशन के बारे में बता सकती हैं?
Agent : हाँ बिल्कुल। हैदराबाद में बहुत सारे प्लेस है। उनमें से चार मिनार गोलकोंडा फोर्ट सालार जंग म्यूजियम और बिरला प्लेनेटोरियम मशहूर है।
Customer : हाँ बढिया थैंक यू मैं अगले सैटरडे और संडे को ट्राई करूँगा।
Agent : एक सजेशन वीकेंड में ट्रैफिक ज्यादा रहने के चांसेज है।
Customer : सिरियसली एनी टिप्स यू केन शेर
Agent : आप टेक्सी यूस कर लो ड्रैव और पार्किंग का प्राब्लम नहीं होगा।
Customer : ग्रेट आइडिया थैंक्यू सो मच। - Use the following command to compare the reference and hypothesis text files that you created:
You get the following output:
The wer command compares text from the files reference.txt and hypothesis.txt. It reports errors for each sentence and also the total number of errors (WER: 9.848% ( 13 / 132)) in the entire transcript.
From the preceding output, wer reported 13 errors out of 132 words in the transcript. These errors can be of three types:
- Substitution errors – These occur when Amazon Transcribe writes one word in place of another. For example, in our transcript, the word “महीना (Mahina)” was written instead of “मिनार (Minar)” in sentence 4.
- Deletion errors – These occur when Amazon Transcribe misses a word entirely in the transcript.In our transcript, the word “सौथ (South)” was missed in sentence 2.
- Insertion errors – These occur when Amazon Transcribe inserts a word that wasn’t spoken. We don’t see any insertion errors in our transcript.
Observations from the transcript created by the default model
We can make the following observations based on the transcript:
- The total WER is 9.848%, meaning 90.152% of the words are transcribed accurately.
- The default Hindi model transcribed most of the English words accurately. This is because the default model is trained to recognize the most common English words out of the box. The model is also trained to recognize Hinglish language, where English words randomly appear in Hindi conversations. For example:
- गुड मोर्निग – Good morning (sentence 2).
- ट्रेवल एजेंसी – Travel agency (sentence 2).
- ग्रेट आइडिया थैंक्यू सो मच – Great idea thank you so much (sentence 9).
- Sentence 4 has the most errors, which are the names of places in the Indian city Hyderabad:
- हाँ बिल्कुल। हैदराबाद में बहुत सारे प्लेस है। उनमें से चार महीना गोलकुंडा फोर सलार जंग म्यूजियम और बिरला प्लेनेटोरियम मशहूर है।
In the next step, we demonstrate how to correct the highlighted words in the preceding sentence using custom vocabulary in Amazon Transcribe:
- चार महीना (Char Mahina) should be चार मिनार (Char Minar)
- गोलकुंडा फोर (Golcunda Four) should be गोलकोंडा फोर्ट (Golconda Fort)
- सलार जंग (Salar Jung) should be सालार जंग (Saalar Jung)
Train the default model with a custom vocabulary
To create a custom vocabulary, you need to build a text file in a tabular format with the words and phrases to train the default Amazon Transcribe model. Your table must contain all four columns (Phrase, SoundsLike, IPA, and DisplayAs), but the Phrase column is the only one that must contain an entry on each row. You can leave the other columns empty. Each column must be separated by a tab character, even if some columns are left empty. For example, if you leave the IPA and SoundsLike columns empty for a row, the Phrase and DisplaysAs columns in that row must be separated with three tab characters (between Phrase and IPA, IPA and SoundsLike, and SoundsLike and DisplaysAs).
To train the model with a custom vocabulary, complete the following steps:
- Create a file named
HindiCustomVocabulary.txtwith the following content.You can only use characters that are supported for your language. Refer to your language’s character set for details.
