AWS Big Data Blog
Author: Prasad Alle
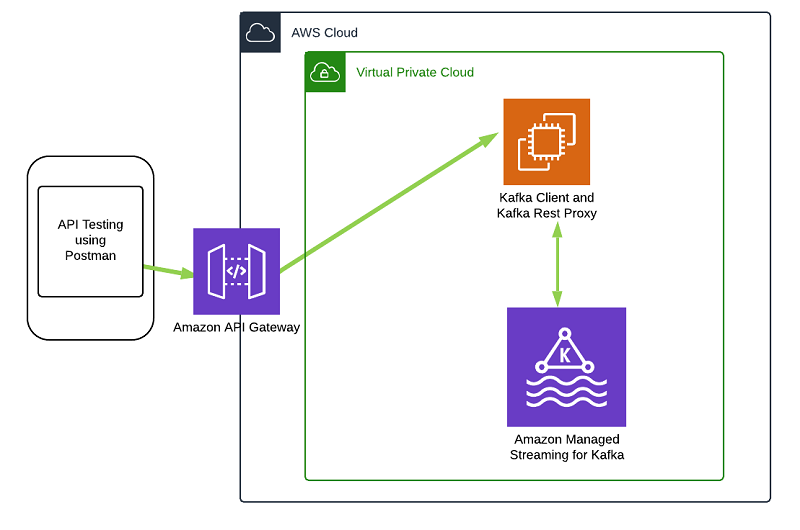
Govern how your clients interact with Apache Kafka using API Gateway
In this blog post, we will show you how Amazon API Gateway can answer these questions as a component between your Amazon MSK cluster and your clients. Amazon MSK is a fully managed service for Apache Kafka that makes it easy to provision Kafka clusters with just a few clicks without the need to provision servers, manage storage, or configure Apache Zookeeper manually. Apache Kafka is an open-source platform for building real-time streaming data pipelines and applications.

Implement continuous integration and delivery of serverless AWS Glue ETL applications using AWS Developer Tools
In this post, I walk you through a solution that implements a CI/CD pipeline for serverless AWS Glue ETL applications supported by AWS Developer Tools (including AWS CodePipeline, AWS CodeCommit, and AWS CodeBuild) and AWS CloudFormation.

Best Practices for Running Apache Kafka on AWS
The best practices described in this post are based on our experience in running and operating large-scale Kafka clusters on AWS for more than two years. Our intent for this post is to help AWS customers who are currently running Kafka on AWS, and also customers who are considering migrating on-premises Kafka deployments to AWS.
Best Practices for Running Apache Cassandra on Amazon EC2
In this post, we outline three Cassandra deployment options, as well as provide guidance about determining the best practices for your use case.
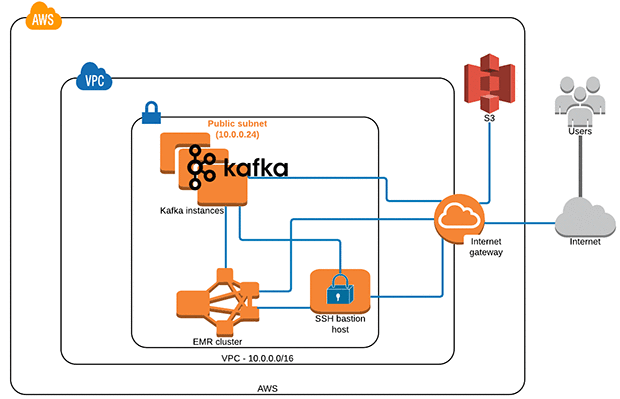
Real-time Stream Processing Using Apache Spark Streaming and Apache Kafka on AWS
This post demonstrates how to set up Apache Kafka on EC2, use Spark Streaming on EMR to process data coming in to Apache Kafka topics, and query streaming data using Spark SQL on EMR.