Artificial Intelligence
Unravel the knowledge in Slack workspaces with intelligent search using the Amazon Kendra Slack connector
Organizations use messaging platforms like Slack to bring the right people together to securely communicate with each other and collaborate to get work done. A Slack workspace captures invaluable organizational knowledge in the form of the information that flows through it as the users collaborate. However, making this knowledge easily and securely available to users is challenging due to the fragmented structure of Slack workspaces. Additionally, the conversational nature of Slack communication renders a traditional keyword-based approach to search ineffective.
You can now use the Amazon Kendra Slack connector to index Slack messages and documents, and search this content using intelligent search in Amazon Kendra, powered by machine learning (ML).
This post shows how to configure the Amazon Kendra Slack connector and take advantage of the service’s intelligent search capabilities. We use an example of an illustrative Slack workspace used by members to discuss technical topics related to AWS.
Solution overview
Slack workspaces include public channels where any workspace user can participate, and private channels where only those users who are members of these channels can communicate with each other. Furthermore, individuals can directly communicate with one another in one-on-one and ad hoc groups. This communication is in the form of messages and threads of replies, with optional document attachments. Slack workspaces of active organizations are dynamic, with its content and collaboration evolving continuously.
In our solution, we configure a Slack workspace as a data source to an Amazon Kendra search index using the Amazon Kendra Slack connector. Based on the configuration, when the data source is synchronized, the connector either crawls and indexes all the content from the workspace that was created on or before a specific date, or can optionally be based on a look back parameter in a change log mode. The look back parameter lets you crawl the date back a number of days since the last time you synced your data source. The connector also collects and ingests Access Control List (ACL) information for each indexed message and document. When access control or user context filtering is enabled, the search results of a query made by a user includes results only from those documents that the user is authorized to read.
Prerequisites
To try out the Amazon Kendra connector for Slack using this post as a reference, you need the following:
- An AWS account with privileges to create AWS Identity and Access Management (IAM) roles and policies. For more information, see Overview of access management: Permissions and policies.
- Basic knowledge of AWS and working knowledge of Slack workspace administration.
- Admin access to a Slack workspace.
Configure your Slack workspace
The following screenshot shows our example Slack workspace:

