Artificial Intelligence
Unlock insights from your Amazon S3 data with intelligent search
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines enterprise search for your websites and applications so your employees and customers can easily find the content they’re looking for, even when it’s scattered across multiple locations and content repositories within your organization. Keywords or natural language questions can be used to search most relevant documents powered by ML to deliver answers and rank documents. Amazon Kendra can index data from Amazon Simple Storage Service (Amazon S3) or from a third-party document repository. Amazon S3 is an object storage service that offers scalability and availability where you can store large amounts of data, including product manuals, project and research documents, and more.
In this post, you can learn how to deploy a provided AWS CloudFormation template to index your documents in an Amazon S3 bucket. The template creates an Amazon Kendra data source for an index and synchronizes your data source according to your needs: on-demand, hourly, daily, weekly or monthly. AWS CloudFormation allows us to provision infrastructure as code (IaC) so you can spend less time managing resources, replicate your infrastructure quickly, and control and track changes in the infrastructure.
Overview of the solution
The CloudFormation template sets up an Amazon Kendra data source with a connection to Amazon S3. The template also creates one role for the Amazon Kendra data source service. You can specify an S3 bucket, synchronization schedule, and inclusion/exclusion patterns. When the synchronization job has finished, you can search the indexed content through the Search console. The following diagram illustrates this workflow.
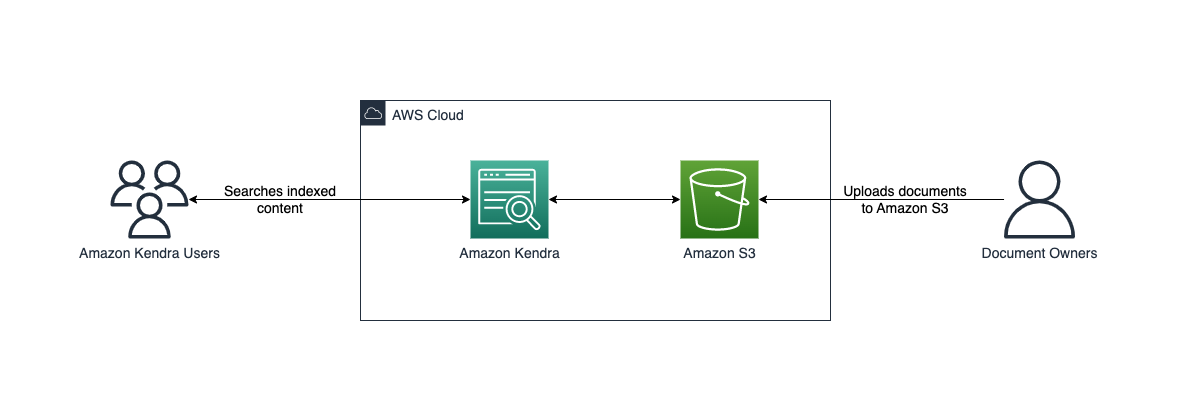
This post guides you to the following steps:
- Deploy the provided template.
- Upload the documents to the S3 bucket that you create. If you provide a bucket with documents, you can omit this step.
- Wait until the index finishes crawling the data source.
Prerequisites
For this walkthrough, you should have the following prerequisites:
- An AWS account where the proposed solution can be deployed.
- An Amazon Kendra index for attaching a data source to the stack.
- The set of documents that are used to create the Amazon Kendra index. In this solution, you are using a compressed file of AWS whitepapers.
Deploy the solution with AWS CloudFormation
To deploy the CloudFormation template, complete the following steps:
- Choose

You’re redirected to the AWS CloudFormation console.
- You can modify the parameters or use the default values:
- The Amazon Kendra data source name is automatically set using the stack name and associated bucket name.
- For KendraIndexId, enter the Amazon Kendra index ID where you will attach the data source.
- You can also choose when you want to run the data source synchronization using KendraSyncSchedule. By default, it’s set to OnDemand.
- For S3BucketName, you can either enter a bucket you have already created or leave it empty. If you leave it empty, a bucket will be created for you. Either way, the bucket is used as the Amazon Kendra data source. For this post, we leave it empty.
