Artificial Intelligence
Prepare and analyze JSON and ORC data with Amazon SageMaker Data Wrangler
Amazon SageMaker Data Wrangler is a new capability of Amazon SageMaker that makes it faster for data scientists and engineers to prepare data for machine learning (ML) applications via a visual interface. Data preparation is a crucial step of the ML lifecycle, and Data Wrangler provides an end-to-end solution to import, prepare, transform, featurize, and analyze data for ML in a seamless, visual, low-code experience. It lets you easily and quickly connect to AWS components like Amazon Simple Storage Service (Amazon S3), Amazon Athena, Amazon Redshift, and AWS Lake Formation, and external sources like Snowflake. Data Wrangler also supports standard data types such as CSV and Parquet.
Data Wrangler now additionally supports Optimized Row Columnar (ORC), JavaScript Object Notation (JSON), and JSON Lines (JSONL) file formats:
- ORC – The ORC file format provides a highly efficient way to store Hive data. It was designed to overcome limitations of the other Hive file formats. Using ORC files improves performance when Hive is reading, writing, and processing data. ORC is widely used in the Hadoop ecosystem.
- JSON – The JSON file format is a lightweight, commonly used data interchange format.
- JSONL – JSON Lines, also called newline-delimited JSON, is a convenient format for storing structured data that may be processed one record at a time.
You can preview ORC, JSON, and JSONL data prior to importing the datasets into Data Wrangler. After you import the data, you can also use one of the newly launched transformers to work with columns that contain JSON strings or arrays that are commonly found in nested JSONs.
Import and analyze ORC data with Data Wrangler
Importing ORC data is in Data Wrangler is easy and similar to importing files in any other supported formats. Browse to your ORC file in Amazon S3 and in the DETAILS pane, choose ORC as the file type during import.

If you’re new to Data Wrangler, review Get Started with Data Wrangler. Also, see Import to learn about the various import options.
Import and analyze JSON data with Data Wrangler
Now let’s import files in JSON format with Data Wrangler and work with columns that contain JSON strings or arrays. We also demonstrate how to deal with nested JSONs. With Data Wrangler, importing JSON files from Amazon S3 is a seamless process. This is similar to importing files in any other supported formats. After you import the files, you can preview the JSON files as shown in the following screenshot. Make sure to set the file type to JSON in the DETAILS pane.
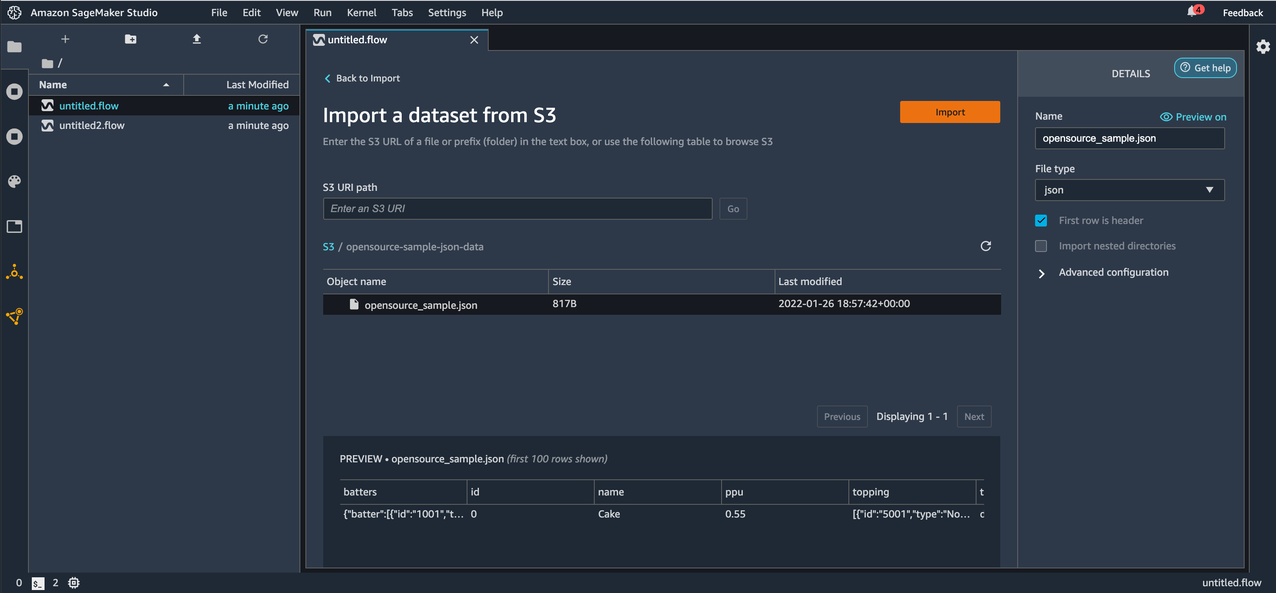
Next, let’s work on structured columns in the imported JSON file.
