AWS Partner Network (APN) Blog
Accelerate Computer-Aided Engineering Workloads with Hybrid Cloud HPC Scenarios
By Holger Gantikow, Chief Architect HPCaaS – Atos Science + Computing Unit
By Florian Heimgärtner, Sr. IT Consultant HPC – Atos Science + Computing Unit
By Hakan Korkmaz, Sr. Partner Solutions Architect – AWS
By Torsten Bloth, Sr. HPC Specialist – AWS
 |
| Atos |
 |
As a long-standing partner of automotive and life science companies, the Atos Science + Computing Unit specializes in providing customers with tailor-made and demand-driven high-performance computing (HPC) solutions. This includes the integration of cloud resources to efficiently achieve customers’ performance and business objectives.
Atos Science + Computing’s customers benefit from many years of domain understanding and technical expertise, particularly when it comes to transforming resources into solutions that are fully integrated into the customer’s HPC, computer-aided engineering (CAE), and data analytics IT environments.
In this post, we describe two hybrid HPC deployments. While both are transparently integrated with the traditional workload manager that controls existing on-premises HPC resources, they are distinguished by entirely different approaches.
These solutions were chosen to provide the strongest possible fit to the respective requirements and make use of the possible flexibility in a hybrid scenario:
- Target Architecture A: This targets a highly dynamic environment in which only occasional peak loads are handled in the cloud and the resources are not required to be active the rest of the time. This approach relies on AWS ParallelCluster, an AWS-provided HPC cluster management tool that enables automated and dynamic provisioning of HPC resources.
- Target Architecture B: This serves as a constantly-used extension of an HPC environment on premises. It consequently reproduces characteristics of the customer environment as closely as possible in the cloud to make integration as transparent as possible.
Atos International is an AWS Advanced Tier Services Partner and Managed Cloud Services Provider (MSP) that supports clients’ digital ambitions and believes that bringing together people, business, and technology is the way forward.
The Atos Science + Computing Unit offers IT services, solutions, and software for the efficient use of complex computer environments in research, development, and computation. Its customers include manufacturers and suppliers in the automotive, microelectronics, aerospace, and pharmaceutics sectors, as well as scientific research institutes.
Atos Science + Computing helps customers focus on their core business objectives by providing an efficient, cost-effective, and resilient IT infrastructure.
Background
The development processes of today’s innovations rely on high-performance computing as a key technology to progress from idea to product. HPC has evolved over time from a specialized tool primarily used in research facilities to a widely-used technology with a strong foothold in commercial environments.
In order to make use of HPC, many research institutions and companies have invested in large compute clusters over time, most of which are operated on premises. However, these installations have limited ability to handle sporadically occurring peak loads.
Another challenge is an overall increase in computing resource requirements—due to additional projects, for example—as the procurement process for additional cluster resources is often laborious and time-consuming.
Leveraging cloud resources can mitigate these limitations by providing an easy way to access additional resources in hybrid scenarios. The cloud also provides quick access to the latest technologies on the market that are not yet available in their on-site installation. This can include acceleration cards or the latest generation processors that reduce the time required for computation.
By selecting instance types that are efficiently matched to the workloads at hand (more cores vs. faster cores or use of faster disks), the overall computation time can be shortened.
It’s also possible to rely on the most appropriate instance type exclusively for individual phases of a workflow, and thus only pay for it when it’s used. This flexibility to choose between a variety of different systems is often not available in on-premises installations, as the deployed systems are often much more homogeneous.
For particularly time-critical calculations, there is the option to benefit from the elasticity of the cloud and distribute a process over a larger number of resources and obtain results in a significantly shorter time.
Organizations can reduce the waiting time for free computing resources altogether by adding more nodes to the queue. However, application-specific scaling and licensing restrictions may apply here.
Target Architecture A: Elastic Support of Peak Loads in CFD Simulations
In terms of cost-effectiveness, the perfect dimensioning of an HPC cluster would be targeted at a permanent close to 100% load during regular operating hours. However, HPC user groups, such as CAE research and development departments, do not typically generate a continuously consistent HPC workload.
