AWS for M&E Blog
Stream tennis matches through AWS Elemental MediaLive and generate real-time replays with Amazon Rekognition
UPDATE: A new open source solution called Media Replay Engine (MRE) was released to the public that provides a scalable plugin-based framework designed to process live video sources and generate clips and highlights that support several linear and digital channel use cases. You can find it here: https://github.com/awslabs/aws-media-replay-engine.
Broadcasters are increasingly looking to the cloud to reduce operating costs through automation. For example, a live sports event needs to be summarized for replay at a later time. This is traditionally done manually by an editor who watches the whole event and flags the beginning (mark in) and ending (mark out) timestamps of noteworthy segments. These segments are then stitched together to create replays of variable durations. With the latest machine learning (ML) technology, time-consuming tasks like this can be done automatically without human intervention. In this post, we use a tennis match as an example to demonstrate video streaming with AWS Elemental MediaLive and a real-time replay generation with Amazon Rekognition.
Video ingestion through AWS Elemental MediaLive
AWS Elemental MediaLive is a real-time video service that lets you create live outputs from a variety of sources for broadcast and streaming delivery. MediaLive supports ingesting and transcoding video content from both live and on-demand sources. A live video source can be anything from streaming cameras to on-premises encoders directly connected to the internet. For video-on-demand (VOD) sources, the content can be stored in file/object storage, such as Amazon Simple Storage Service (Amazon S3), or made accessible via an HTTP/HTTPS/RTMP endpoint. In our example, the video of the match–an MP4 file stored in an Amazon S3 bucket–is used as an input source for AWS Elemental MediaLive, and it replicates a livestream source for development and testing.

While MediaLive supports a wide range of output types, for this use case we select HTTP Live Streaming (HLS) as the output to Amazon S3.

By enabling this HLS Amazon S3 output option, MediaLive segments the input video into multiple chunks of a specified size (We used 20 seconds in our use case) and stores the chunks in Transport Stream file format (.ts file) in Amazon S3. Every time a new .ts chunk file is generated and uploaded to Amazon S3, MediaLive uploads a new version of multimedia playlist file (.m3u8 file). These Amazon S3 upload events can be used to start an asynchronous, independent processing pipeline for each new HLS video chunk. There are algorithms present in the processing pipeline to identify the need to assess successive chunks if a segment is started but not completed based on the provided logic.
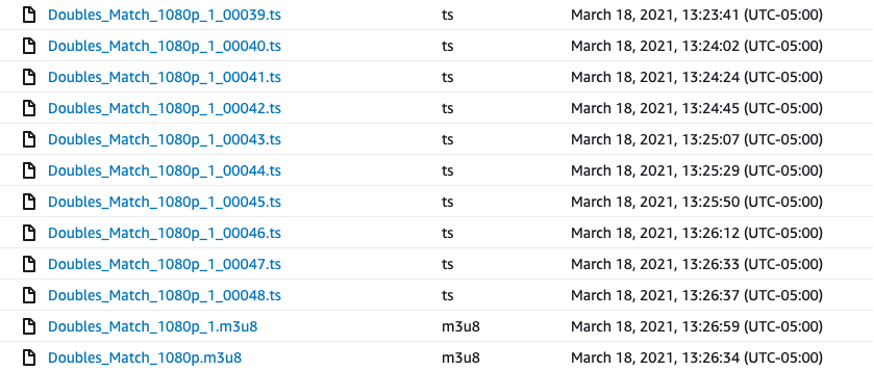
The .m3u8 manifest file contains important metadata about the most recent media segments/chunks stored by MediaLive in Amazon S3. The metadata includes information such as the file names of the chunks (Doubles_Match_1080p_1_00001.ts) and their timing information (EXT-X-PROGRAM-DATE-TIME:2021-03-18T00:00:21.600Z). The following is a sample manifest file:
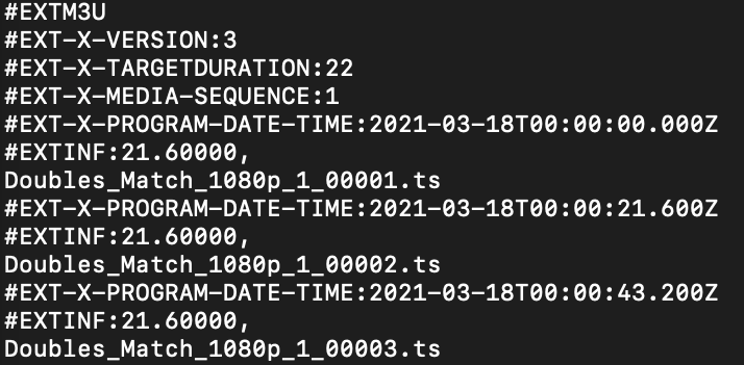
The processing pipeline uses the metadata to identify the video chunk to be processed and, most importantly, to derive the timecode of the video chunk relative to the input video. The timecode metadata is essential in calculating an accurate edit placement relative to the input video, since each chunk outputted by MediaLive starts with a zero-based timestamp (00:00).