The columns contain the following information:
Phrase– Contains the words or phrases that you want to transcribe accurately. The highlighted words or phrases in the transcript created by the default Amazon Transcribe model appear in this column. These words are generally acronyms, proper nouns, or domain-specific words and phrases that the default model isn’t aware of. This is a mandatory field for every row in the custom vocabulary table. In our transcript, to correct “गोलकुंडा फोर (Golcunda Four)” from sentence 4, use “गोलकुंडा-फोर (Golcunda-Four)” in this column. If your entry contains multiple words, separate each word with a hyphen (-); do not use spaces.IPA– Contains the words or phrases representing speech sounds in the written form. The column is optional; you can leave its rows empty. This column is intended for phonetic spellings using only characters in the International Phonetic Alphabet (IPA). Refer to Hindi character set for the allowed IPA characters for the Hindi language. In our example, we’re not using IPA. If you have an entry in this column, yourSoundsLikecolumn must be empty.SoundsLike– Contains words or phrases broken down into smaller pieces (typically based on syllables or common words) to provide a pronunciation for each piece based on how that piece sounds. This column is optional; you can leave the rows empty. Only add content to this column if your entry includes a non-standard word, such as a brand name, or to correct a word that is being incorrectly transcribed. In our transcript, to correct “सलार जंग (Salar Jung)” from sentence 4, use “सा-लार-जंग (Saa-lar-jung)” in this column. Do not use spaces in this column. If you have an entry in this column, yourIPAcolumn must be empty.DisplaysAs– Contains words or phrases with the spellings you want to see in the transcription output for the words or phrases in thePhrasefield. This column is optional; you can leave the rows empty. If you don’t specify this field, Amazon Transcribe uses the contents of thePhrasefield in the output file. For example, in our transcript, to correct “गोलकुंडा फोर (Golcunda Four)” from sentence 4, use “गोलकोंडा फोर्ट (Golconda Fort)” in this column.
- Upload the text file (
HindiCustomVocabulary.txt) to an S3 bucket.Now we create a custom vocabulary in Amazon Transcribe. - On the Amazon Transcribe console, choose Custom vocabulary in the navigation pane.
- For Name, enter a name.
- For Language, choose Hindi, IN (hi-IN).
- For Vocabulary input source, select S3 location.
- For Vocabulary file location on S3, enter the S3 path of the
HindiCustomVocabulary.txtfile. - Choose Create vocabulary.

- Transcribe the
SampleAudio.wavfile with the custom vocabulary, with the following parameters:- For Job name , enter
SampleAudioCustomVocabulary. - For Language, choose Hindi, IN (hi-IN).
- For Input file location on S3, browse to the location of
SampleAudio.wav. - For IAM role, select Use an existing IAM role and choose the role you created earlier.
- In the Configure job section, select Custom vocabulary and choose the custom vocabulary
HindiCustomVocabulary.
- For Job name , enter
- Choose Create job.

Measure model accuracy after using custom vocabulary
Copy the transcript from the Amazon Transcribe job details page to a text file named hypothesis-custom-vocabulary.txt:
Customer : हेलो,
Agent : गुड मोर्निग इंडिया ट्रेवल एजेंसी सेम है। लावन्या बात कर रही हूँ किस तरह से मैं आपकी सहायता कर सकती हूँ।
Customer : मैं बहुत दिनों उनसे हैदराबाद ट्रेवल के बारे में सोच रहा था। क्या आप मुझे कुछ अच्छे लोकेशन के बारे में बता सकती हैं?
Agent : हाँ बिल्कुल। हैदराबाद में बहुत सारे प्लेस है। उनमें से चार मिनार गोलकोंडा फोर्ट सालार जंग म्यूजियम और बिरला प्लेनेटोरियम मशहूर है।
Customer : हाँ बढिया थैंक यू मैं अगले सैटरडे और संडे को ट्राई करूँगा।
Agent : एक सजेशन वीकेंड में ट्रैफिक ज्यादा रहने के चांसेज है।
Customer : सिरियसली एनी टिप्स चिकन शेर
Agent : आप टेक्सी यूस कर लो ड्रैब और पार्किंग का प्राब्लम नहीं होगा।
Customer : ग्रेट आइडिया थैंक्यू सो मच।
Note that the highlighted words are transcribed as desired.
Run the wer command again with the new transcript:
You get the following output:
Observations from the transcript created with custom vocabulary
The total WER is 6.061%, meaning 93.939% of the words are transcribed accurately.
