AWS Open Source Blog
Managing compute environments for researchers with Service Workbench on AWS
Through cloud automation, researchers should be able to quickly and securely stand up cloud-based research environments that allow them to shift away from worrying about the technology they are using, and instead focus on their research and collaborating with peers from any institution. Once researchers have secured funding for a project, they must choose from a range of technologies to conduct their research. Researchers often do not have the experience to leverage cloud capabilities to enhance their experiments. In these cases, one option is a multi-step process that involves working with IT staff to discover and design research environments that meet specific needs for data-sharing methods and controls that also will work effectively with external researchers.
Another option is for researchers to cobble together their own solutions. For example, this could involve installing, configuring, and maintaining open source tools; acquiring the experimental data; and defining sharing and collaboration methods. This second option might circumvent IT department security guidelines and poses a risk to an organization’s security and compliance practices. And if researchers are being charged for the cloud technology they actually use, this approach poses challenges for adhering to fixed budgets. Could this time and money be better spent on research?
Automating the creation of baseline research setups, simplifying data access, and providing spend transparency allows IT staff to focus on evolving cloud best practices and research reproducibility over time, while providing researchers with quick and repeatable solutions.
On August 28th, 2020, AWS released Service Workbench on AWS, an open source solution for researchers to deploy data and tools on secure IT environments in minutes. Service Workbench on AWS does not introduce new AWS services; rather, it orchestrates existing services, such as Amazon CloudFront, AWS Lambda, AWS Step Functions, and more. This will then launch compute environments from AWS Service Catalog and allows researchers to launch, access, and manage these environments in minutes with a few clicks.
Service Workbench delivers templates for Hail on Amazon EMR, Jupyter Notebooks on Amazon SageMaker, Amazon Elastic Compute Cloud (Amazon EC2) with Amazon Linux and Microsoft Windows operating system, and Amazon EC2 with Amazon Linux and RStudio. In the future, more workspace templates will be available, but the use of Service Catalog also enables admins to build their own templates and even share them with other organizations.
To control cost, Service Workbench on AWS comes with integration into AWS Cost Explorer, AWS Budgets, and AWS Organizations. This way researchers have quick access to dashboards that show the current use of AWS services against their budgets, set notification thresholds for automated notifications, and can vend new AWS accounts for even more cost transparency. External collaborators can bring their own AWS accounts to spin up compute against their own budgets while using compute environments defined by—and storage provided by—the main researcher or principal investigator (PI).
Service Workbench on AWS integrates with different identity providers, and its open source nature permits adding more—or custom—integrations where needed. Where possible, Service Workbench mimics concepts known to users from on-premises environments to make a switch to cloud technology easier. This includes making data stored in Amazon Simple Storage Service (Amazon S3) available like filesystem mount points to give the impression of a locally managed workstation with local or network-attached storage.
Service Workbench on AWS has been envisioned and built in collaboration with a medical research institution in the United States, where it is used to support researchers and to manage and facilitate virtual classrooms.
Walkthrough
Service Workbench on AWS is a serverless environment that is deployed using an event-driven API framework. Its components are spread across Lambda instances, static webpages using CloudFront and Amazon S3, and uses Amazon Cognito for authentication. Service Workbench relies on Service Catalog to host and manage CloudFormation Templates that define the workspaces that users can launch and use. This makes generating new types of environments and using Service Catalog’s native abilities to share workspace definitions with other institutions easier. Access to data for a workspace is facilitated through Fuse, which allows researchers to store their data in S3 buckets, but use them in their workspaces as if they were mounted filesystems.
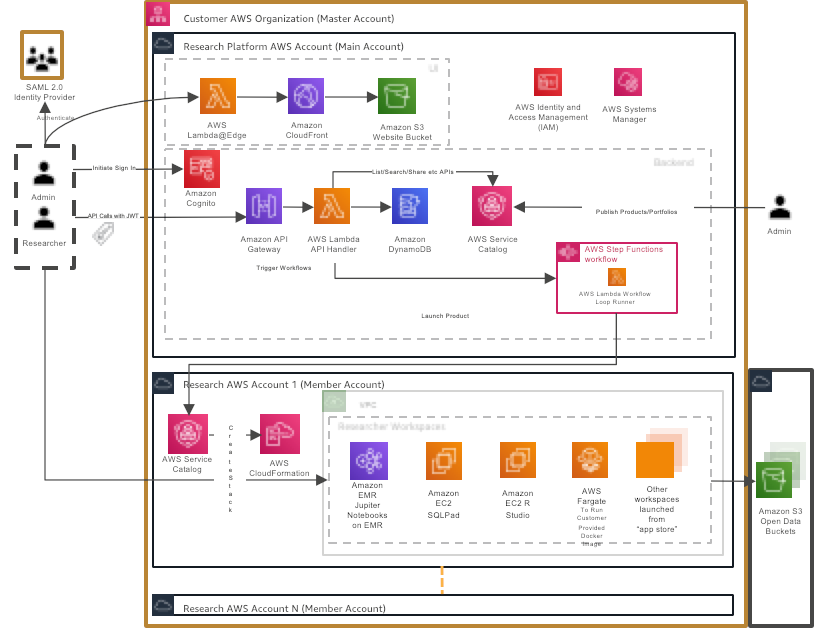
More details regarding the architecture, installation, and configuration can be found in the repository’s README.md file, which also explains how to deploy documentation available in the repository as Docusaurus format. The documentation explains the concepts behind the system and explains, for example, how to connect to a customer’s Active Directory, Auth0 instance, or other means of authentication.