To deal with structured columns in JSON files, Data Wrangler is introducing two new transforms: Flatten structured column and Explode array column, which can be found under the Handle structured column option in the ADD TRANSFORM pane.
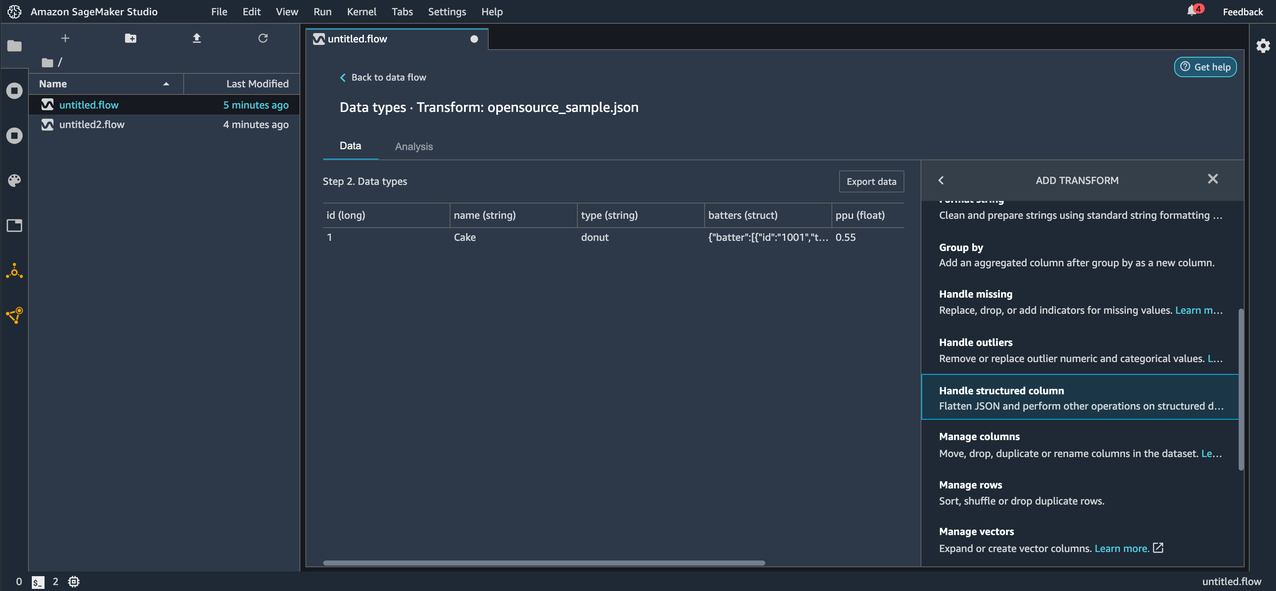
Let’s start by applying the Explode array column transform to one of the columns in our imported data. Before applying the transform, we can see the column topping is an array of JSON objects with id and type keys.