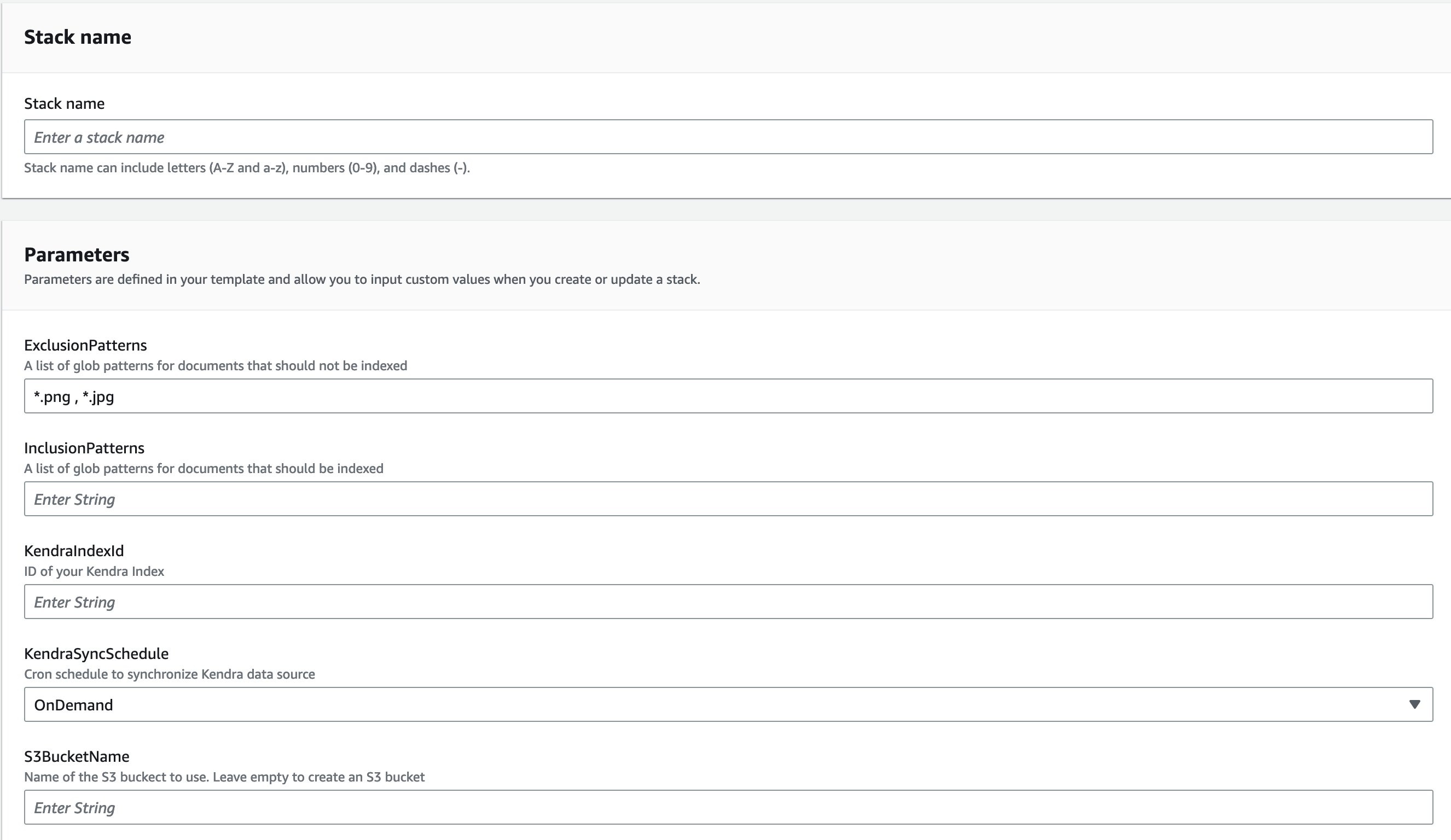
It takes around 5 minutes for the stack to deploy the Amazon Kendra data source attached to the Amazon Kendra index.
- On the Outputs tab of the CloudFormation stack, copy the name of the created bucket, data source name, and ID.
The created stack deploys one role: <stack-name>-KendraDataSourceRole. It’s a best practice to deploy a role for each data source you create. This role gives Amazon Kendra data source to add or remove files from Amazon Kendra index, to get objects from Amazon S3 bucket.
Upload files to the S3 bucket
Amazon Kendra can handle multiple document types, such as .html, .pdf, .csv, .json, .docx, and .ppt. You can also have a combination of documents on a single index. The text contained in those documents is indexed to the provided Amazon Kendra index. You can search for keywords on AWS topics on best practices, databases, machine learning, security, and more using over 60 pdf files that you can download. For example, if you want to know where you can find more information about caching in the AWS whitepapers, Amazon Kendra can help you find documents related to databases and best practices.