Authentication/authorization
By default, Service Workbench on AWS uses Cognito as a source of authentication. Cognito can federate with different authentication providers, which makes it easier to federate with Active Directory, Auth0, or other identity providers (IDP), for example. If an IDP isn’t supported by Cognito federation, the open source nature of Service Workbench on AWS lets us add custom functionality that connects other identity providers.
Storage
Service Workbench distinguishes between three types of research study data: My Studies, Organizational Studies, and Open Data. Although the former two are datasets stored and maintained either by the individual user or the overall organization or groups therein, Open Data refers to data available through Open Data on AWS. Frequent scans against the open dataset ensures that the latest open datasets are available to users.
In the current form, Service Workbench on AWS stores research-relevant datasets for the first two data types as studies in a central Amazon S3 bucket. Permissions and a folder structure separate the datasets from each other. In future releases, writing data back from environments for individual and organizational data in the same or separate Amazon S3 buckets and using existing S3 buckets as sources for study data will be possible. This will allow for more flexibility and cost efficiency and will be available in December 2020.
Service Catalog
The core of the workspace management in Service Workbench is AWS Service Catalog. Here the system finds and manages the templates that are used to define workspaces. When a user wants to use a new workspace type, it can be created as a CloudFormation Template inside Service Catalog or copied from another organization. Then it is made available to the users for consumption. In this step, admins have the opportunity to validate security and compliance of the template and to define different size definitions for different types of users. Once an administrator makes the template available as a workspace definition, researchers can use the templates at their discretion for their research.
Workspace management
Besides provisioning an environment using templates, a researcher has the ability, at any time, to access their workspaces, connect to them, see billing details, or decommission them.
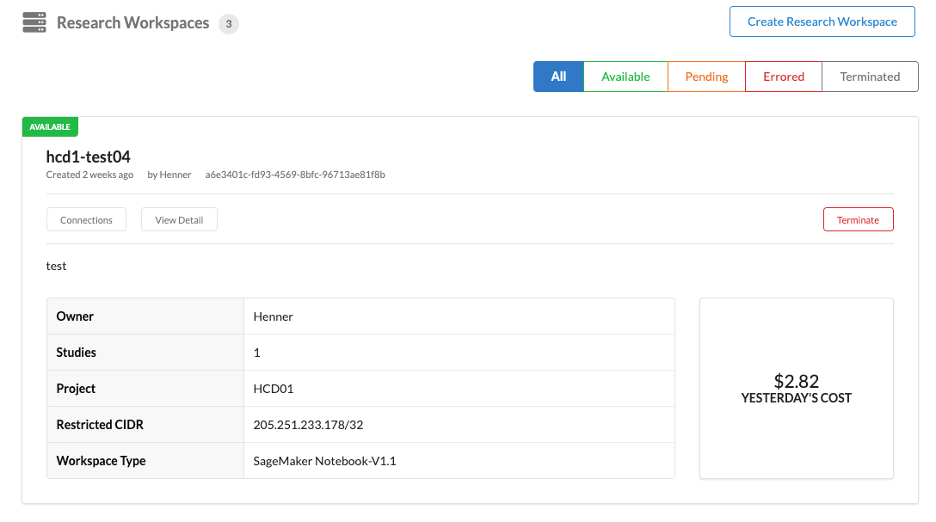
Researchers are also able to pause and resume SageMaker and RStudio workspaces manually or automatically after a configurable idle time in order to gain even more control over cost—for example, when leaving for a vacation.
Cost control
Accounts, indexes, and projects
Service Workbench uses AWS accounts to manage where compute workspaces are launched and managed. This way the user can use different accounts for different projects, cost centers, or another purpose and manage cost in detail. With the vending capability, an administrator can generate new AWS accounts under the same AWS Organizations from inside the Service Workbench interface, without having to switch to a different user interface.
Each account can then be assigned one or multiple indexes or cost centers. These serve to abstract the AWS accounts and create a means for the admin or user to aggregate cost from multiple environments into a more tangible unit than what an AWS account represents.