Even though job queues may run empty during weekends or business breaks, capacity limits are quickly reached as project deadlines approach. Packed queues and the associated waiting time until a simulation is started can lead to frustration as well as project delays.
Managing Peak Demand – When On Premises is Not Enough
To handle temporary peak loads, a hybrid setup can be a smart alternative to hardware upgrades and a system that becomes even more oversized on a day-to-day basis.
The local on-premises system is dimensioned in way that it can easily handle the day-to-day workload, but when load peaks occur resources in the cloud are automatically activated and used to avoid bottlenecks and delays. Once the peak load has been processed, the cloud cluster is modified and the excess cloud resources are simply shut down again.
The deployment presented below implements exactly such a dynamic and cost-efficient scenario. A local compute cluster located on the corporate premises and a cloud cluster running on Amazon Web Services (AWS) are interconnected. Figure 1 provides an overview of the setup.
Key Aspects of Implementation
Both the local and cloud cluster use the Slurm workload manager. Slurm supports the concept of federation which enables a transparent submit of compute jobs from on-premises to the remote Slurm cluster. Hence, HPC users can work with standard tools for job submission or status monitoring regardless of whether the job is scheduled on the local cluster or in the cloud.
The cloud cluster is created using AWS ParallelCluster, and this open-source cluster management tool supported by AWS simplifies cloud resource provisioning and provides support for auto scaling of resources, which is a key feature of this approach.
Additional configuration adjustments are implemented using post-installation scripts. For example, connecting the Slurm controller node of the cloud cluster to the on-premises SlurmDBD Database Daemon, or distributing authentication keys.
Utilized AWS Services
Job input data is transferred to the cloud cluster by pushing it into an Amazon Simple Storage Service (Amazon S3) bucket. The content of the bucket is presented to the cluster as a Lustre file system using Amazon FSx for Lustre. To transfer job output data back to the on-premises file system, a second Amazon S3 bucket is used.
As long as the cloud cluster is idle, the only resource that needs to remain powered on and utilized on AWS is the Slurm controller node. Compute node Amazon Elastic Compute Cloud (Amazon EC2) instances are created and terminated on demand using the Slurm power save feature that was originally intended for suspending and resuming physical compute nodes.
Multi-node jobs relying on message passing interface (MPI) for inter-node communication are accelerated by relying on the Elastic Fabric Adapter (EFA) network interface. This high-performance interconnect provides performance comparable to InfiniBand and is essential to run HPC applications at scale on AWS.
The local HPC cluster is connected to the Amazon Virtual Private Cloud (Amazon VPC) of the cloud cluster via AWS Site-to-Site VPN.
Workload + Licenses On Demand
The predominant workload used in this setup is Simcenter Star-CCM+ which is a popular computational fluid dynamics (CFD) solver. It is licensed by Simcenter STAR-CCM+ Power On Demand (POD).
This step solves the problem that software licenses are usually acquired exactly in line with the on-premises hardware resources. This means when these resources are fully utilized, there are no more available licenses that can be used in the cloud.
POD offers a pay-per-use scheme, which is used here for resources running on AWS by accessing a cloud license service operated by the software vendor. This way, the cloud cluster can handle the peak workload requiring neither connectivity to the on-premises license servers nor an extension of the license pool.
To simplify the application deployment, Atos has foreseen a containerized operation based on the Singularity container engine and optional use of Amazon Elastic Container Registry (Amazon ECR).
