AWS Partner Network (APN) Blog
Building a Single Source of Truth with a Data Hub from Semarchy
By Anna Rider, Customer Success Consultant at Semarchy
By Joel Knight, Sr. Consultant, Infrastructure Architecture at AWS
By Leonardo Gomez, Sr. Analytics Solutions Architect at AWS
 |
 |
Every day, organizations experience a deluge of data coming from disparate sources. Data silos emerge, which leads to inconsistent and incomplete information.
Instead of leveraging data as an asset, these organizations are struggling to record customer interactions, process new sources of product information, and integrate third-party data for their marketing efforts.
When organizations create homegrown data quality tools to fix bad data, the processes are usually brittle, costly to maintain, and can’t standardize data across every silo.
The challenge (and opportunity) that companies face is how to build a trusted source of truth quickly so they can intelligently organize their customers, products, assets, and other domains that are imperative to running operations and delivering business intelligence.
Organizations need a comprehensive data management solution that includes data quality, cleansing, de-duplication, and curation capabilities. After consolidating trusted golden records, they need to enforce governance requirements and track changes over time.
That’s why Amazon Web Services (AWS) customers are looking to Semarchy, an AWS Select Technology Partner. Semarchy’s xDM platform is an innovation in multi-vector Master Data Management (MDM) that leverages smart algorithms and material design to simplify data stewardship, governance, and integration.
In this post, we’ll share examples of how organizations are relying on Semarchy xDM and AWS to build an intelligent data hub and create a centralized repository to manage business-critical data.
The Challenge of Data Governance
Organizations are constantly ingesting, creating, and managing massive amounts of data. This data comes from different sources and is stored across multiple systems.
For example, relational data can be spread across multiple relational databases in Amazon Relational Database Service (Amazon RDS), while key-value data lives in Amazon DynamoDB and unstructured data is stored in Amazon Simple Storage Service (Amazon S3).
While storing data in different locations using different data models doesn’t necessarily present a problem on its own, it becomes a challenge when the data actually contains the same information. It can pose an even greater challenge when needing to identify which information to use.
For example, one application could store the address for customers using “Alberta” and “California” spelled out. Another system could store the abbreviated names “AB” and “CA.” This difference makes it hard to join queries across different source systems. Additionally, rolling up data to these regions for reporting is difficult.
But who is responsible for fixing these inconsistencies? Which format does the organization use as the standard moving forward?
The answer lies in robust data governance. According to CIO.com, data governance is “a system for defining who within an organization has authority and control over data assets and how those data assets may be used. It encompasses the people, processes, and technologies required to manage and protect data assets.”
Organizations with good data governance know where to find trusted information and understand the procedures they must follow to maintain the integrity of data.
Some benefits of data governance include greater transparency and empowering business users to maintain data within their departments instead of overburdening IT with change requests.
Good data governance increases the business value of an organization’s data and plays a core role in helping any organization achieve its goals, whether that’s cutting costs, growing revenue, or increasing efficiency.
While data governance is partly about rules and enforcement, it’s also necessary to have a platform to help enforce these governance requirements. Semarchy xDM stores definitions, enforces data quality rules, and orchestrates collaboration among business users to ensure good data governance is carried out.
xDM is designed with user-friendly interfaces so the business feels empowered to own and maintain their data.

Figure 1 – Data steward workflows for auditing matching, merging, and survivorship.
Data Quality
Organizations are striving for good data quality because it’s foundational to important decision making.
Consider how common data quality issues, such as misspellings in customer addresses or typos in email addresses, can affect customer information. This inconsistent, incomplete, and unreliable customer data can lead to mistargeted marketing campaigns, poor customer experiences, and costly manual work to fix the data.
Enforcing the data quality requirements as they are defined in the data governance framework is a core part of Semarchy xDM. For example, customers can transform data in xDM to format values or convert them to the phoneticized version of a string.
They can also call out to external data services, such as Google Maps and Melissa Personator, to standardize and augment data. These popular datasets can geocode addresses, format contact information, and add demographic data.
Additionally, xDM enables organizations to enrich data using both built-in rules and external data sources. For example, a joint Semarchy and AWS customer processes data for hundreds of thousands of beverages sold in the U.S. Their xDM implementation integrates with a Digital Asset Management system hosted on Amazon S3 to process the images on bottle labels for their clients.