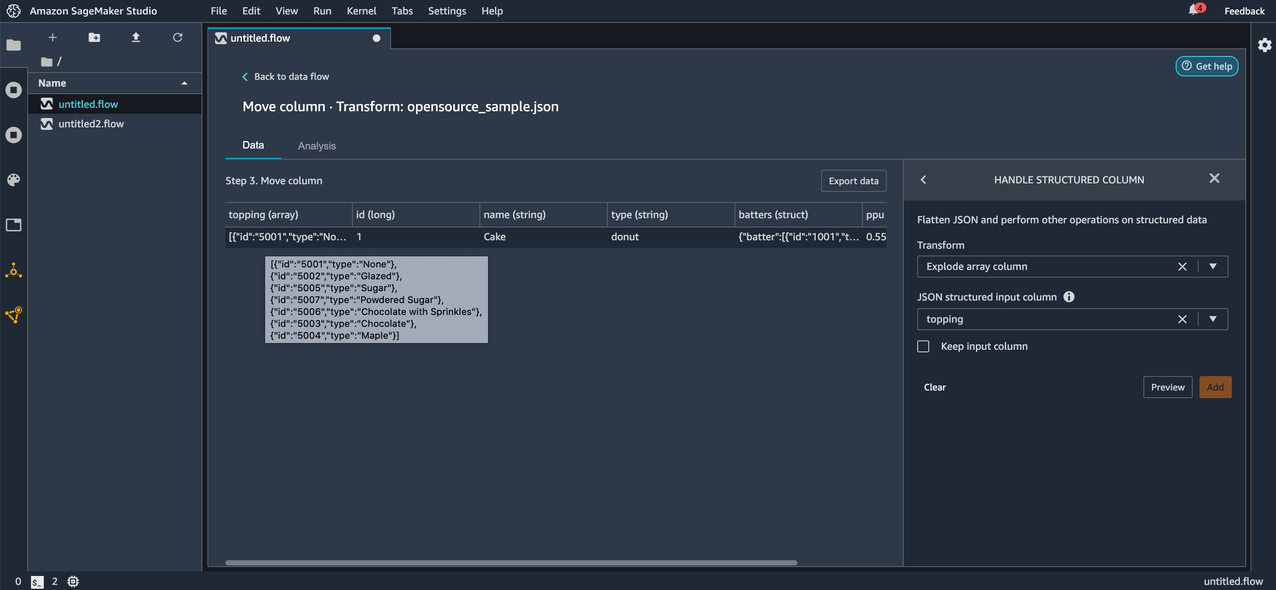
After we apply the transform, we can observe the new rows added as a result. Each element in the array is now a new row in the resulting DataFrame.
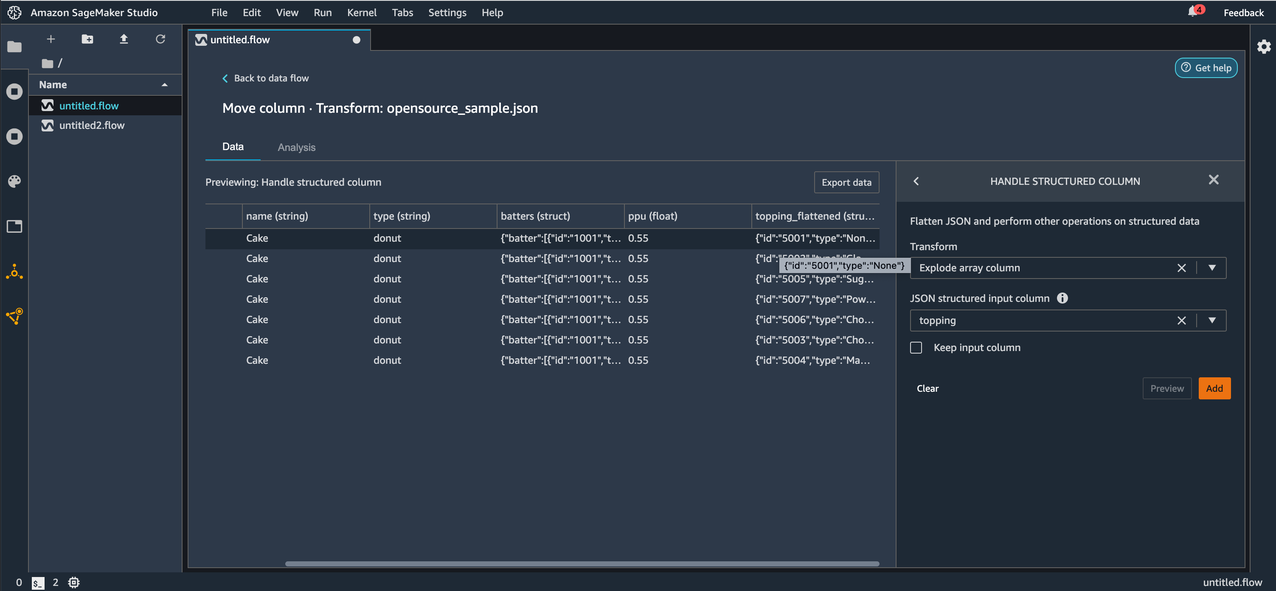
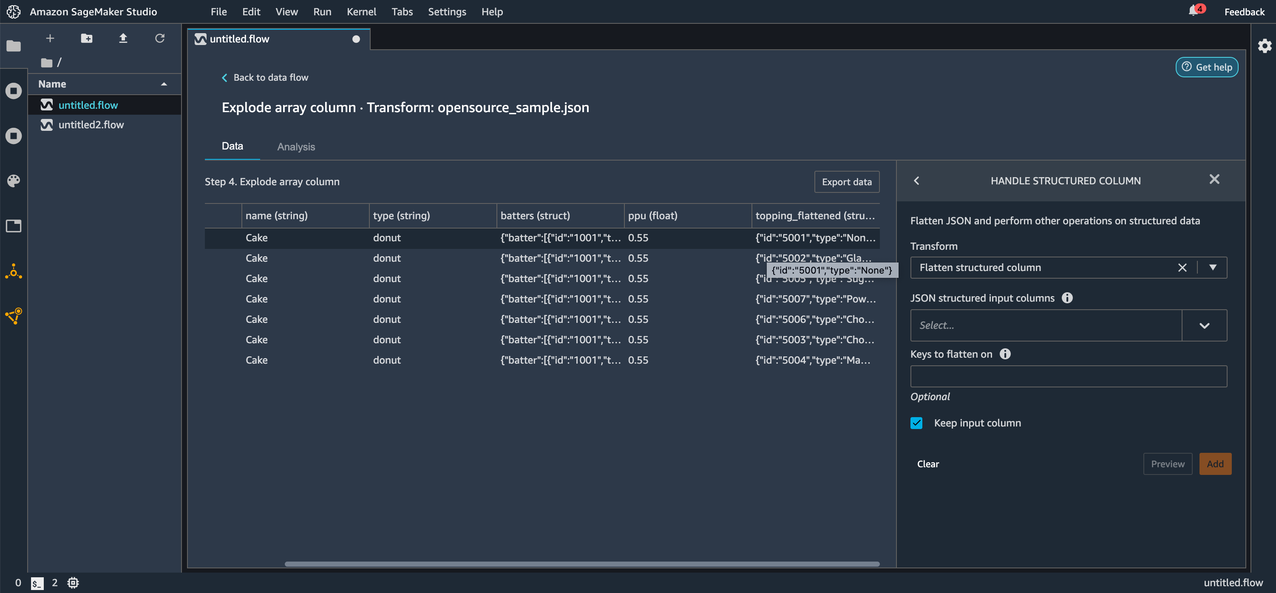
Now let’s apply the Flatten structured column transform on the topping_flattened column that was created as a result of the Explode array column transformation we applied in the previous step.
Before applying the transform, we can see the keys id and type in the topping_flattened column.