When you download the AWS Whitepapers.zip file and uncompress the file, you see these six folders: Best_Practices, Databases, General, Machine_Learning, Security, Well_Architected. Upload these folders to your S3 bucket.

Synchronize the Amazon Kendra data source
Amazon Kendra data source data can synchronize your data based on preconfigured schedule or can be be manually triggered on-demand. By default, CloudFormation template configures the data source to on-demand synchronization schedule to be triggered manually as required.
To manually trigger the synchronization job from the AWS Amazon Kendra console, navigate to the Amazon Kendra index used as part of CloudFormation stack deployment, under Data Management in the navigation pane, choose Data Sources and then choose Sync now. This makes the S3 bucket synchronize with the data source.
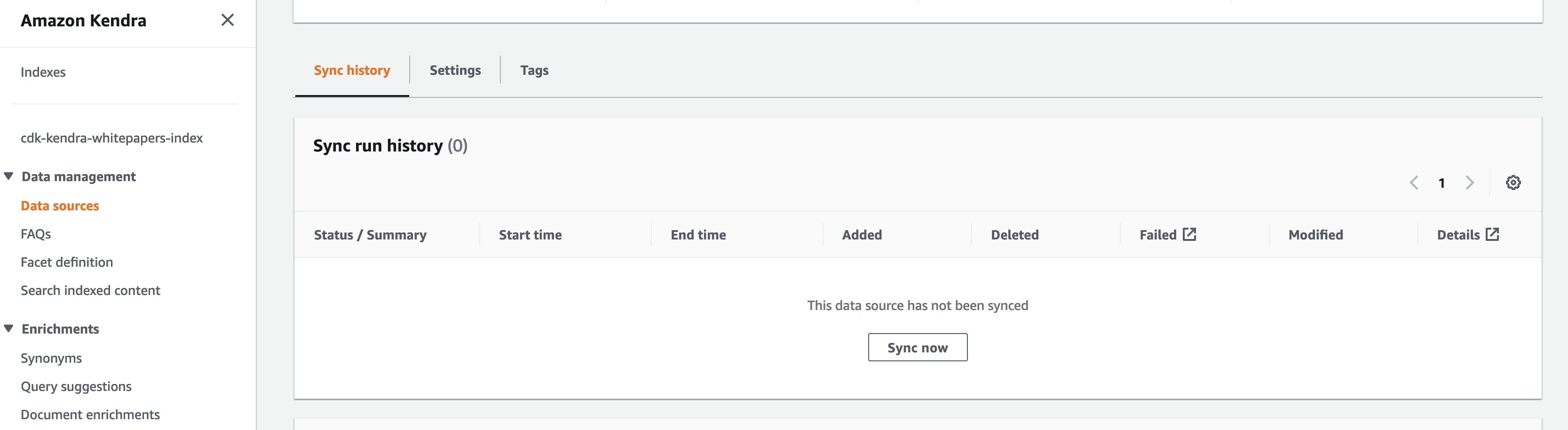
When the Amazon Kendra data source starts syncing, you should see the Current sync state as Syncing.

When the data source has finished, the Last sync status appears as Succeeded and Current sync state as Idle. You can now search the indexed content.

Configure synchronization schedule
The template allows you to run the schedule every hour at minute 0, for example, 13:00, 14:00, or 15:00. You also have the option to run it daily at 00:00 UTC. The Weekly setting runs Mondays at 00:00 UTC, and the Monthly setting runs every first day of the month at 00:00 UTC.
To change the schedule after the Amazon Kendra data source has been created, on the Actions menu, choose Edit. Under Configure sync settings, you find the Sync rule schedule section.
