AWS for Industries
Derive AI/ML-driven insights from healthcare data using Amazon HealthLake
Last year, we announced Amazon HealthLake, a new HIPAA-eligible service for healthcare providers, health insurance companies, and pharmaceutical companies to securely store, transform, query, analyze, and share health data in the cloud, at petabyte scale. We launched HealthLake to address one of the key challenges that the health industry – from healthcare payers to life sciences companies – has long had: efficiently deriving insights from health data.
Machine learning (ML) is a powerful tool for addressing this challenge, as it is well suited for deriving insights at scale from both structured and non-structured data alike. For example, medical professionals often capture important information about the treatment of a patient in unstructured fields such as clinical notes. Without the use of ML, extracting this information is a time-consuming and manual process. By leveraging cutting edge advances in ML applications such as natural language processing (NLP), structured information can be identified and extracted from unstructured data like clinical notes in a highly scalable way. Through the use of ML, millions of records can be analyzed in a fraction of the time it takes to do manually. This unlocks exciting new opportunities for healthcare providers to make patient support decisions, design better clinical trials, and operate more efficiently.
HealthLake removes the heavy lifting of organizing, indexing, and structuring patient information to provide a complete view of the health of individual patients and entire patient populations in a secure, compliant, and auditable manner. It transforms unstructured data using specialized ML models trained on medical examples to automatically understand and extract meaningful medical information from the data. The service also provides powerful query and search capabilities. HealthLake organizes, indexes and stores health data in the Fast Healthcare Interoperability Resources (FHIR) industry standard format to provide a standard way of organizing and sharing the information. The FHIR standard helps builders of the system better understand which data is relevant and how it should be organized, and also enables interoperability.
AI/ML-powered health data insights application overview
In this post, we explore the Health Data Insights application – a demo built by the Amazon ML Solutions Lab to show how HealthLake forms a foundation for building data rich, ML-powered analyses of medical information. The Health Data Insights application leverages HealthLake as the primary datastore to store and search health data. Also, we demonstrate key ML-powered features of HealthLake, such as its ability to use NLP to extract notes from unstructured data such as clinical notes and encounter transcriptions.
Patient Dashboard: Visualizing data & identifying trends
In a clinical setting, it is essential that the care team can quickly and easily access all relevant information about the patient. However, interacting with digital healthcare systems is the complexity of interacting with traditional EHR systems is one of the most common points of friction for healthcare professionals. For a clinician, this means having access to all relevant patient information while simultaneously being able to navigate through this information with ease. HealthLake provides an organized foundation upon which dashboards can be custom built for different stakeholders, all with their own sets of unique requirements. Let’s first focus on an example of a dashboard designed specifically for a clinician.
The Patient Dashboard can serve as the entry point for healthcare professionals to get an overall view of particular patient’s Health Data Insights. By querying HealthLake, we can retrieve the entire patient history such as medical conditions, medications and their dosage as well as details on treatments and procedures. A timeline view in the patient dashboard presents Patient Clinical Events in a chronological order to give the healthcare team insights into the patient journey.