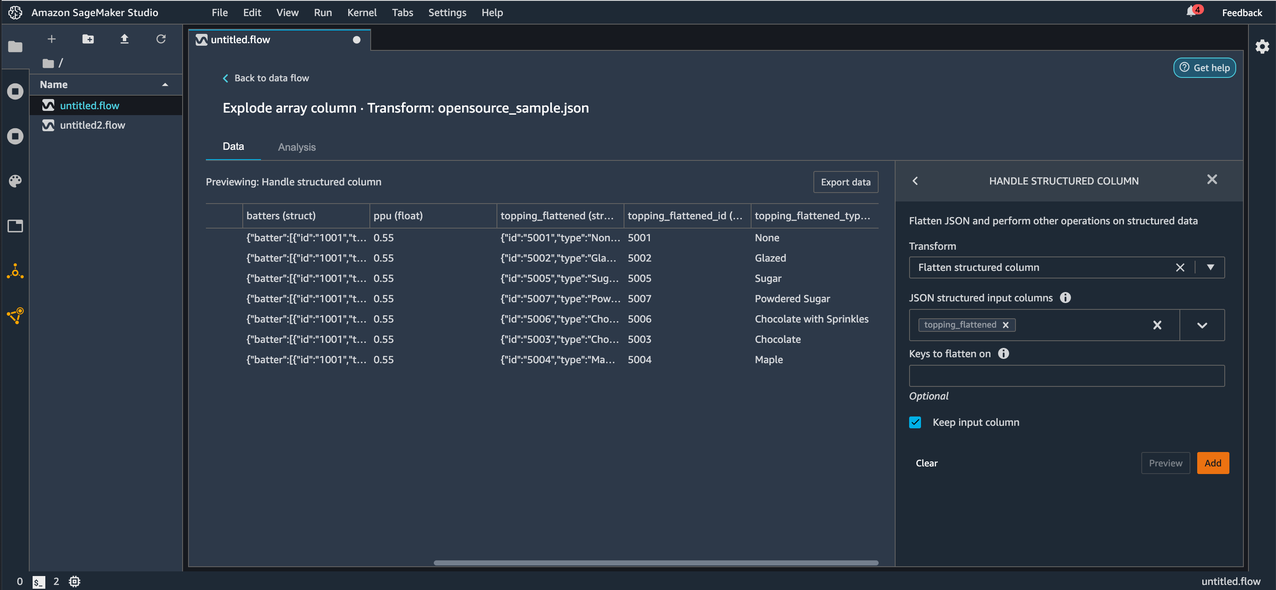
After applying the transform, we can now observe the keys id and type under the topping_flattened column as new columns topping_flattened_id and topping_flattened_type, which are created as a result of the transformation. You also have the option to flatten only specific keys by entering the comma separated key names for Keys to flatten on. If left empty, all the keys inside the JSON string or struct are flattened.
Conclusion
In this post, we demonstrated how to import file formats in ORC and JSON easily with Data Wrangler. We also applied the newly launched transformations that allow us to transform any structured columns in JSON data. This makes working with columns that contain JSON strings or arrays a seamless experience.
As next steps, we recommend you replicate the demonstrated examples in your own Data Wrangler visual interface. If you have any questions related to Data Wrangler, feel free to leave them in the comment section.
About the Authors
 Balaji Tummala is a Software Development Engineer at Amazon SageMaker. He helps support Amazon SageMaker Data Wrangler and is passionate about building performant and scalable software. Outside of work, he enjoys reading fiction and playing volleyball.
Balaji Tummala is a Software Development Engineer at Amazon SageMaker. He helps support Amazon SageMaker Data Wrangler and is passionate about building performant and scalable software. Outside of work, he enjoys reading fiction and playing volleyball.
 Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.
Arunprasath Shankar is an Artificial Intelligence and Machine Learning (AI/ML) Specialist Solutions Architect with AWS, helping global customers scale their AI solutions effectively and efficiently in the cloud. In his spare time, Arun enjoys watching sci-fi movies and listening to classical music.