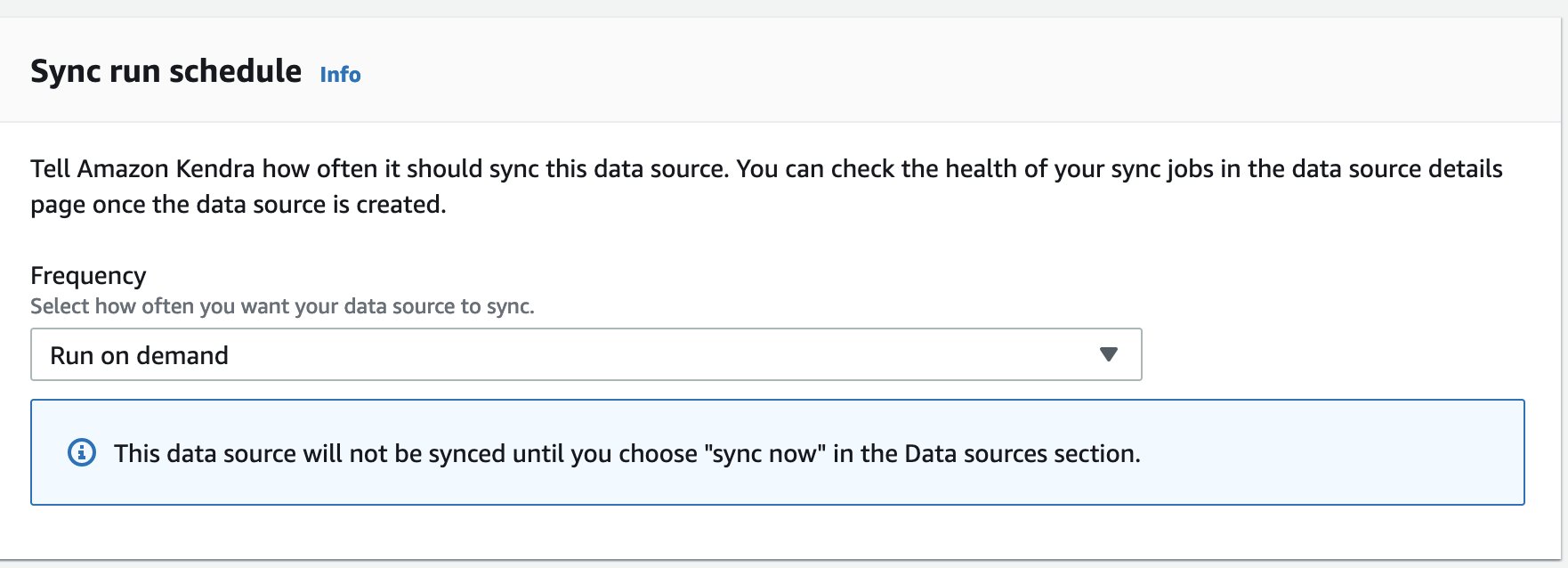
Under Frequency, you can select hourly, daily, weekly, monthly, or custom, all of which allow you to schedule your sync down to the minute.
Add exclusion patterns
The provided CloudFormation template allows you to add exclusion patterns. By default, .png and .jpg files will be added to the ExclusionPatterns parameter. Additional file formats can be added as a comma separated list to the exclusion pattern. Similarly, InclusionPatterns parameter may be used add comma list file formats to set up an inclusion pattern. If you don’t provide an inclusion pattern, all files are indexed except for the ones included in the exclusion parameter.
Clean up
To avoid costs, you can delete the stack from the AWS CloudFormation console. On the Stacks page, select the stack you created, choose Delete, and confirm the deletion of the stack.

If you haven’t provided a S3 bucket, the stack creates a bucket. If the bucket is empty, it’s automatically deleted. Otherwise, you need to empty the folder and manually delete it. If you provided a bucket, even if it’s empty, it won’t be deleted. Amazon Kendra index won’t be deleted. Only the Amazon Kendra data source created by the stack will be deleted.
Conclusion
In this post, we provided an CloudFormation template to easily synchronize your text documents on an S3 bucket to your Amazon Kendra index. This solution is helpful if you have multiple S3 buckets you want to index because you can create all the necessary components to query the documents with a few clicks in a consistent and repeatable manner. You can also see how image-based text documents can be handled in Amazon Kendra. To learn more about specific schedule patterns, refer to Schedule Expressions for Rules.
Leave a comment and learn more about Amazon Kendra index creation in the following Amazon Kendra Essentials+ workshop.
Special thanks to Jose Mauricio Mani Yanez for his help creating the example code and compiling the content for this post.
About the author
 Rajesh Kumar Ravi is an AI/ML Specialist Solutions Architect at Amazon Web Services specializing in intelligent document search with Amazon Kendra and generative AI. He is a builder and problem solver, and contributes to development of new ideas. He enjoys walking and loves to go on short hiking trips outside of work.
Rajesh Kumar Ravi is an AI/ML Specialist Solutions Architect at Amazon Web Services specializing in intelligent document search with Amazon Kendra and generative AI. He is a builder and problem solver, and contributes to development of new ideas. He enjoys walking and loves to go on short hiking trips outside of work.