Additional information for the encounter is made available by clicking on the link located on the bottom right corner of the encounter tooltip. This will open a new page that contains all the information available, as well as any related document or notes related to the encounter as seen in Figure 2: Encounter Drawer.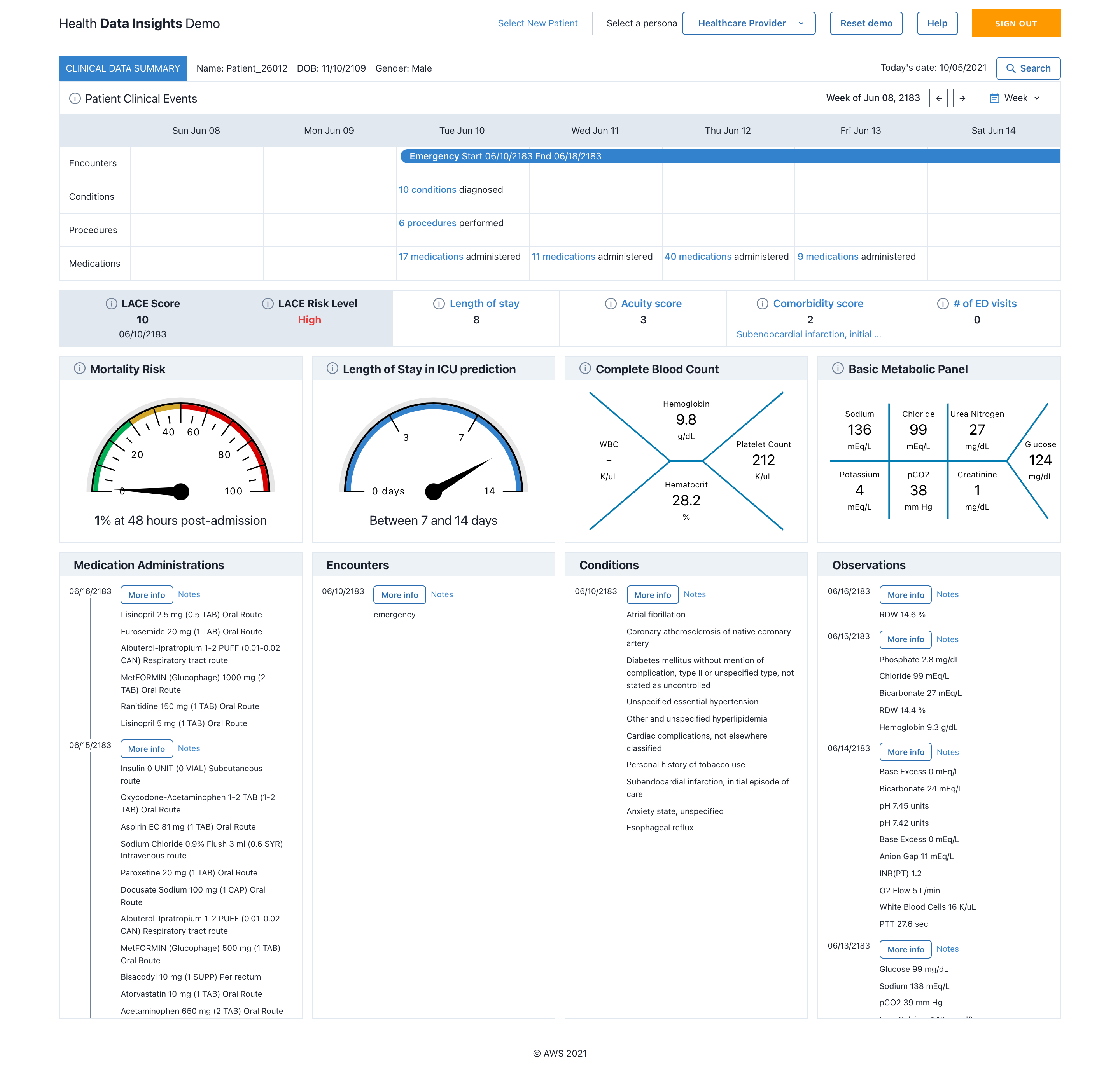
Figure 1. Patient dashboard showing sample demo application’s interface built using Amazon Healthlake
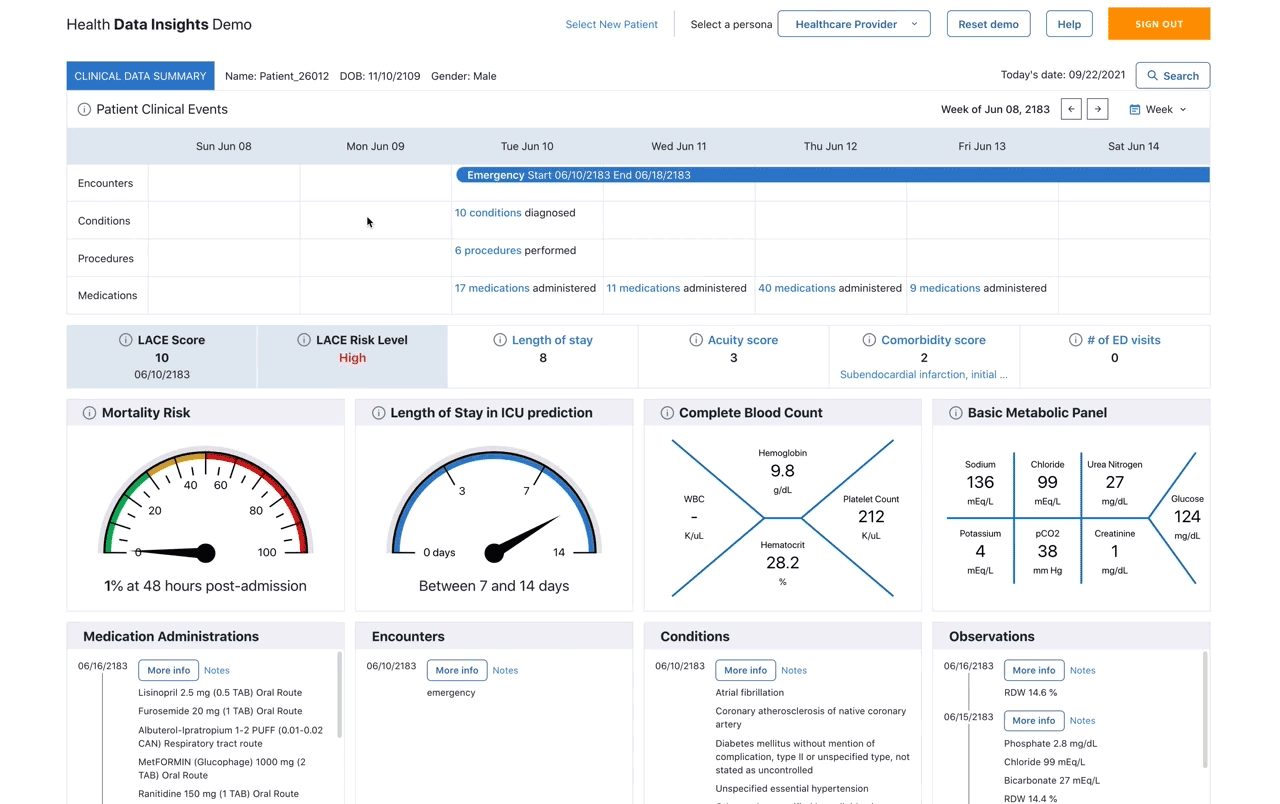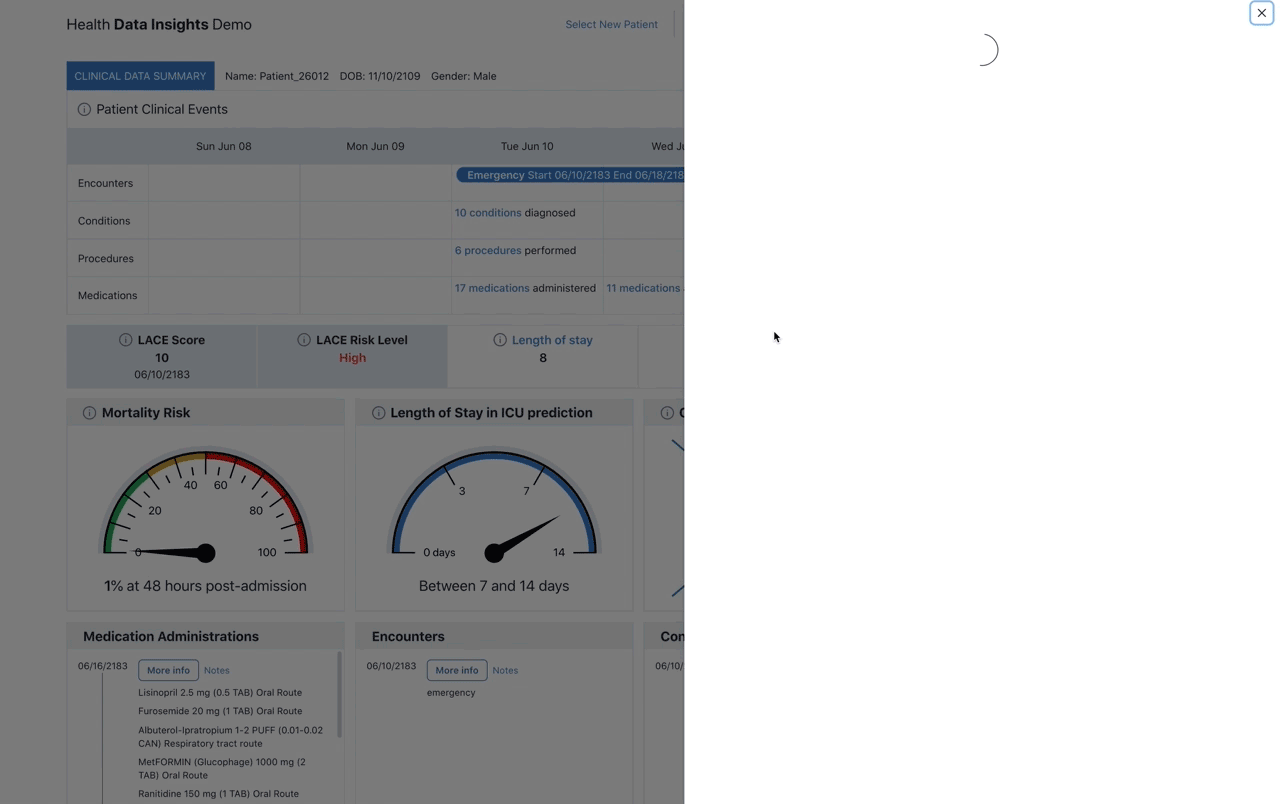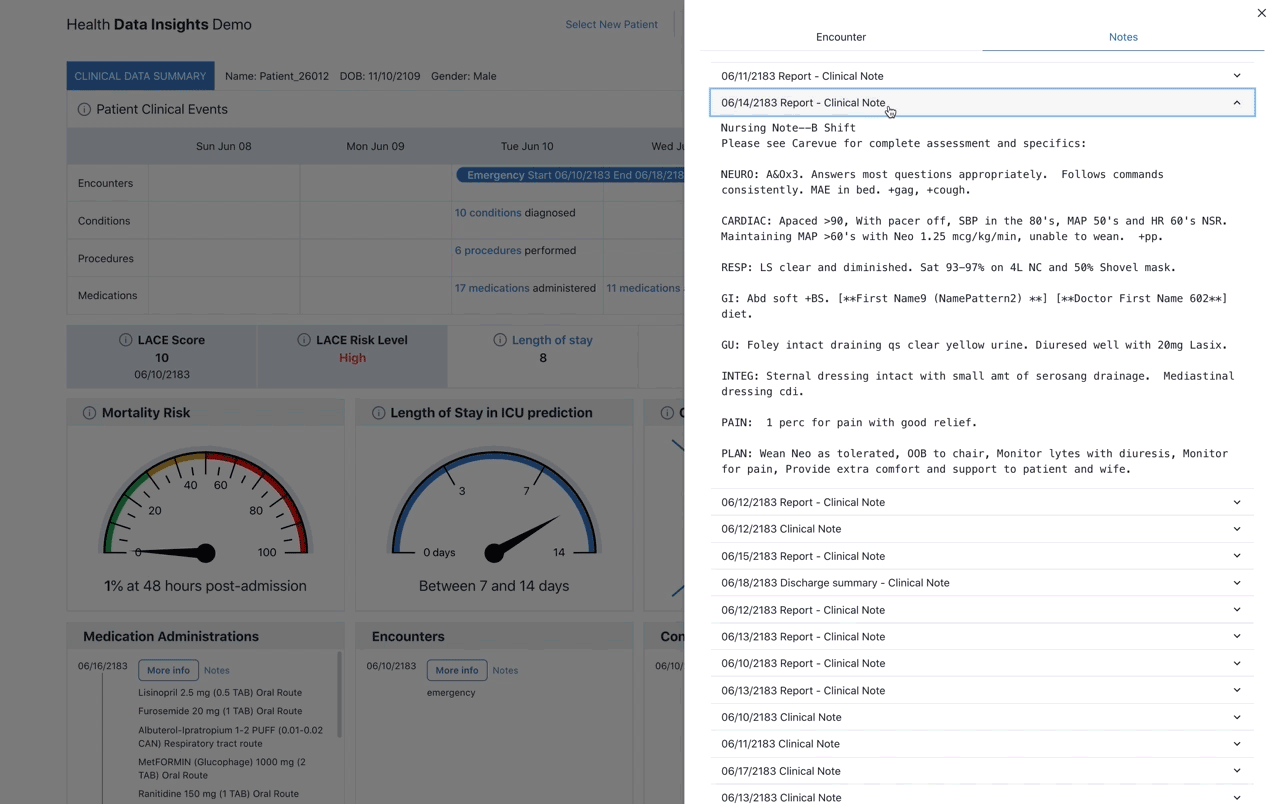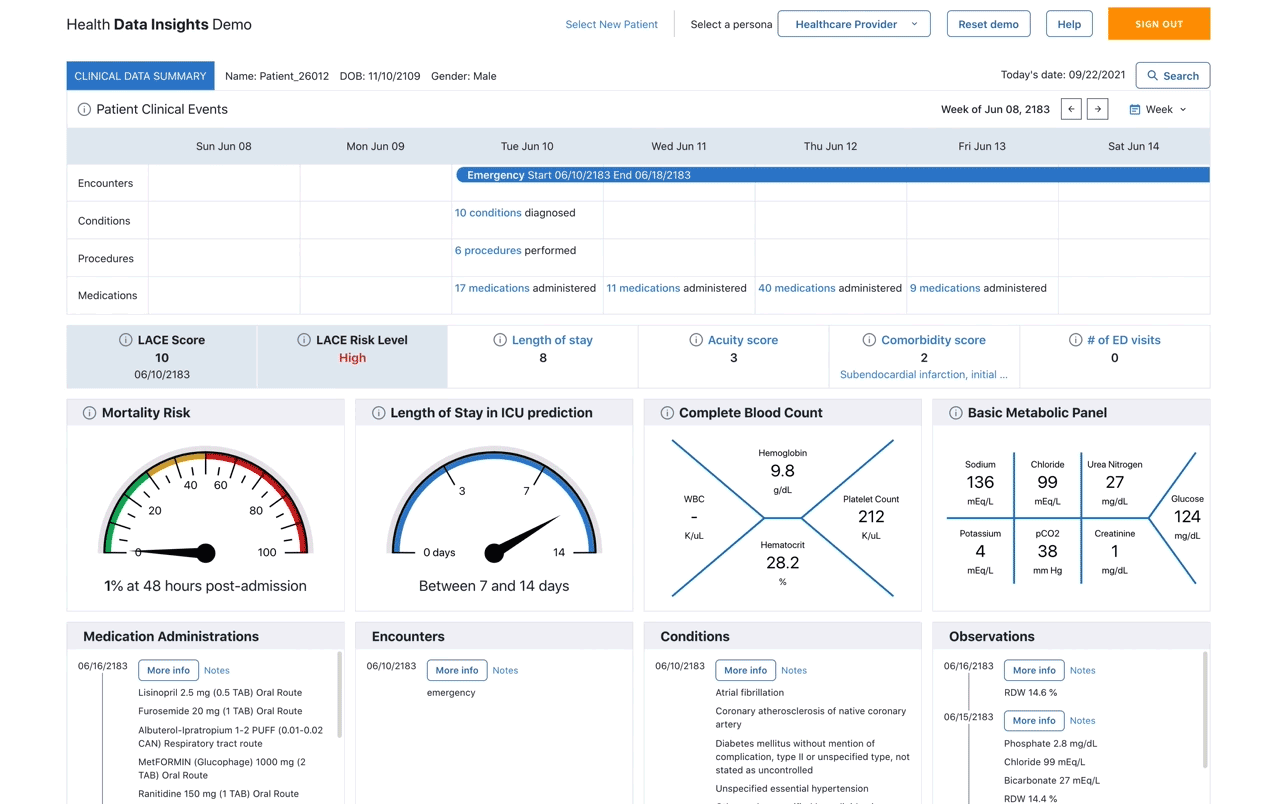
Figure 2. Encounter drawer
The sample Health Data Insights demo application leverages the FHIR Search API that is available in HealthLake to populate all the dashboard components. An example of the underlying query string on HealthLake to return Medical Conditions for a patient id would look similar to:
https://healthlake.<aws-region>.amazonaws.com/datastore/<datastore-id>/r4/Condition?subject=Patient/<patient-id>
Harnessing the power of Natural Language Processing (NLP) & automation of clinical workflows
HealthLake automatically uses NLP to extract structured information from unstructured text stored in the DocumentReference resource type given in the FHIR specification. This means is that as FHIR documents are ingested into HealthLake, they are inspected for the DocumentReference resource type. If this resource is included in a document, an integrated ML-based NLP model is automatically used to extract structured information from the text contained within the field. No additional coding or ML expertise is required to take advantage of this feature. Here’s a concrete example of how this helps healthcare professionals.
Consider a telehealth encounter between clinician and a patient. Historically, someone (a scribe, an assistant or the doctor) takes notes during the encounter, and once the transcription is made available, a doctor or domain expert extracts the critical pieces of information from the transcribed notes of the encounter. Through the use of ML, it is now possible to automate this manual process. First, we can employ a service like Amazon Transcribe Medical, an automatic speech recognition (ASR) service enabled by machine learning, to automatically transcribe the encounter dialogue. Second, using HealthLake, we leverage NLP to extract entities corresponding to Protected Health Information (PHI), medical conditions, medications and tests, treatments and procedures from the transcription. Moreover, HealthLake automatically associates these entities with related information like ICD-10-CM (a standard for encoding medical conditions and symptoms) and RX-Norm (a standard for encoding medications). The inferences from the NLP model are structured and mapped to the appropriate ontology and provided as an extension that is searchable using the DocumentReference resource type in accordance with the FHIR specification. This further enriches the patient’s medical history record. Finally, each extracted entity during the NLP process is assigned a confidence score that allows customers to maintain data quality standards by setting configurable “trust” thresholds for these scores. If the NLP output doesn’t meet a certain confidence score, it can be ignored or sent to a medical practitioner for manual review (a process known as “human in the loop” in ML parlance).
Integrated NLP with Amazon HealthLake is an example of the results generated by HealthLake for an encounter and its related encounter transcriptions and clinical notes (Figure 3). Here, Health Data Insights uses the insights extracted from HealthLake, compares them to see which medical entities are missing in the existing records and then tags the missed entities as auto-discovered. The entities can be compared using string-matching or comparing corresponding concepts such as ICD-10-CM codes for medical conditions and RX-Norm codes for medications. Having additional information that was missed in the initial records can provide valuable insights that can help healthcare professionals take better decisions.
