Artificial Intelligence
Reduce deep learning training time and cost with MosaicML Composer on AWS
In the past decade, we have seen Deep learning (DL) science adopted at a tremendous pace by AWS customers. The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. In this post, we highlight challenges commonly reported specifically in DL training, and how the open-source library MosaicML Composer helps solve them.
The challenge with DL training
DL models are trained iteratively, in a nested for loop. A loop iterates through the training dataset chunk by chunk and, if necessary, this loop is repeated several times over the whole dataset. ML practitioners working on DL training face several challenges:
- Training duration grows with data size. With permanently-growing datasets, training times and costs grow too, and the rhythm of scientific discovery slows down.
- DL scripts often require boilerplate code, notably the aforementioned double for loop structure that splits the dataset into minibatches and the training into epochs.
- The paradox of choice: several training optimization papers and libraries are published, yet it’s unclear which one to test first, and how to combine their effects.
In the past few years, several open-source libraries such as Keras, PyTorch Lightning, Hugging Face Transformers, and Ray Train have been attempting to make DL training more accessible, notably by reducing code verbosity, thereby simplifying how neural networks are programmed. Most of those libraries have focused on developer experience and code compactness.
In this post, we present a new open-source library that takes a different stand on DL training: MosaicML Composer is a speed-centric library whose primary objective is to make neural network training scripts faster via algorithmic innovation. In the cloud DL world, it’s wise to focus on speed, because compute infrastructure is often paid per use—even down to the second on Amazon SageMaker Training—and improvements in speed can translate into money savings.
Historically, speeding up DL training has mostly been done by increasing the number of machines computing model iterations in parallel, a technique called data parallelism. Although data parallelism sometimes accelerates training (not guaranteed because it disturbs convergence, as highlighted in Goyal et al.), it doesn’t reduce overall job cost. In practice, it tends to increase it, due to inter-machine communication overhead and higher machine unit cost, because distributed DL machines are equipped with high-end networking and in-server GPU interconnect.
Although MosaicML Composer supports data parallelism, its core philosophy is different from the data parallelism movement. Its goal is to accelerate training without requiring more machines, by innovating at the science implementation level. Therefore, it aims to achieve time savings which would result in cost savings due to AWS’ pay-per-use fee structure.
Introducing the open-source library MosaicML Composer
MosaicML Composer is an open-source DL training library purpose-built to make it simple to bring the latest algorithms and compose them into novel recipes that speed up model training and help improve model quality. At the time of this writing, it supports PyTorch and includes 25 techniques—called methods in the MosaicML world—along with standard models, datasets, and benchmarks
Composer is available via pip:
pip install mosaicmlSpeedup techniques implemented in Composer can be accessed with its functional API. For example, the following snippet applies the BlurPool technique to a TorchVision ResNet:
import logging
from composer import functional as CF
import torchvision.models as models
logging.basicConfig(level=logging.INFO)
model = models.resnet50()
CF.apply_blurpool(model)Optionally, you can also use a Trainer to compose your own combination of techniques:
from composer import Trainer
from composer.algorithms import LabelSmoothing, CutMix, ChannelsLast
trainer = Trainer(
model=.. # must be a composer.ComposerModel
train_dataloader=...,
max_duration="2ep", # can be a time, a number of epochs or batches
algorithms=[
LabelSmoothing(smoothing=0.1),
CutMix(alpha=1.0),
ChannelsLast(),
]
)
trainer.fit()Examples of methods implemented in Composer
Some of the methods available in Composer are specific to computer vision, for example image augmentation techniques ColOut, Cutout, or Progressive Image Resizing. Others are specific to sequence modeling, such as Sequence Length Warmup or ALiBi. Interestingly, several are agnostic of the use case and can be applied to a variety of PyTorch neural networks beyond computer vision and NLP. Those generic neural network training acceleration methods include Label Smoothing, Selective Backprop, Stochastic Weight Averaging, Layer Freezing, and Sharpness Aware Minimization (SAM).