Beyond indexes, a more granular unit of one or more projects can be associated with every index. This way creating smaller units of work under indexes and abstracting the billing aspect away from end users is possible. For example, assume there is a research project with two research groups, groups A and B. When users from one group create and use workspaces, associating it with the respective group must be possible. Both groups are budgeting against the same cost center/index. In the dashboard, seeing cost accumulated under the index is important. Eventually, all cost generated by these project groups will be billed against one central AWS account that has been created and associated with the index.
Dashboard
A dashboard, conveniently opening on login, allows us a quick overview of the cost our workspaces or projects have accumulated. This can help us to stay on budget and track down workspaces that possibly use up more resources than necessary.
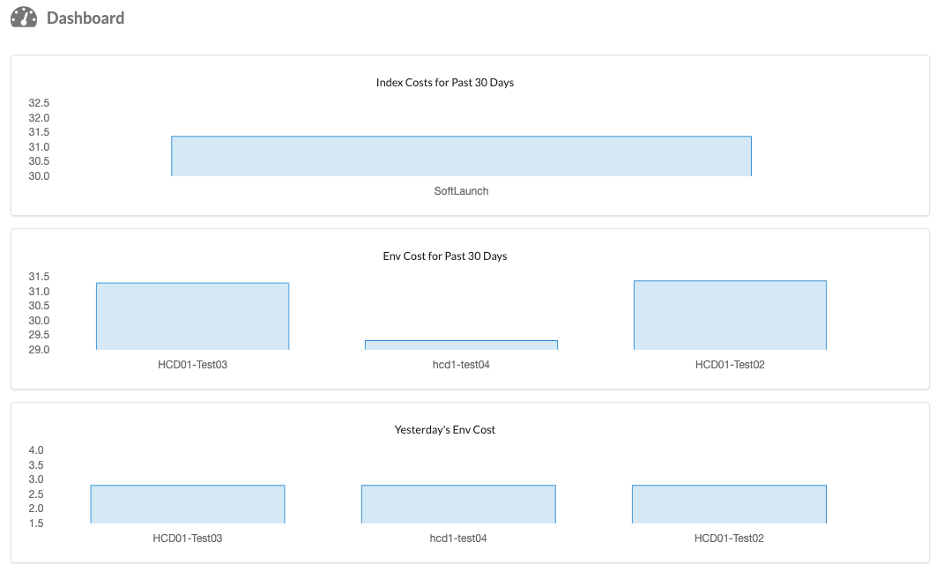
The workspaces are shown by environment and grouped by cost centers/indexes, which allows us to customize how cost is aggregated and align cost management closely with requirements associated to a grant or otherwise fixed budget.
Workspace sizes
When a user creates a workspace from a template, we not only choose the type of workspace, but also are given multiple options of environment sizes to choose from.

An administrator can pre-define these sizes and associate them with users based on individual permissions. This way a student could be given only one option (for example, XS, 1 core, 16GB memory), whereas a Principal Investigator has access to a wide range of sizes, including large (and more costly) environment types.
Access to the source code
The Service Workbench on AWS source code repository is publicly available on GitHub. Clone the repository to access the entirety of its source code and scripts. For detailed documentation, install the Docusaurus installation from the repository as described in the README.md file.
Installation
The GitHub repository contains a README.md file that will be updated regularly with changes to the repository. The README.md file explains prerequisites and the installation process. Using a standardized Amazon EC2 Linux instance as a basis for installation is recommended, to avoid potential incompatibilities with libraries installed on a local system. Using these scripts will create the necessary services and storage locations and will pre-populate the system with required information. It also provisions Cognito for internal login and Amazon DynamoDB, so that the deployment can function immediately after installation.
The repository also contains documentation in the Docusaurus format, which includes instructions for setting up the system, connectivity to identity providers, and end-user guidance. To deploy the Docusaurus documentation, follow the steps in the README.md.
Cleaning up
Service Workbench on AWS also comes with cleanup scripts to remove the services, configurations, and data generated by Service Workbench. This makes it easier, for example, to install development or test environments and remove them after successful tests, while determining functionality to propagate to a production environment.
Conclusion
Service Workbench on AWS is a web frontend that abstracts the complexity of the cloud away from end users, such as researchers who want to focus on research work rather than understanding the cloud. Additionally, Service Workbench on AWS improves collaboration and cost management, which are both essential in a research setting on a fixed budget and in cross-organizational projects.
Service Workbench on AWS also makes research IT staff’s work easier as they can focus on creating templates for research workspace types rather than having to provision every single workspace in the environment.
Service Workbench on AWS installs quickly, and because it is open source software, it allows for extensibility and modifications to suit an organization’s needs.