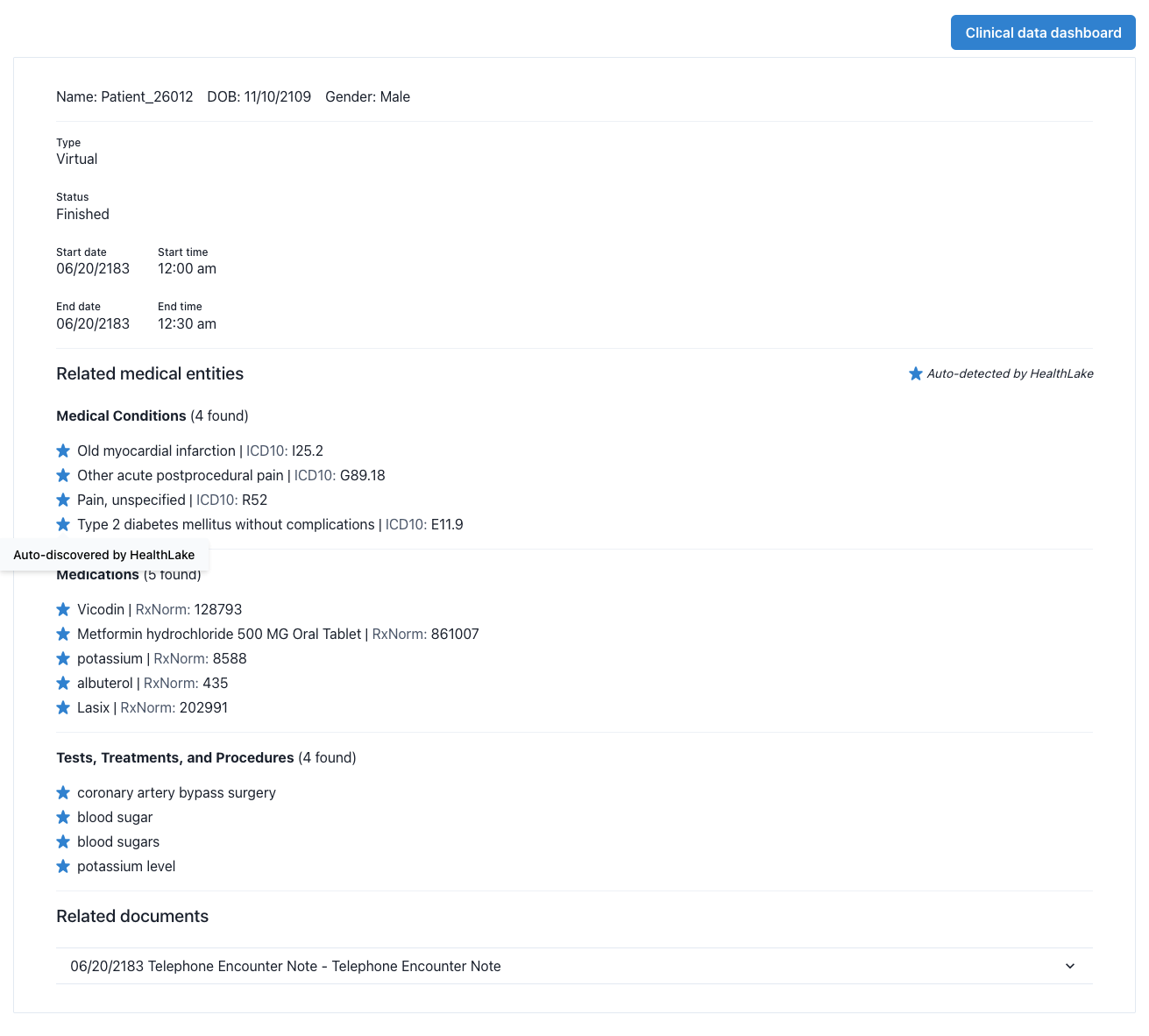
Figure 3: Integrated NLP with Amazon HealthLake
One crucial callout here is that this integrated NLP is not only available for any newly created documents on HealthLake but also for any DocumentReference resources previously created and ingested into HealthLake. This means customers can now import their historical data into HealthLake and uncover new insights that were previously difficult or impossible to derive, in turn promoting data-driven decision making.