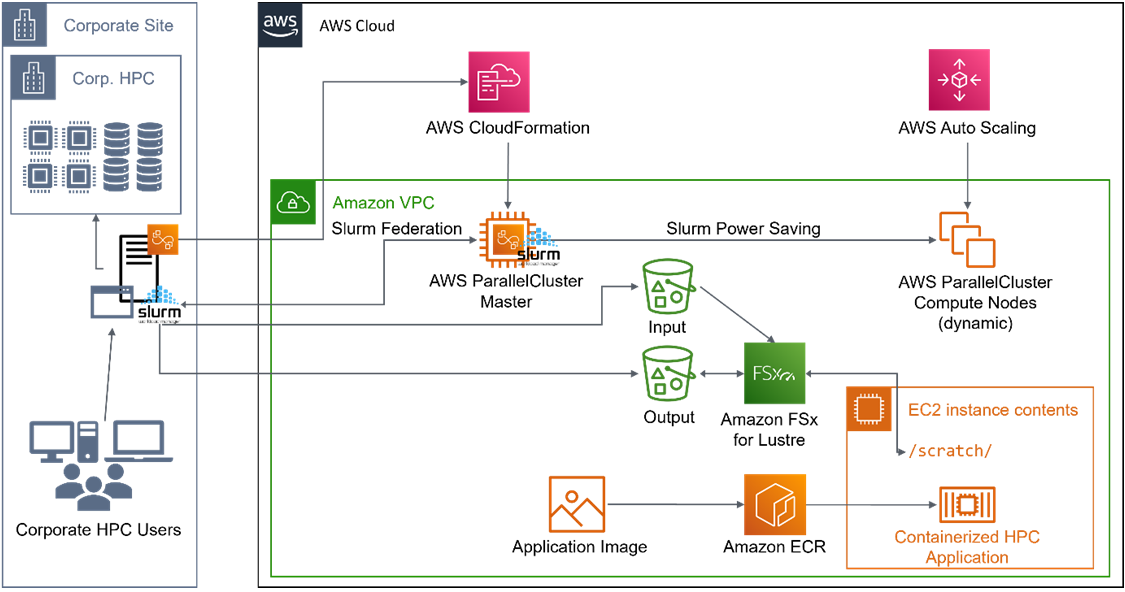
Figure 1 – Hybrid CFD simulation architecture using AWS ParallelCluster.
Target Architecture B: Permanent Cluster Extension by Cloud Resources
In this approach, cloud resources serve as a permanent extension of the on-premises compute cluster and are constantly used for a variety of CAE applications, mostly LS-Dyna and Abaqus.
Given the permanent nature of this setup, a key feature is that cloud resources are integrated into the on-premises environment as closely as possible. As a result, operational tasks for the different resources are carried out using the same configuration management tool, and access to certain central infrastructure services, such as the company-wide license server, are also utilized from the cloud.
Key Aspects of Implementation
The cloud resources are structured in a way that mimics the concept of compute cells used in the on-premises cluster. A compute cell represents a partially isolated sub-cluster consisting of several distinct elements:
- Gateway: Used for communication with resources outside the cell, such as license servers and transfer servers for providing result data.
- File server: Provide shared scratch storage and the HPC applications over network file system (NFS).
- Compute nodes: Interconnected via different networks for different types of traffic, such as regular TCP/IP or MPI.
Utilized AWS Services
The feature set of the file server is provided by the AWS cloud storage service Amazon Elastic File System (Amazon EFS), which can dynamically grow and shrink as needed.
Amazon EFS is provided to the compute nodes as a scratch and HPC software repository, and to the transfer nodes through which the input and output data of a job is transferred between the on-premises environment in the corporate network and the cloud.
Due to the accessibility from the transfer servers, Amazon EFS is located in a separate subnet, as shown in Figure 2.
The customer environment and cloud HPC environment are connected via AWS Direct Connect. Restricting communication to well-defined endpoints and additionally securing this link via OpenVPN point-to-point connections provides that customer requirements regarding the confidentiality of data in transit are met.
The confidentiality of the data at rest is provided by encryption. Thus, all compute instances are configured with encrypted disks, and Amazon EFS is configured to use encryption as well.
Workload management and job orchestration is performed by a Grid Engine-based workload manger in combination with a custom workflow engine combining the customers’ own HPC resources and resources on AWS in a centralized location.