Before using xDM, this customer had human data stewards review the images to determine if there were nudity or offensive imagery on the bottle labels. This was a slow, tedious, and expensive process because of the large volume of images that require review.
Semarchy provided a plugin that allowed them to send images to Amazon Rekognition, a machine learning service which makes it easy to add image and video analysis to applications, in order to moderate the bottle labels for nudity.
The data quality process uses the capabilities in Amazon Rekognition to flag labels containing nudity or other objectionable content so they can be sent for human review. This significantly cut down the amount of time data stewards spent manually looking through the library of images.
As a result, this customer reduced the costs associated with maintaining images while scaling their moderation operations, all without decreasing accuracy.
Golden Records
Many organizations have data scattered in different systems. Off-the-shelf applications are often architected with vastly different data models, making it a challenge to share a uniform view across the organization’s data landscape. Compounding this problem is the amount of duplicate data, which makes it hard to track, manage, and trust the data.
Consider the example of a high-performance bicycle that can go by different names. The supply chain system stores a different set of product attributes and breaks down the bicycles by their components and subcomponents. The finance system looks at the sales data of a fully assembled bike, whereas the ecommerce system bundles assembled bikes with accessories, further complicating the product line.
Even with a unique SKU, it’s a challenge to bring the data together in a consolidated view and track the history of the data as the product evolves. This makes it difficult to answer a seemingly simple question of “Which bike or bike bundle is the best seller in the previous quarter?”
These difficulties lead organizations to seek out a single source of truth so they can better manage, track, and drive value from their data.
xDM can solve problems like duplicate customer records and inconsistent data scattered in different source systems using its matching engine.
Organizations define match rules following their data governance requirements. xDM’s high-performance matching engine supports fully-customizable exact match rules and fuzzy-matching algorithms with adjustable scoring.
These agreed-upon rules automate the process of identifying duplicate records, matching them, and merging them. Next, survivorship rules determine which values should win in the consolidation process when creating golden records. Survivorship rules also govern whether manual overrides are allowed, so that data stewards can retain control of the golden records.
The resulting golden records represent the best-of-breed combination of values from the different source systems. Having this trusted, single view of the bike product data is part of the process to identify best sellers. The matching engine not only handles product and customer data but also matches and consolidates party, location, supplier, household, employee data, and many more domains.
Workflow and Collaboration
A large part of creating trustworthy golden records is the ability to perform data maintenance tasks. Data maintenance is the process business users follow to execute data governance policies. This includes data creation, updates, validations, and manual merges and splits of matched records to ensure data is managed and curated over time.
Equally important is the data stewardship process, which governs the interpretation and enforcement of policies as defined in the data governance framework. It’s critical that organizations have a robust tool that encourages business users to manage their own data so they don’t have to rely on IT for every change.
xDM encourages collaborative maintenance and stewardship by offering business-friendly human workflows and graphical interfaces that intuitively guide business users to take action on improving the data.
Part of the workflow is live validation. This is essential to data quality because it blocks the user from entering bad data into the system and guides users to choose predefined values from an approved list.
For example, if a company is adding a new food offering to its menu, the xDM workflows guide predefined personas that are granted the appropriate permissions to make changes to the new food’s data.
The workflow starts with the product team who is responsible for entering the new food item’s attributes. Then, the marketing team receives a notification to add the marketing description and photography. The workflow prompts the nutrition team to add the nutritional facts.
Finally, the workflow directs the test kitchen and supervisor to review and approve this new item on the menu. Each user is notified of updates so team members stay informed as the menu item launches.
xDM captures an audit trail so it’s possible to trace the author of each change and the reasons for the change. Tracking the historical data is critical to understanding how data evolves and ensures there is accountability.
As a result, organizations feel confident about allowing their business users to manage, author, and update data compared to the legacy, unintegrated processes.
Consuming from the Intelligent Data Hub
After golden records are created, organizations consume these records in third-party applications, such as the enterprise data warehouse, business intelligence (BI) tools, and the customer relationship management (CRM) system.
Some organizations choose to write the golden data back to source systems. Updating the source data improves data quality so that business users interacting with data from source systems can benefit from trustworthy data, rather than keeping the golden records siloed in the data hub.