The workspace has five users as members: Workspace Admin, Generic User, DB Solutions Architect, ML Solutions Architect, and Solutions Architect. There are three public channels, #general, #random, and #test-slack-workspace, which any member can access. Regarding the secure channels, #databases has Workspace Admin and DB Solutions Architect as members, #machine-learning has Workspace Admin and ML Solutions Architect as members, and #security and #well-architected secure channels have Solutions Architect, DB Solutions Architect, ML Solutions Architect, and Workspace Admin as members. The connector-test app is configured in the Slack workspace in order to create a user OAuth token to be used in configuring the Amazon Kendra connector for Slack.
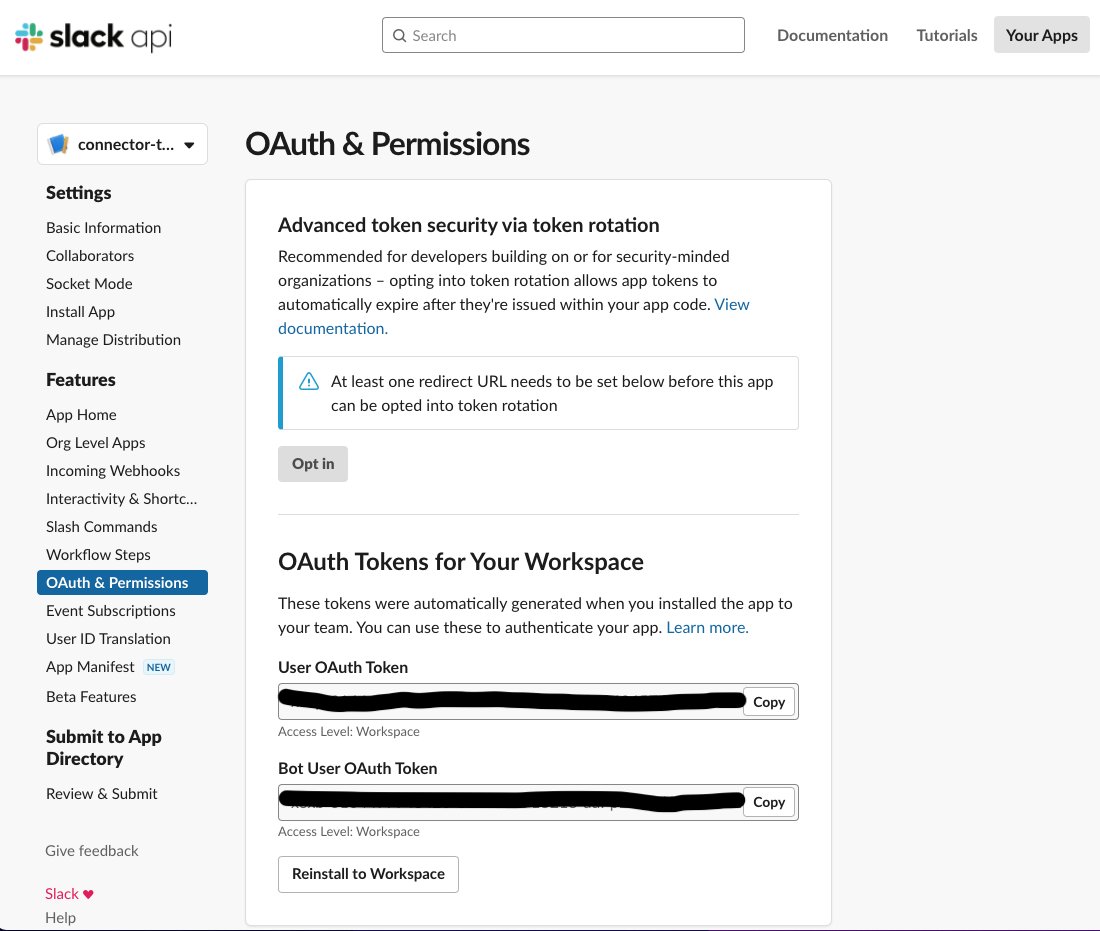
The following screenshot shows the configuration details of the connector-test app OAuth tokens for the Slack workspace. We use the user OAuth token in configuring the Amazon Kendra connector for Slack.
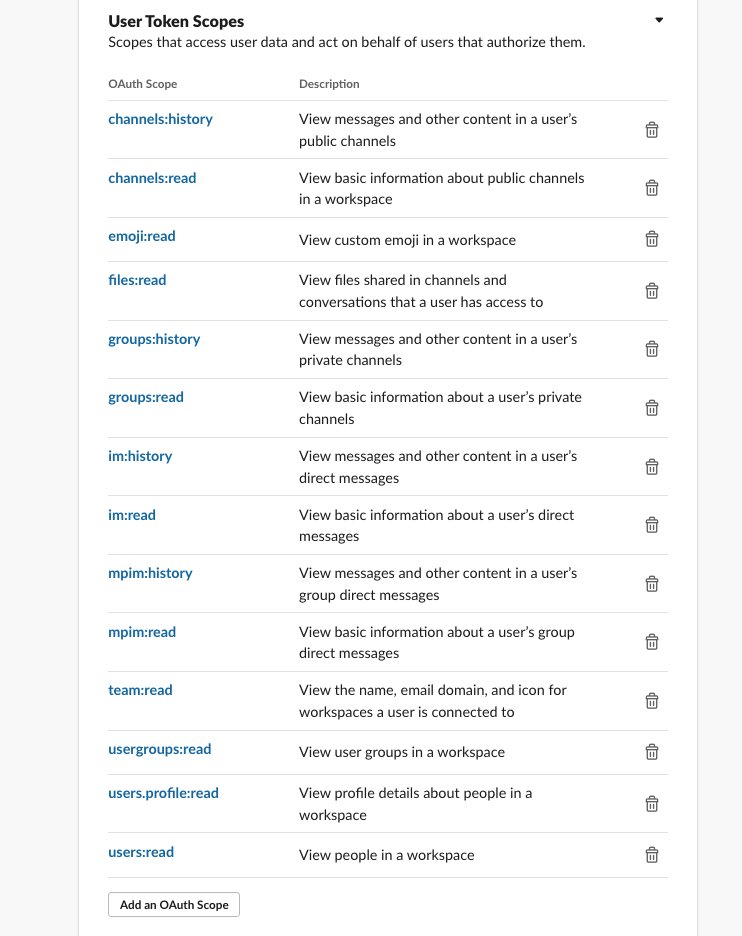
In the User Token Scopes section, we configure the connector-test app for the Slack workspace.
Configure the data source using the Amazon Kendra connector for Slack
To add a data source to your Amazon Kendra index using the Slack connector, you can use an existing Amazon Kendra index, or create a new Amazon Kendra index. Then complete the steps below. For more information on this topic, please refer to the section on Amazon Kendra connector for Slack in the Amazon Kendra Developer Guide.
- On the Amazon Kendra console, open the index and choose Data sources in the navigation pane.
- Under Slack, choose Add data source.
- Choose Add connector.