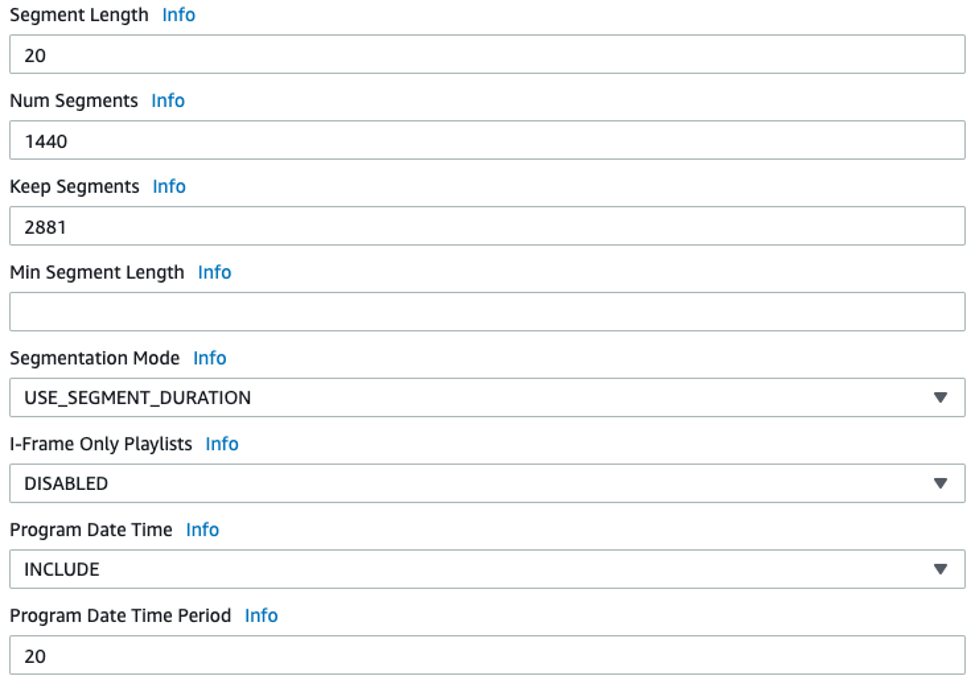
By default, the .m3u8 manifest file does not include the timing information (#EXT-X-PROGRAM-DATE-TIME) of the media chunks stored by MediaLive in Amazon S3. We need to configure HLD output in the “Manifest and Segments” section while creating a MediaLive channel as shown in the following:
Real-time replay segments generation
During a TV broadcast of a tennis match, the director normally gives a closeup view for the serving player, and switches to a wide-angle view (rally view) after the serve until the rally ends. Another closeup view follows the player after a score to show their reaction. Based on these observations, we designed a ML-based algorithm to classify video frame images into different scenes and find the starting and ending time of each tennis rally based on the changing of the scenes. Then, we can extract segments from the video for each rally.
The first step of our replay generation solution is to train an ML model that can perform contextual classification for the frame images. With the help of Amazon Rekognition Custom Labels, we can define our own scene classes and train an image classification model using deep learning technology without requiring ML expertise. Refer to this post for instructions to create an end-to-end pipeline from extracting frame images from a video, creating a training dataset labeling job, to setting up an Amazon Rekognition Custom Labels training project.
Here is an example of training dataset we created. It contains 75 frame images divided into three classes.
