AWS Storage Blog
How Indus OS cost-effectively transitioned billions of small objects between Amazon S3 storage classes
Indus OS is a mobile platform that enables content and application discovery for users, application developers, and original equipment manufacturers (OEMs). Powered by artificial intelligence, Indus App Bazaar curates locally relevant apps and content for users based on their demographics, lingual preferences, and behaviour, and offers an intuitive user interface with content-led discovery. Indus App Bazaar is currently used by over 200 million users. It currently hosts over 400,000 applications across all its categories, which are available in 12 Indian languages and English.
For content storage, Indus OS uses Amazon S3, which provides easy-to-use, highly performant, scalable, available, and durable storage to meet their high volume of content.
In this post, we discuss how Indus OS optimized storage costs by using S3 storage classes, and reduced the transition cost by 75% when moving billions of small objects from Amazon S3 Standard to Amazon S3 Glacier Flexible Retrieval. We also walk through the overall solution designed to achieve the results.
Challenges and requirements
The Indus OS mobile platform seeks to address the low smartphone adoption, content consumption, and linguistic challenges of Indian markets. Indus OS provides India’s service and content providers a platform to seamlessly distribute their content and services and engage with India’s ever-growing smartphone users.
The team at Indus OS extensively uses the Amazon S3 Standard storage class to meet high performance, scalability, and availability requirements. Currently the mobile platform generates and store billions of small objects in S3 on a daily basis for use cases like log storage and user-generated content.
The team at Indus OS was exploring a solution that could help them keep objects for longer periods to meet their compliance requirements in a cost-effective manner. This led Indus OS to evaluate using S3 Lifecycle to transition objects from S3 Standard to the S3 Glacier Flexible Retrieval storage class to optimize their storage costs. Amazon S3 Lifecycle provides customers with a simple S3 console user interface, or API driven workflow, to define and manage the lifecycle of their Amazon S3 data. S3 Lifecycle allows customers to automate the deletion of specific sets of data when there is no longer a business need to keep them, or transition long lived archive data to lower-cost storage tiers as data become less frequently accessed. For Indus OS, because they wanted to transition billions of small files, and S3 Lifecycle transition costs are driven by the number of objects transitioned, using S3 Lifecycle was not the recommended solution.
Indus OS collaborated with AWS to solve this problem, ultimately resulting in 75% cost savings in transitioning millions of small S3 objects to S3 Glacier Flexible Retrieval.
Solution overview and walkthrough
The solution is based on a serverless infrastructure and follows an event-driven architecture. This solution offers the following functionality as REST APIs:
- Archival API: Combines multiple small files to a fused .zip file before moving it to S3 Glacier Flexible Retrieval (this solution can also be used to transition data to the other S3 Glacier storage classes). The solution intelligently indexes the objects and stores them in Amazon DynamoDB. The indexes are further looked up during the restore operation.
- Restore API: Performs restoration of a file using the original object key, which restores objects and makes them available in S3 Standard, ensuring the original object prefix is preserved.
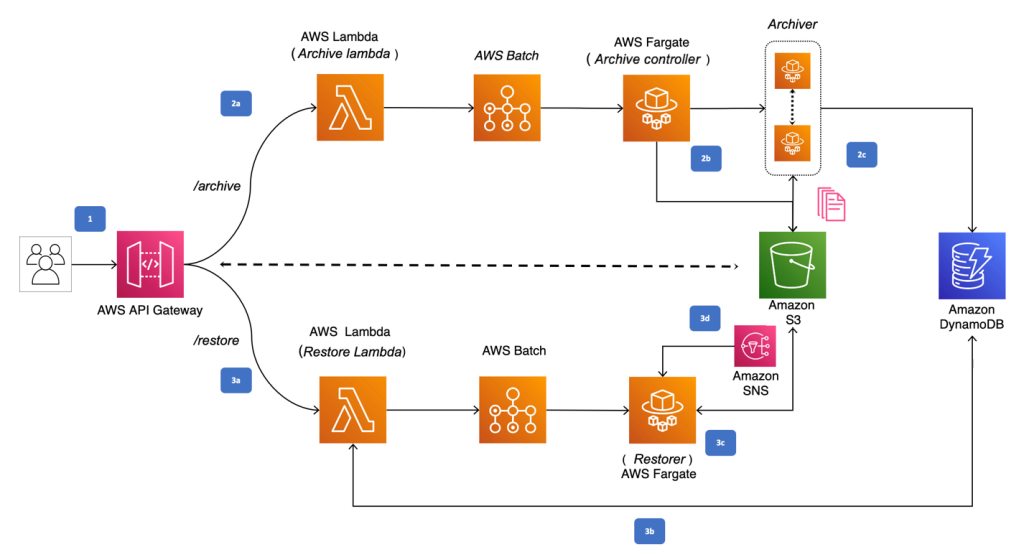
The preceding diagram depicts the architecture pattern that enabled Indus OS to move billions of small size object from Amazon S3 Standard to S3 Glacier Flexible Retrieval. The steps for the solution shown are as follows:
1. Perform either archive or restore REST operation using the appropriate Amazon API Gateway. API Gateway delegates the request to appropriate AWS Lambda for processing. The two lambda functions are Archive Lambda and Restore Lambda.
2a. Archive Lambda, upon receiving the archive request payload holding information like S3 bucket info, prefix, fusing rules, output destination and output storage class, validates the request and creates an AWS Batch job called Archive Controller. For this implementation, AWS Batch uses AWS Fargate to run containers without having to manage servers or clusters of Amazon EC2 instances.
2b. Archive Controller job introspects the archival request and performs the S3 List operation on the given S3 bucket and prefix to create multiple AWS Batch Archiver jobs based on the archiving rules provided. For example, if the prefix contains 20 objects and the fusing rules instructs for 10 objects to be fused into one, then Archive Controller creates 2 Archiver AWS Batch jobs to perform the fusing of 10 objects each.
2c. Archiver job downloads all the objects to be fused from the S3 bucket and fuses them into one .zip file. The fused .zip file is then uploaded back to the S3 bucket in payload-instructed output destination. Archiver also creates indexing of all the fused objects in Amazon DynamoDB, which will be used for the restore workflow.
3a. Restore Lambda, upon receiving the restore request payload holding information like the S3 bucket, object key, and retrieval tier, validates the request.
3b. Restore Lambda looks up the DynamoDB table to know which fused .zip file the provided object key belongs to and its details. Restore Lambda performs the restore operation on the fused .zip file and triggers the Restorer AWS Batch job once the fused file is staged for access.
3c. Restorer downloads the restored fused .zip file and extracts only the specific object key instructed in the payload to makes specific object available in standard storage class, preserving the original prefix of the object.
3d. Restorer, upon making the requested object key available in S3 Standard, will send out the SNS notifications to subscribers.
Conclusion
In this post, we explained how AWS helped Indus OS deploy a highly scalable, reliable solution that helped Indus OS transition a massive number of small objects to the S3 Glacier Flexible Retrieval storage class in a cost-effective way.
Using this solution, Indus OS could achieve a 75% data-transition cost reduction while transitioning 2,000,000 small objects to archive storage. This is on top of the savings acheived by moving the files from Amazon S3 Standard to the Amazon S3 Glacier storage classes, which are purpose-built for data archiving, providing the highest performance, most retrieval flexibility, and the lowest cost archive storage in the cloud.
As a next step, Indus OS is planning to migrate 1 billion files to S3 Glacier Flexible Retrieval using this solution. This will help manage an ever-increasing amount of data using this solution in a cost effective way.
Thanks for reading this blog post! If you have any questions or suggestions, please leave your feedback in the comments section.