- In the Specify data source details section, enter the details of your data source and choose Next.
- In the Define access and security section, for Slack workspace team ID, enter the ID for your workspace.
- Under Authentication, you can either choose Create to add a new secret using the user OAuth token created for the
connector-app, or use an existing AWS Secrets Manager secret that has the user OAuth token for the workspace that you want the connector to access. - For IAM role, you can choose Create a new role or choose an existing IAM role configured with appropriate IAM policies to access the Secrets Manager secret, Amazon Kendra index, and data source.
- Choose Next.

- In the Configure sync settings section, provide information regarding your sync scope and run schedule.
- Choose Next.

- In the Set field mappings section, you can optionally configure the field mappings, or how the Slack field names are mapped to Amazon Kendra attributes or facets.
- Choose Next.
- Review your settings and confirm to add the data source.
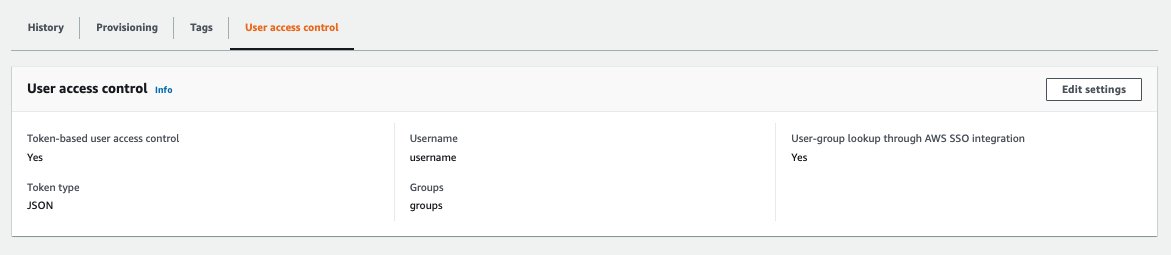
When the data source sync is complete, the User access control tab for the Amazon Kendra index is enabled. Note that in order to use the ACLs for Slack connector, it’s not necessary to enable User-group lookup through AWS SSO integration, though it is enabled in the following screenshot.
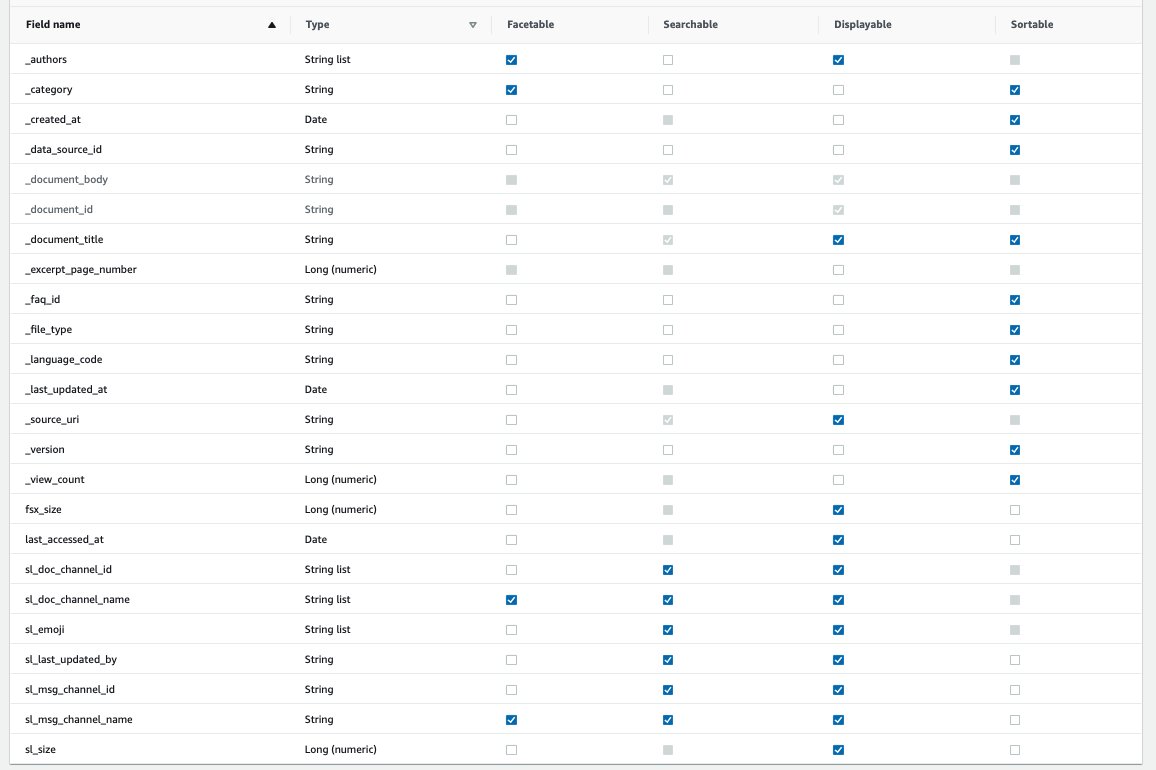
While making search queries, we want to interact with facets such as the channels of the workspace, category of the document, and the authors.
- Choose Facet definition in the navigation pane.
- Select the checkbox in the Facetable column for the facets
_authors,_category,sl_doc_channel_name, andsl_msg_channel_name.
Search with Amazon Kendra
Now we’re ready to make a few queries on the Amazon Kendra search console by choosing Search indexed content in the navigation pane.
In the first query, the user name is set to the email address of Generic User. The following screenshot shows the query response. Note that we get an answer from the aws-overview.pdf document posted in #general channel, followed by a few results from relevant documents or messages. The facets show the categories of the results to be MESSAGE and FILE. The sl_doc_channel_name facet includes the information that the document is from #general channel, the sl_msg_channel_name includes the information that there are results from all the open channels (namely #random, #general, and #test-slack-workspace), and the authors facet includes the names of the authors of the messages.