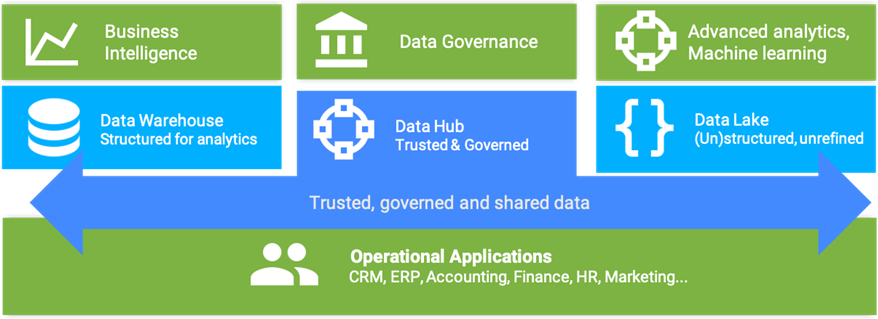
Figure 2 – The data hub is central to, and extends across, the data landscape.
Because organizations are dealing with complex data architectures, the intelligent data hub is designed to provide multiple points of integration to support different architectural needs.
For example, the data science team will have different needs compared to the data engineering team, which in turn is different from the BI team. xDM running on AWS supports all of these use cases in a number of different ways:
- By connecting directly to the Amazon RDS database xDM uses as its data store, xDM data (including golden records) can be directly consumed by extract, transform, and load (ETL) tools such as AWS Glue, BI tools, and any system that supports the underlying database engine type.
- By making the data available in Amazon S3 using RDS’s snapshot export feature, data scientists can bring that data into their machine learning workflows in Amazon SageMaker.
- BI teams and data scientists alike can issue SQL queries via Amazon Athena to query xDM data. Using Athena, these consumers can also federate their queries against data residing in other relational, non-relational, object, or custom data sources.
- BI teams can use Amazon QuickSight to quickly create dashboards and drive insights from xDM’s data.
xDM enables multiple points of access to the data hub. The open database architecture exposes all of the data in the intelligent data hub. This includes the source records, golden records, even the historical data snapshots. It allows any application to query and consume any data in the intelligent data hub using SQL.
Another way to integrate with the data is using xDM’s auto-generated RESTful API that matches the enterprise’s unique data model. This allows organizations to integrate in near-real time to consume and push records into the data hub.
As an example, a consumer electronics company uses xDM hosted on AWS to integrate its data hub with the call center application and point of sale (POS) system. This integration via REST API allows the company to look up customers’ information as they call in for warranty help, or for a store to look up their purchase history to provide a better customer experience.
Customers also use xDM’s capability to build custom REST endpoints to facilitate their consumption of the data in a microservices application architecture. This means sending data to the intelligent data hub on the fly to validate it, enrich it, or query potential matches based on the existing golden data in the hub.
The REST-based integration is ideal for a “search before create” architecture where organizations can check if the customer already exists in xDM before creating a duplicate record in CRM.
The microservices can also enrich and validate the data before the record is persisted in the source systems. Commonly used to integrate with CRM systems, this “search before create” use case prevents duplicate data and allows CRM users to get the latest consolidated view of a customer from the intelligent data hub.
Customer Success: Chipotle
Chipotle, the quick-service restaurant, has more than 2,700 locations worldwide, including in the United States, Canada, United Kingdom, France, and Germany.
Chipotle needed a flexible platform to manage its restaurant locations. The company deployed xDM to manage location data, which included consolidated data from multiple sources and enriching it with external datasets.
Thanks to the success of their project, Chipotle expanded the data hub to cover other process-centric data, such as development of new menu items, tax regulations, and supply chain. This helps the company minimize manual costs for data maintenance and reduce health and environmental regulatory compliance risks.
As a result, Chipotle increased brand awareness and digital innovation by centralizing accurate information on stores and menus and improving customer experience. The data hub has prepared the foundation to support the restaurant chain’s exponential digital and international growth.
To learn more about Chipotle’s experience, check out Semarchy’s client success stories.
Next Steps
With Semarchy, you can build trusted data applications quickly, with fast time to value using a single software platform for governance, golden data, reference data, data quality, enrichment, and workflows.
Get started with Semarchy xDM on AWS Marketplace >>
.

.
Semarchy – AWS Partner Spotlight
Semarchy is an AWS Select Technology Partner and intelligent Master Data Management (MDM) company. Its xDM platform is an innovation in multi-vector MDM that leverages smart algorithms and material design to simplify data stewardship, governance, and integration.
Contact Semarchy | Partner Overview | AWS Marketplace
*Already worked with Semarchy? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.