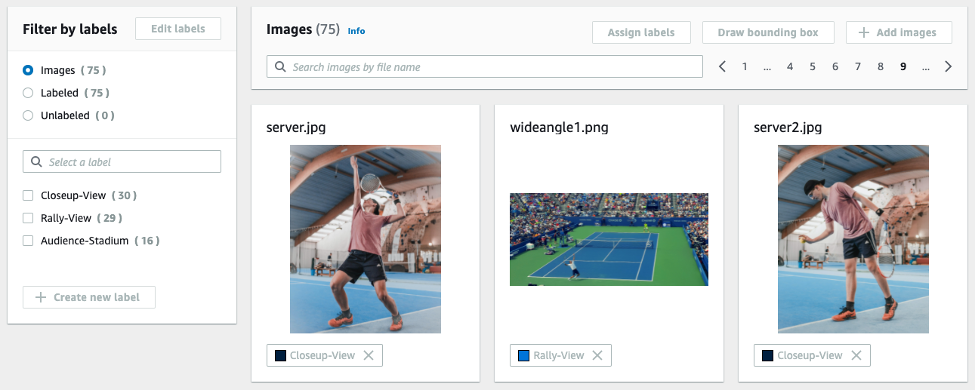
Along with Closeup-View and Rally-View classes, we also created the “Audience-Stadium” class, which is typically shown between game plays.
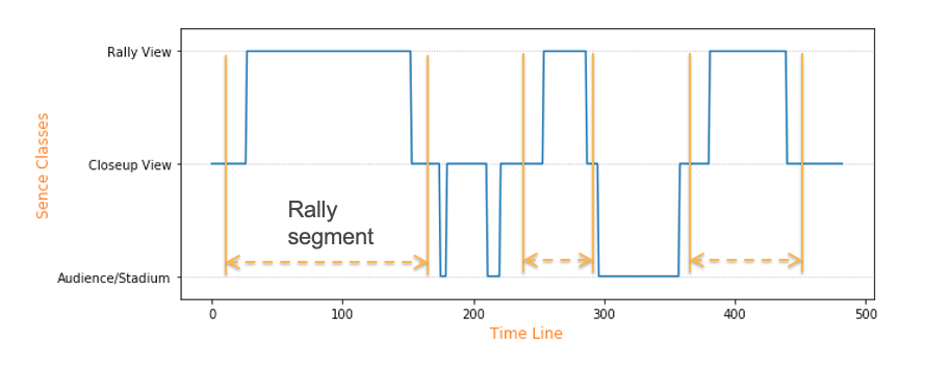
After the model is trained, we apply the model to frame images of a tennis match video and it returns the classes for each frame. The plot blow shows an example of frame image classes along a game timeline. Next, we can design a rule-based segmentation algorithm to find rally segments, which are between two closeup-view scenes, and the beginning and ending time for each segment can be found accordingly.
Further optimization of the segmentation can be added in the workflow to identify the optimal segment edit markers. For example, Silence Detection modular analyzes the audio in the video chunk and detects all the timestamps during which the audio volume is less than a user-configurable noise tolerance value. The timestamps are then used to prevent abrupt segment changes while the announcer is still talking. Scene Change Detection modular detects whenever scene changes happen in the video chunk. For example, when a given frame in the video differs from the previous frame by more than a user-configurable threshold. It helps to avoid frame flickers at the beginning and end of each segment. Score Detection modular extracts score and player information from the match scoreboard with the help of text detection from Amazon Rekognition. The detected scores can be used as the label for the generated segments.
Asynchronous processing pipeline using AWS Step Functions
With MediaLive storing the input video as short duration video pieces or “chunks” in Amazon S3, we use AWS Step Functions to implement an event-driven, asynchronous processing pipeline. Every time a new chunk is stored in Amazon S3 by MediaLive, it triggers the processing pipeline made up of multiple AWS Lambda functions. These functions are implemented either sequentially or in parallel for performing various tasks associated with the AI-based segment generation. This enables a plug-and-play architecture that supports an easy way to build, test, share, and deploy custom code for use-case specific needs. Chunk processing is performed asynchronously, allowing multiple chunks to be handled in parallel.