Let’s dive deep into a few of them that were found particularly effective by the MosaicML team:
- Sharpness Aware Minimization (SAM) is an optimizer than minimizes both the model loss function and its sharpness by computing a gradient twice for each optimization step. To limit the extra compute to penalize the throughput, SAM can be run periodically.
- Attention with Linear Biases (ALiBi), inspired by Press et al., is specific to Transformers models. It removes the need for positional embeddings, replacing them with a non-learned bias to attention weights.
- Selective Backprop, inspired by Jiang et al., allows you to run back-propagation (the algorithms that improve model weights by following its error slope) only on records with high loss function. This method helps you avoid unnecessary compute and helps improve throughput.
Having those techniques available in a single compact training framework is a significant value added for ML practitioners. What is also valuable is the actionable field feedback the MosaicML team produces for each technique, tested and rated. However, given such a rich toolbox, you may wonder: what method shall I use? Is it safe to combine the use of multiple methods? Enter MosaicML Explorer.
MosaicML Explorer
To quantify the value and compatibility of DL training methods, the MosaicML team maintains Explorer, a first-of-its kind live dashboard picturing dozens of DL training experiments over five datasets and seven models. The dashboard pictures the pareto optimal frontier in the cost/time/quality trade-off, and allows you to browse and find top-scoring combinations of methods—called recipes in the MosaicML world—for a given model and dataset. For example, the following graphs show that for a 125M parameter GPT2 training, the cheapest training maintaining a perplexity of 24.11 is obtained by combining AliBi, Sequence Length Warmup, and Scale Schedule, reaching a cost of about $145.83 in the AWS Cloud! However, please note that this cost calculation and the ones that follow in this post are based on an EC2 on-demand compute only, other cost considerations may be applicable, depending on your environment and business needs.
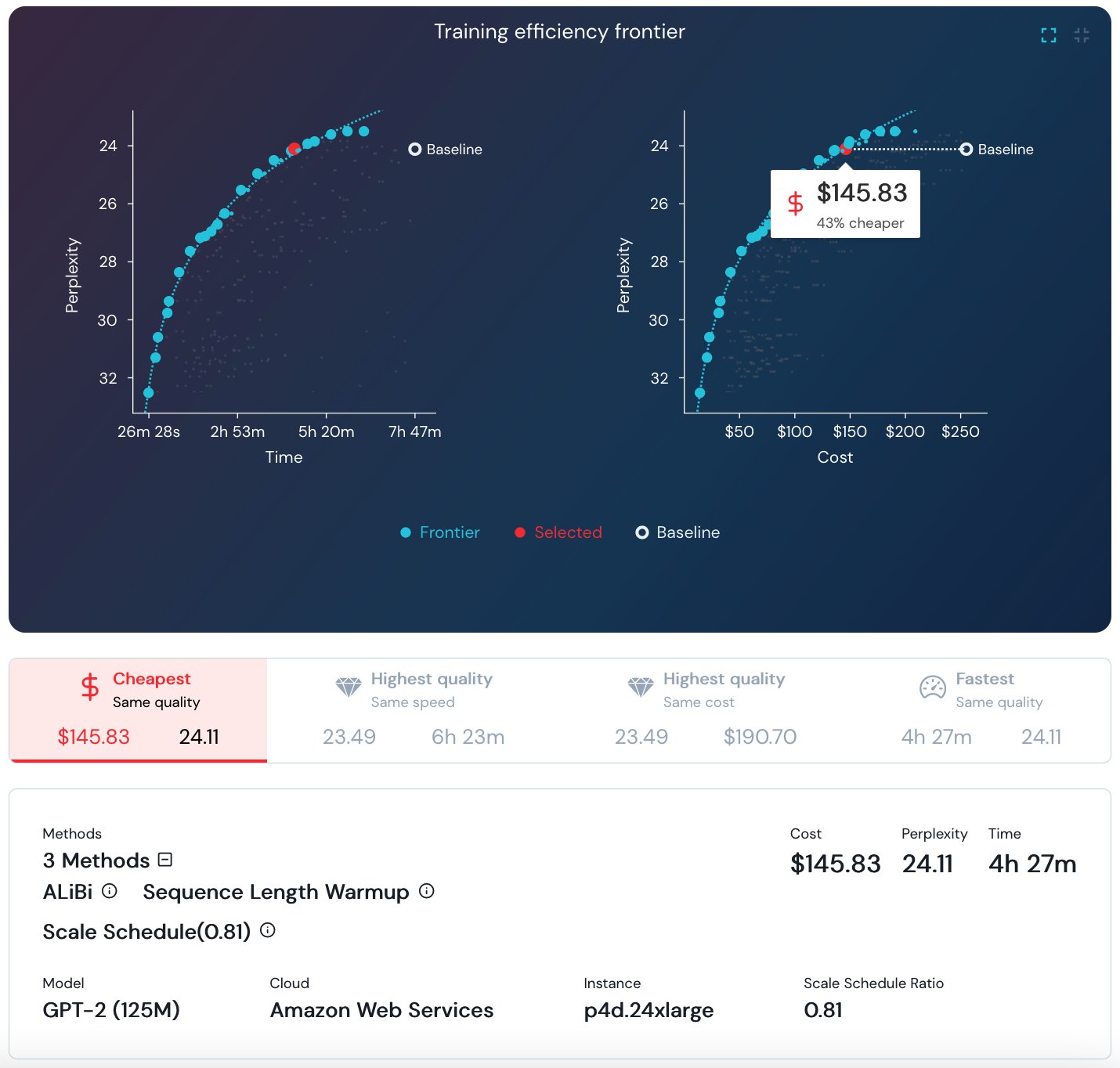
Screenshot of MosaicML Explorer for GPT-2 training
Notable achievements with Composer on AWS
By running the Composer library on AWS, the MosaicML team achieved a number of impressive results. Note that costs estimates reported by MosaicML team consist of on-demand compute charge only.