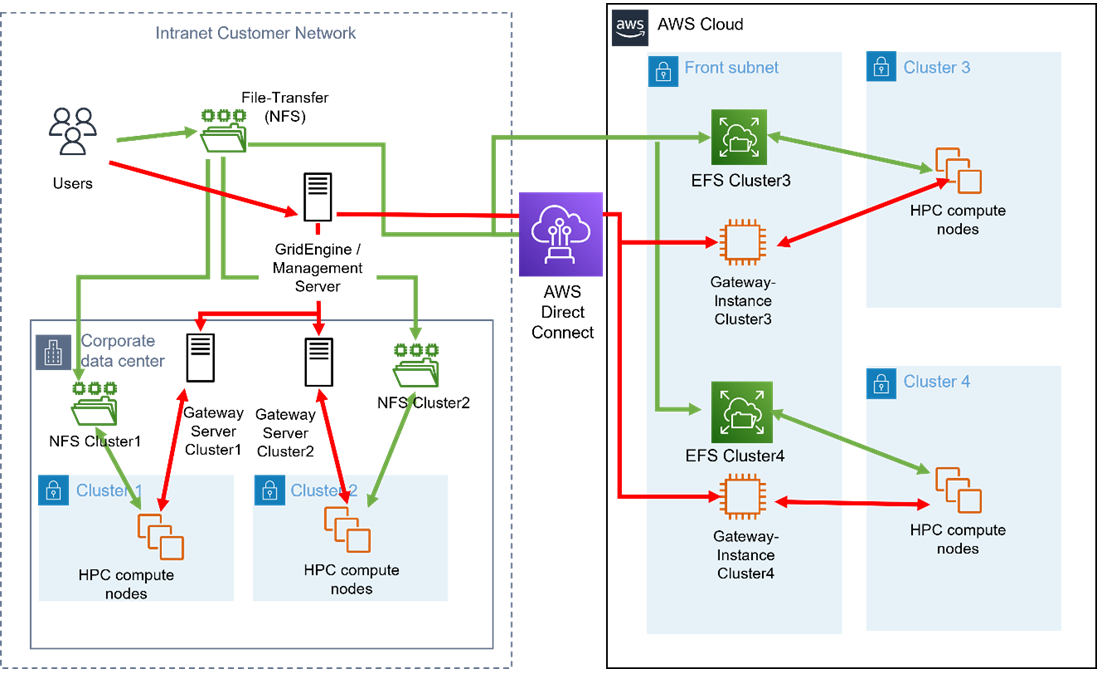
Figure 2 – Hybrid cloud HPC environment consisting of multiple sub-clusters.
Results Achieved
The different solutions implemented provide real benefits for customers:
- Access to additional resources to increase the capacity of their compute environment.
- Transparent integration into existing workflows and overall environment.
- Flexibility to optimize resources to best fit the desired workload.
- Possibility to simply switch off idle resources (pay-as-you-go model).
- Fulfillment of the customer privacy and security requirements, especially for data in transit and at rest.
- Proven workflows combined with technology and resources enable state-of-the-art HPC environments in the cloud.
Summary
The hybrid cloud HPC approaches implemented by the Atos Science + Computing Unit shows the high flexibility, adaptability, and expandability of such a solution.
The question today is no longer whether high-performance computing (HPC) in the cloud really works, but what setup best suits the workload and how far it should be integrated into the existing environment. For instance, in the examples we have shown in this post, cloud resources are primarily used as an extension of the compute environment; further processing of the data takes place again in the on-premises environment, which is not necessarily required given the technical possibilities.
Nowadays, from a technical point of view, there is nothing that speaks against moving one’s post-processing to the cloud, as long as it’s compliant with the operating model, for example.
Atos has already supported customers in moving their complete computer-aided engineering (CAE) workstations—including desktops with many cores, a lot of memory, fast local storage, and a powerful graphics card—to the AWS Cloud in order to offer maximum flexibility in a work-from-home scenario.
A further boost in flexibility is possible by the application of HPC cloud enabler technology, such as Nimbix, now part of Atos, which provides capabilities for advanced computing workflows through software such as JARVICE while offering the option to offload to public clouds for additional resources.
.

.
Atos – AWS Partner Spotlight
Atos is an AWS Advanced Tier Services Partner and MSP that supports clients’ digital ambitions and believes that bringing together people, business, and technology is the way forward.