AWS Partner Network (APN) Blog
Building an Agile Business Rules Engine on AWS
By Kalyan Purkayashta, Sr. Manager – Capgemini
By Rakesh Porwad, Manager – Capgemini
By Vikas Nambiar, Manager, Partner Solutions Architect – AWS
 |
| Capgemini |
 |
Mutual or insurance companies are often governed by members and have business and/or membership rules that govern membership grants. Such rules are classified as Inclusion rules and Exclusion rules.
Inclusion rules are business rules that reward customers who meet certain criterion, such as purchase of bonds or high-value financial instruments, and tenure or association with the company.
Conversely, Exclusion rules are defined to update/grant/revoke membership based on member activities, such as purchasing a certain products or product types, or having a secondary role on the product (particularly products that have joint holdings).
When implemented in legacy on-premises systems, such rules tend to be rigid in nature and impact business agility. Business users who depend on the IT department to make rule changes and updates triggered by changing business or regulatory requirements need to plan for development resource availability, change management, rules development lead times, and associated project costs.
This inhibits an organization’s ability to be agile and serve their members efficiently, expand memberships, and adapt quickly to changing business or regulatory requirements.
In this post, we will explore how Capgemini uses Amazon Web Services (AWS) to build a simple, agile, and configurable solution that implement business and membership rules on customer or master data. This is further improved using metadata to introduce or amend additional business rules.
Such a design pattern can be easily customized to additional business use case; not just customers or members.
Capgemini is an AWS Premier Consulting Partner and Managed Service Provider (MSP) with a multicultural team of 220,000 people in 40+ countries. Capgemini has more than 12,000 AWS accreditations and over 4,900 active AWS Certifications.
High-Level Architecture
The diagram below depicts the high-level architecture of a rules-based engine on AWS. The main components of this architecture are:
- Rules repository that stores business rules.
- Data store that hosts customer records or customer master.
- Processing engine.
- Data store to capture the results of the processing and maintain a member register.
- End-to-end workflow orchestration mechanism.
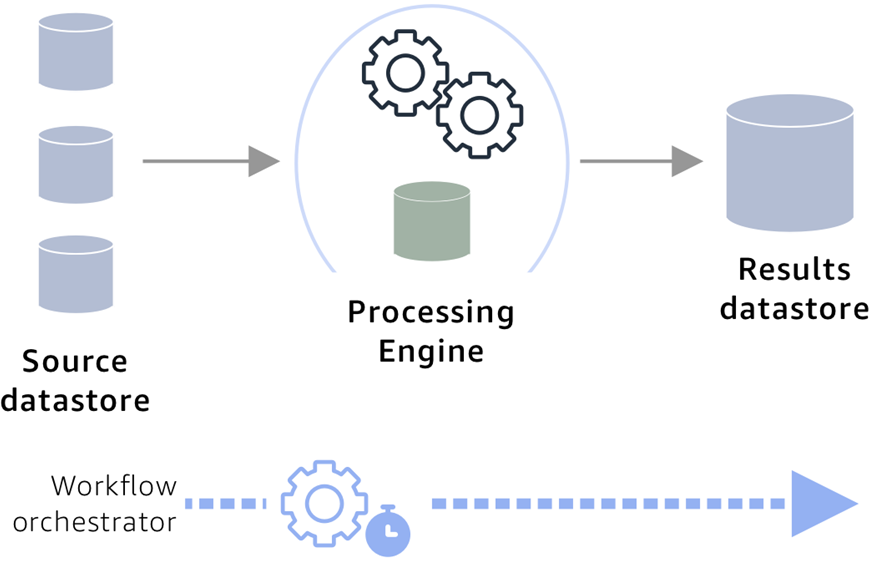
Figure 1 – High-level solution overview.
This architecture caters for cleaning and deduplicating customer data, and for creating master data where an organization may have multiple sources for customer data.
The rules engine by design is configurable, allowing business rules that can be configurable and maintained with rule-specific metadata for instance type of rule, category, and so on. The rules evaluation results are enriched and captured with details to maintain history to understand the member journey.
Figure 2 shows how such an architecture can be realized using AWS-native managed services that reduce spend on operational maintenance activities, such as patching and capacity management, while providing programmatic access to the service feature. This enables operational excellence via automation.