- ResNet-50 training on ImageNet to 76.6% top-one accuracy for ~$15 in 27 minutes (MosaicML Explorer link)
- GPT-2 125M parameter training to a perplexity of 24.11 for ~$145 (MosaicML Explorer link)
- BERT-Base training to Average Dev-Set Accuracy of 83.13% for ~$211 (MosaicML Explorer link)
Conclusion
You can get started with Composer on any compatible platform, from your laptop to large GPU-equipped cloud servers. The library features intuitive Welcome Tour and Getting Started documentation pages. Using Composer in AWS allows you to cumulate Composer cost-optimization science with AWS cost-optimization services and programs, including Spot compute (Amazon EC2, Amazon SageMaker), Savings Plan, SageMaker automatic model tuning, and more. The MosaicML team maintains a tutorial of Composer on AWS. It provides a step-by-step demonstration of how you can reproduce MLPerf results and train ResNet-50 on AWS to the standard 76.6% top-1 accuracy in just 27 minutes.
If you’re struggling with neural networks that are training too slow, or if you’re looking to keep your DL training costs under control, give MosaicML on AWS a try and let us know what you build!
About the authors
 Bandish Shah is an Engineering Manager at MosaicML, working to bridge efficient deep learning with large scale distributed systems and performance computing. Bandish has over a decade of experience building systems for machine learning and enterprise applications. He enjoys spending time with friends and family, cooking and watching Star Trek on repeat for inspiration.
Bandish Shah is an Engineering Manager at MosaicML, working to bridge efficient deep learning with large scale distributed systems and performance computing. Bandish has over a decade of experience building systems for machine learning and enterprise applications. He enjoys spending time with friends and family, cooking and watching Star Trek on repeat for inspiration.
 Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.
Olivier Cruchant is a Machine Learning Specialist Solutions Architect at AWS, based in France. Olivier helps AWS customers – from small startups to large enterprises – develop and deploy production-grade machine learning applications. In his spare time, he enjoys reading research papers and exploring the wilderness with friends and family.