Let’s compare the wer output for sentence 4 with and without custom vocabulary. The following is without custom vocabulary:
The following is with custom vocabulary:
There are no errors in sentence 4. The names of the places are transcribed accurately with the help of custom vocabulary, thereby reducing the overall WER from 9.848% to 6.061% for this audio file. This means that the accuracy of transcription improved by nearly 4%.
How custom vocabulary improved the accuracy
We used the following custom vocabulary:
Amazon Transcribe checks if there are any words in the audio file that sound like the words mentioned in the Phrase column. Then the model uses the entries in the IPA, SoundsLike, and DisplaysAs columns for those specific words to transcribe with the desired spellings.
With this custom vocabulary, when Amazon Transcribe identifies a word that sounds like “गोलकुंडा-फोर (Golcunda-Four),” it transcribes that word as “गोलकोंडा फोर्ट (Golconda Fort).”
Recommendations
The accuracy of transcription also depends on parameters like the speakers’ pronunciation, overlapping speakers, talking speed, and background noise. Therefore, we recommend that you to follow the process with a variety of calls (with different customers, agents, interruptions, and so on) that cover the most commonly used domain-specific words for you to build a comprehensive custom vocabulary.
In this post, we learned the process to improve accuracy of transcribing one audio call using custom vocabulary. To process thousands of your contact center call recordings every day, you can use post call analytics, a fully automated, scalable, and cost-efficient end-to-end solution that takes care of most of the heavy lifting. You simply upload your audio files to an S3 bucket, and within minutes, the solution provides call analytics like sentiment in a web UI. Post call analytics provides actionable insights to spot emerging trends, identify agent coaching opportunities, and assess the general sentiment of calls.Post call analytics is an open-source solution that you can deploy using AWS CloudFormation.
Note that custom vocabularies don’t use the context in which the words were spoken, they only focus on individual words that you provide. To further improve the accuracy, you can use custom language models. Unlike custom vocabularies, which associate pronunciation with spelling, custom language models learn the context associated with a given word. This includes how and when a word is used, and the relationship a word has with other words. To create a custom language model, you can use the transcriptions derived from the process we learned for a variety of calls, and combine them with content from your websites or user manuals that contains domain-specific words and phrases.
To achieve the highest transcription accuracy with batch transcriptions, you can use custom vocabularies in conjunction with your custom language models.
Conclusion
In this post, we provided detailed steps to accurately process Hindi audio files containing English words using call analytics and custom vocabularies in Amazon Transcribe. You can use these same steps to process audio calls with any language supported by Amazon Transcribe.
After you derive the transcriptions with your desired accuracy, you can improve your agent-customer conversations by training your agents. You can also understand your customer sentiments and trends. With the help of speaker diarization, loudness detection, and vocabulary filtering features in the call analytics, you can identify whether it was the agent or customer who raised their tone or spoke any specific words. You can categorize calls based on domain-specific words, capture actionable insights, and run analytics to improve your products. Finally, you can translate your transcripts to English or other supported languages of your choice using Amazon Translate.
About the Authors
 Sarat Guttikonda is a Sr. Solutions Architect in AWS World Wide Public Sector. Sarat enjoys helping customers automate, manage, and govern their cloud resources without sacrificing business agility. In his free time, he loves building Legos with his son and playing table tennis.
Sarat Guttikonda is a Sr. Solutions Architect in AWS World Wide Public Sector. Sarat enjoys helping customers automate, manage, and govern their cloud resources without sacrificing business agility. In his free time, he loves building Legos with his son and playing table tennis.
 Lavanya Sood is a Solutions Architect in AWS World Wide Public Sector based out of New Delhi, India. Lavanya enjoys learning new technologies and helping customers in their cloud adoption journey. In her free time, she loves traveling and trying different foods.
Lavanya Sood is a Solutions Architect in AWS World Wide Public Sector based out of New Delhi, India. Lavanya enjoys learning new technologies and helping customers in their cloud adoption journey. In her free time, she loves traveling and trying different foods.