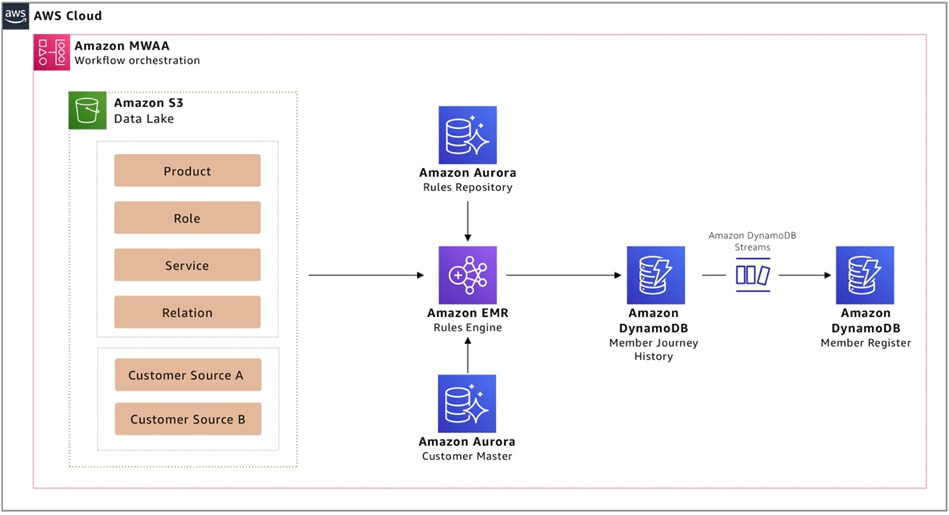
Figure 2 – Solution overview using AWS managed services.
AWS Implementation Solution Overview
The first step of implementing this solution is to get all of the customer and related data needed to run the business rules into your data lake. The data lake acts as the central location for all data sources on which the rules engine will run.
Additional important points to consider while implementing the data lake are:
- Identify the critical data elements that would be required to run your business rules and the source systems that have these data elements.
- If you have more than one customer data source, you can use a Master Data Management (MDM) tool like Informatica, Reltio, or other third-party tools to merge the customer data.
- If there’s a golden source of customer data, this can be used for identification of memberships.
- Ensure the customer data can be joined with other data elements like product, service, and roles so the business rules can be evaluated.
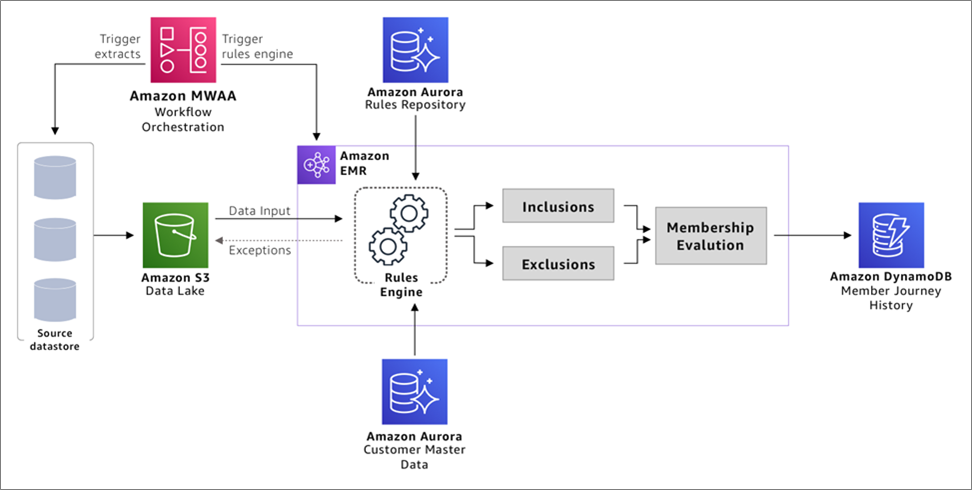
Figure 3 – Agile business rules engine implementation design on AWS.
The implementation uses the following AWS services:
Amazon Simple Storage Service (Amazon S3)
Amazon S3 is used to create a data lake of all data required for rules engine processing. As the data store aspect of the architecture, data lakes on S3 benefits from its 99.999999999% (11 nines) durability and object store nature, allowing the data lake to hold multiple data formats, datasets, and be able to be consumed by a variety of services in the AWS and third-party applications.
All customer information from the source environment is extracted and placed onto the data lake for subsequent processing by rules engine.
Amazon Aurora
Amazon Aurora is used to configure and capture the business rules with the metadata and reference data (like rule and membership types) that are needed to provision a simple relational database.
Aurora is a database engine for Amazon Relational Database Service (Amazon RDS) and meets requirements. This also provides a relational model that can be extended to include additional metadata like version of rule, active, or inactive rules.