Now let’s set the user name to be the email address corresponding to the user Solutions Architect. The following screenshot shows the query response. In addition to the public channels, the results also include secure channels #security and #well-architected.
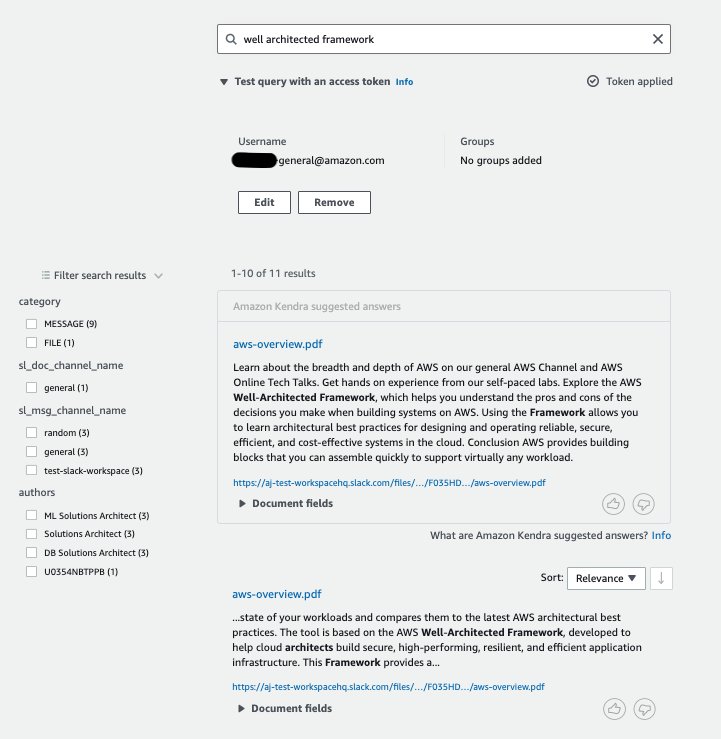
In the next query, we set the user name to be the email address of the ML Solutions Architect. In this case, the results contain the category of THREAD_REPLY in addition to MESSAGE and FILE. Also, ML Solutions Architect can access the secure channel of #machine-learning.

Now for the same query, to review what people have replied to the question, select the THREAD_REPLY category on the left to refine the results. The response now contains only those results that are of the THREAD_REPLY category.

The results from the response include the URL to the Slack message. When you choose the suggested answer result in the response, the URL asks for Slack workspace credentials, and opens the thread reply being referenced.

Clean up
To avoid incurring future costs, clean up the resources you created as part of this solution. If you created a new Amazon Kendra index while testing this solution, delete it. If you only added a new data source using the Amazon Kendra connector for Slack, delete that data source.
Conclusion
Using the Amazon Kendra Slack connector organizations can make invaluable information trapped in their Slack workspaces available to their users securely using intelligent search powered by Amazon Kendra. Additionally, the connector provides facets for Slack workspace attributes such as channels, authors, and categories for the users to interactively refine the search results based on what they’re looking for.
To learn more about the Amazon Kendra connector for Slack, please refer to the section on Amazon Kendra connector for Slack in the Amazon Kendra Developer Guide.
For more information on how you can create, modify, or delete metadata and content when ingesting your data from the Slack workspace, refer to Customizing document metadata during the ingestion process and Enrich your content and metadata to enhance your search experience with custom document enrichment in Amazon Kendra.
About the Author
 Abhinav Jawadekar is a Senior Partner Solutions Architect at Amazon Web Services. Abhinav works with AWS Partners to help them in their cloud journey.
Abhinav Jawadekar is a Senior Partner Solutions Architect at Amazon Web Services. Abhinav works with AWS Partners to help them in their cloud journey.