The processing flow is designed so that every Lambda function in the pipeline gets an input payload, performs the required analysis, enriches the input payload with the result of the analysis, and returns the enriched payload back to the Step Functions. This enriched payload is then passed as an input to the next Lambda function in the pipeline. Sharing the input and output payloads across multiple Lambda functions enables the functions to quickly access all the required metadata (such as the video frame rate, codec) about the input video locally instead of querying the database (Amazon DynamoDB) at every step in the pipeline.
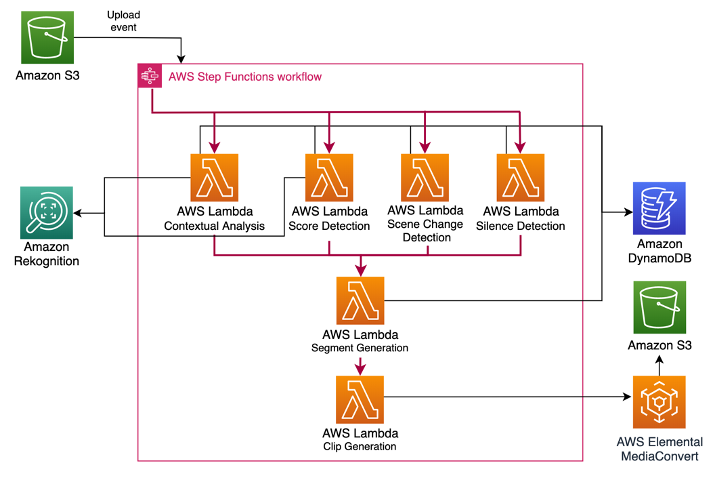
For each new chunk outputted by MediaLive, the pipeline performs Contextual Analysis/Classification, Silence Detection, Scene Detection and Score Detection using different Lambda functions running in parallel. When all functions are complete, the Segment Generation function is invoked with the enriched output collected from all previous functions. The Segment Generation Lambda function then uses the output of Silence and Scene Detection to optimize the original edit placement timestamps outputted by the Contextual Analysis/Classification process.
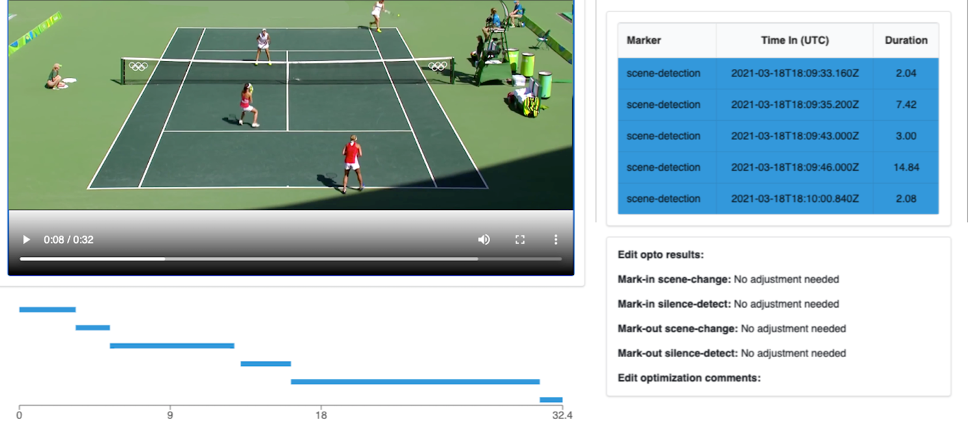
Once both the original and optimized edit placement timestamps are identified, they act as an input to the Clip Generation Lambda, which generates preview clips using AWS Elemental MediaConvert. MediaConvert is a highly scalable video transcoding service for broadcast and multiscreen delivery. In our use case, we use MediaConvert to generate lightweight preview clips for both original and optimized edit placement timestamps from the original high-quality HLS video chunks stored by MediaLive in Amazon S3. The transcoded clips are then displayed to preview the segments in the UI to demonstrate the segmentation accomplished through AI. Here is one example of a final clip generated for a 23-second rally.
Conclusion
In this blog post, we went through how to ingest video through AWS Elemental MediaLive and design an automatic replay generation solution based on ML. The contextual classification model was trained on grass courts, however, tests on other court surface types (clay courts and hard courts) showed promising results. With ML-based scene detection, this solution can be adapted to other sports like table tennis, badminton, and snooker. We are developing a more general AI segmentation solution with a modular plug-and-play architecture, and it will be introduced in the future.