These attributes make it easier to understand the customer/member journey and how and when they attained memberships, as well as which rules were in effect at that point in time and such.
Note that depending on the complexity of the rules and business requirements on how often these rules would change, you may want to configure the reference data accordingly.
Amazon EMR
Amazon EMR is used to create a data processer that can easily join data from different data stores and execute SQL in memory. It can also run rules in parallel, scale to changing business load, and be cost optimized by enabling transient features so you can save costs when the system is not in use.
Amazon EMR provides these features on AWS to rapidly process, analyze, and apply machine learning (ML) to big data using open-source frameworks.
The architecture uses Apache Spark on Amazon EMR due to its flexibility in being able to configure conditions and filters on the rules repository. Using SQL enables easier build and maintenance of rules.
Spark executes these SQL-based rules in parallel to identify the inclusions and exclusions against all of the customer data, and can be used to join with the other critical data elements (like product and service) and to validate against reference data configured in the rules repository.
Under the hood, the rules engine will:
- Create data frames of the customer data from the data lake and rules repository.
- Read the customer and critical data elements from the data lake and the rules and rule reference data from the Aurora database.
- Distribute and run the inclusion or exclusion SQL rules in parallel against all of the customers to ensure every customer is evaluated against every rule.
- Write the results from these SQL execution to an ephemeral storage or S3 bucket to be able to run evaluations based on the inclusions and exclusion results. This step can be executed in memory depending on your data volume and performance considerations.
Additional design considerations for the rules engine inclusions and exclusions modules:
- Complexity: Depending on the complexity of the rules and rule categories, you may prefer to configure the complete SQL statements in the rules repository itself. The evaluation step takes into consideration all of the inclusions and exclusions for each customer. If a customer qualifies for inclusions, and depending on what exclusions apply, it will grant or disregard memberships.
- Numeric inclusions and exclusions: To implement more complex business rules, the inclusion and exclusion rules can be granted numeric weights like 1, 2, 3 in the rule configuration when you design the rules repository. It would be a good idea to space the rule weights with multiples of 10 like 10, 20, 30.
- Need to disregard: If there’s a need to disregard certain exclusions and instead override such exclusions when certain inclusion rules apply, these weights can be used in the evaluation step. Assign higher numeric weights to inclusion rules that override any exclusion rules. During evaluation, you can apply a sum function to all the weightages of each category; the aggregate of inclusion weights and exclusions weights can be used to grant or disregard memberships depending on whichever is higher.
The rules engine generates a set of customer inclusions and exclusions tagged with additional metadata like types of memberships. As a next step, these inclusions and exclusions are evaluated to determine a binary outcome that will tag only those customers that qualify under the various membership types.
Amazon DynamoDB
Amazon DynamoDB stores the results from the rules engine, as it provides a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale for end system consumption.
The membership records are is inserted into a DynamoDB database that maintains the history of results. The records can be inserted into DynamoDB using Python. This will be an insert only table to capture all the history.
Amazon DynamoDB can be partitioned on the master customer ID and sorted using a history created date. The benefit of partitioning the data on the same key used in the customer master makes it easier to combine these datasets easily. The history created date makes the sorting easier to generate the customer or membership journey.
Optionally, these results can be streamed using DynamoDB streams into another DynamoDB table to maintain a current member register with the latest details for easy access or current view of the member register. Often, businesses may have another key like membership number, so the benefit of using another current DynamoDB table with the current version is able to use an alternate partition key and enable faster access.
Amazon Managed Workflows for Apache Airflow (MWAA)
Amazon MWAA is used to orchestrate workflow sequencing of events required to ingest, transform, and load data using a managed service. This enables development teams to focus on defining the workflow sequences and not worry about the underlying infrastructure capacity and availability.
Conclusion
By using a combination of AWS managed services, Capgemini can build a cloud-based rules engine that can be scaled to increasing data volume, easily configured, and quickly accessed. This enables organizations to be completely agile in developing new business rules, or updating/retiring business rules, without relying on IT.
Capgemini, with its global experience, best-of-breed technology, process, and people, can partner with you to help design and build solutions that can be tailored to handle other medium to complex business rules for any industry, using AWS cloud-native services.
.

.
Capgemini – AWS Partner Spotlight
Capgemini is an AWS Premier Consulting Partner and MSP with a multicultural team of 220,000 people in 40+ countries. Capgemini has more than 12,000 AWS accreditations and over 4,900 active AWS Certifications.
Contact Capgemini | Partner Overview
*Already worked with Capgemini? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.