For more information, see Integrated medical natural language processing (NLP) for Amazon HealthLake.
Population dashboard : Visualizing Data & Applying Advanced Analytics on Population data
Data analysis is critical in the field of Healthcare. HealthLake helps healthcare organizations analyze population health trends, outcomes, and costs with machine learning and analytics tools. For example, organizations can easily create a cohort of patients and their treatments, demographics, and tests with an interactive dashboard in Amazon QuickSight to understand patient and population-level trends and display quantitative data in an easy to understand format so that the users without the knowledge of complex technical software can also use it to make data-driven decisions.

Figure 4: Population Dashboard
Population Dashboard is an example of one such dashboard catered to the needs of a healthcare administrator. To create this dashboard, Health Data Insights uses data exported from HealthLake that gives us a complete view of all of the patient’s attributes such as Medications, tests, procedures, encounters and diagnoses.
Using this data, we can create analytics like the average encounter length across all patient admissions, the top conditions across all patients by gender, average age of patients at the time of admission, number of encounters within a specific time period and so on which are then presented in the dashboard. Using QuickSight to create dashboards, users of the dashboard can leverage the interactive analytical tools available to easily gain deeper insights into the data. You can find more information about embedding QuickSight dashboards into applications here.
Application architecture
The Health Data Insights demo application architecture defines a standard web-serving tier utilizing Amazon CloudFront and Amazon API Gateway. These edge services, which provide low-latency access through caching and geo-proximity, communicate with the HealthLake and Amazon Transcribe Medical services running in an AWS region. Amazon Lambda, a service providing “serverless” code execution is used to implement microservices that orchestrate the calls to HealthLake and Amazon Transcribe. Enriched data in HealthLake can be periodically exported to Amazon S3 which can be optionally used to train custom health prediction models using Amazon SageMaker. From these models, SageMaker batch transform is used to make the custom model predictions, which are made available to the application via Amazon DynamoDB, a flexible and scalable NoSQL database.
Data can be exported from HealthLake for further analytics and visualizations. AWS Glue is used to extract, transform and load (ETL) the exported data and also catalog the data. Amazon Athena is being used for querying this catalog and also serves as the data source for Amazon QuickSight used for creating the population level dashboards. This dashboard is embedded into the web application using the QuickSight Embedding SDK.
For the high-level overview of the application architecture, refer to Figure 5: Architecture Diagram.
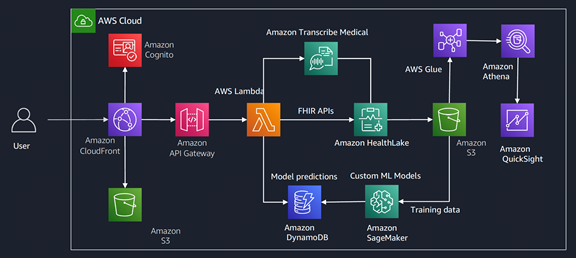
Figure 5. Architecture Diagram
Conclusion
In this blog post, we showed how we can use HealthLake to create a sample Health Data Insights application. We demonstrated how HealthLake’s NLP capabilities can be utilized to automatically identify the most relevant information from unstructured data including medical conditions, medications, and procedures, which can in turn help healthcare providers to automate health data processing workflows and enable them to derive additional AI/ML driven insights for making data driven-decisions. Additionally, we also demonstrated how HealthLake enables builders to develop an easy-to-use interface to view data and automate the medical comprehension process, therefore reducing the workload making it easier for healthcare professionals to focus on patient care.
Amazon HealthLake is available today in the US East (N. Virginia), US East (Ohio), and US West (Oregon) Regions. To learn more, try out our self-paced workshop.