AWS Partner Network (APN) Blog
Data Ingestion in a Multi-Tenant SaaS Environment Using AWS Services
By Peter Yang, Sr. Partner Solutions Architect – AWS SaaS Factory
By Ranjith Raman, Principal Partner Solutions Architect – AWS SaaS Factory
There are several ways to design and implement a data ingestion architecture using services from Amazon Web Services (AWS). When you’re ingesting data in a multi-tenant software-as-a-service (SaaS) setting, there are additional considerations, challenges, and trade-offs you’ll need to incorporate into your solution.
With SaaS, you need to ensure that tenant details are captured and propagated throughout the ingestion process, playing a direct role in how you isolate data and partition workloads and storage based on tenant personas.
There are multiple strategies that can be used when implementing a multi-tenant data ingestion process. Some might use a dedicated (siloed) mechanism and others may use a shared (pooled) ingestion model. Both are entirely valid and can be mixed, but for this post we’ll focus on the nuances of implementing data ingestion in a pooled model, highlighting the various considerations that come into play when ingestion resources are shared by tenants.
This post comes with a working example solution with code and steps to deploy this solution are available through GitHub.
Design Considerations for Multi-Tenant Data Ingestion
Before we dive into the technical architecture of the solution, let’s start by looking at some of the key considerations when designing a multi-tenant data ingestion process. Below is a list of common factors that SaaS providers look at when building such a solution:
- Scaling and performance: Ability to handle high volume of requests and seamlessly scale to thousands of tenants.
- Security and isolation: Implementing controls to ensure tenant events are authenticated and use those controls to make data partitioning and isolation decisions.
- Resource management: Seamless capacity management to handle spiky and highly unpredictable traffic.
- Operational efficiency: Reduced operational and administrative overhead.
Solution Architecture
This post references a sample solution that collects and aggregates data (think ecommerce websites and point-of-sale applications) where this data is processed (enriched and transformed) with tenant/customer specific attributes and stored in a backend data store.
These applications are typically tracking clickstream data and/or events such as ‘Total Orders’ or ‘Category of Products Purchased’ with the goal of identifying trends and deriving impactful insights from the data. Depending on the number of active users at any moment, this can be a large amount of data generated every second.
To support businesses and use cases like these, you need an architecture that’s highly scalable, performant, and able to process these events with very low latencies. The following diagram illustrates the architecture of our solution.
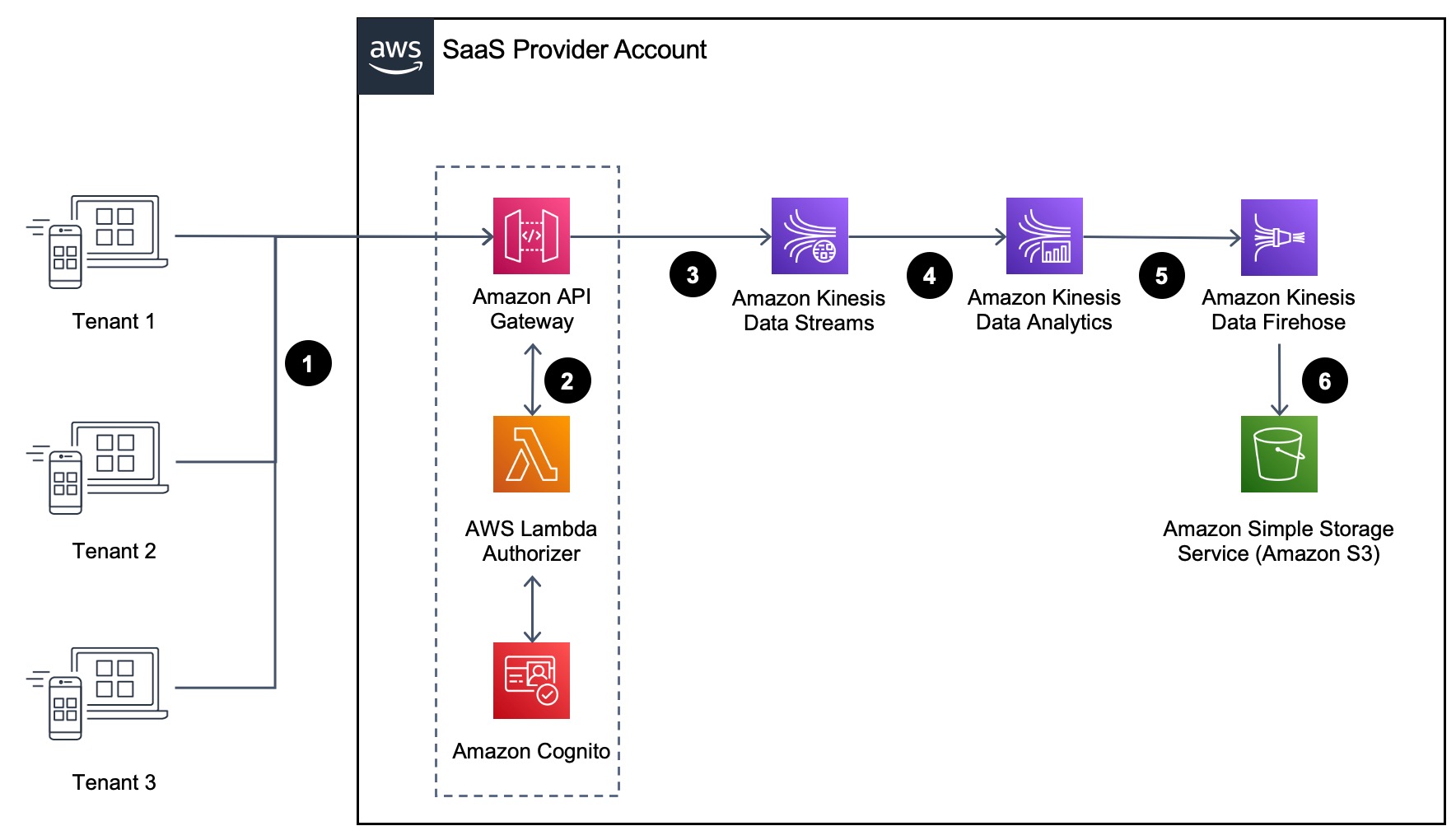
Figure 1 – High-level architecture.
Request Flow
Before we dig into the details of this architecture, let’s look at the high-level elements that are employed by this sample solution. Below, you will see the different steps that are part of the solution:
- The flow of this solution starts at the left of the diagram (Figure 1) where tenants send messages or events into your SaaS environment with the REST API provided by Amazon API Gateway. This is the entry point for streaming events and responsible for authenticating individual tenant events.
- Amazon API Gateway uses a Lambda Authorizer to validate the JSON Web Token (JWT) with Amazon Cognito. The Lambda Authorizer adds the tenantId to the context for Amazon API Gateway so it could be as input to Amazon Kinesis Data Streams.
- Amazon API Gateway acts as a proxy, pushing tenant event to Kinesis Data Streams, which is a serverless streaming data service that makes it easy to capture, process, and store data streams at any scale. In our example, Kinesis Data Streams will be the data ingestion stream that collect the streaming data from different tenants.
- Amazon Kinesis Data Streams pushes data to Amazon Kinesis Data Analytics, and Amazon Kinesis Data Analytics for Apache Flink is employed in this solution to process the data and augment it with the tenantId and timestamp, which will be used by Amazon Kinesis Data Firehose to create the Amazon Simple Storage Service (Amazon S3) prefix for storage.
- Amazon Kinesis Data Analytics pushes the tenant event to Kinesis Data Firehose, which is used to deliver the real-time streaming data directly to S3 for storage and further processing. S3 provides several mechanisms for storing and organize multi-tenant data efficiently. For a deeper look in to this, check out this AWS blog post where the various strategies to implement multi-tenancy when using S3 are discussed.
Now that we understand the high-level architecture, let’s dive deeper into each component of our solution.
Request Authentication and Authorization
Amazon API Gateway is the front door of this solution and acts as a secure entry point that provides a scalable way of ingesting streams of data from tenant applications. The API Gateway also allows us to introduce a Lambda Authorizer that will extract tenant context and authorize incoming requests.
This tenant information is passed in via an encoded JSON Web Token (JWT) that was generated when our tenant was authenticated by Amazon Cognito. This context is essential to allow this solution to associate the ingested data with individual tenants.
Each request that’s processed by the API Gateway calls a Lambda Authorizer, which extracts the tenant context from the JWT and returns an AWS Identity and Access Management (IAM) policy that scopes the access of the request.
Along with the policy, we also introduce a tenant identifier (tenantId) into the request’s context. We’ll look at how we use this context value later in our flow. Below is the example code that shows how we set the tenantId as part of the context.
Routing Data to Kinesis Data Streams
Once the request has been successfully processed, we can configure Amazon API Gateway to forward messages to an Amazon Kinesis Data Streams, which collects and processes streams of tenant data. Figure 2 below illustrates the configuration steps.
Here, we are setting the integration type of our integration request to an AWS service, which means we are forwarding the request to an AWS service (Kinesis Data Streams for this example).
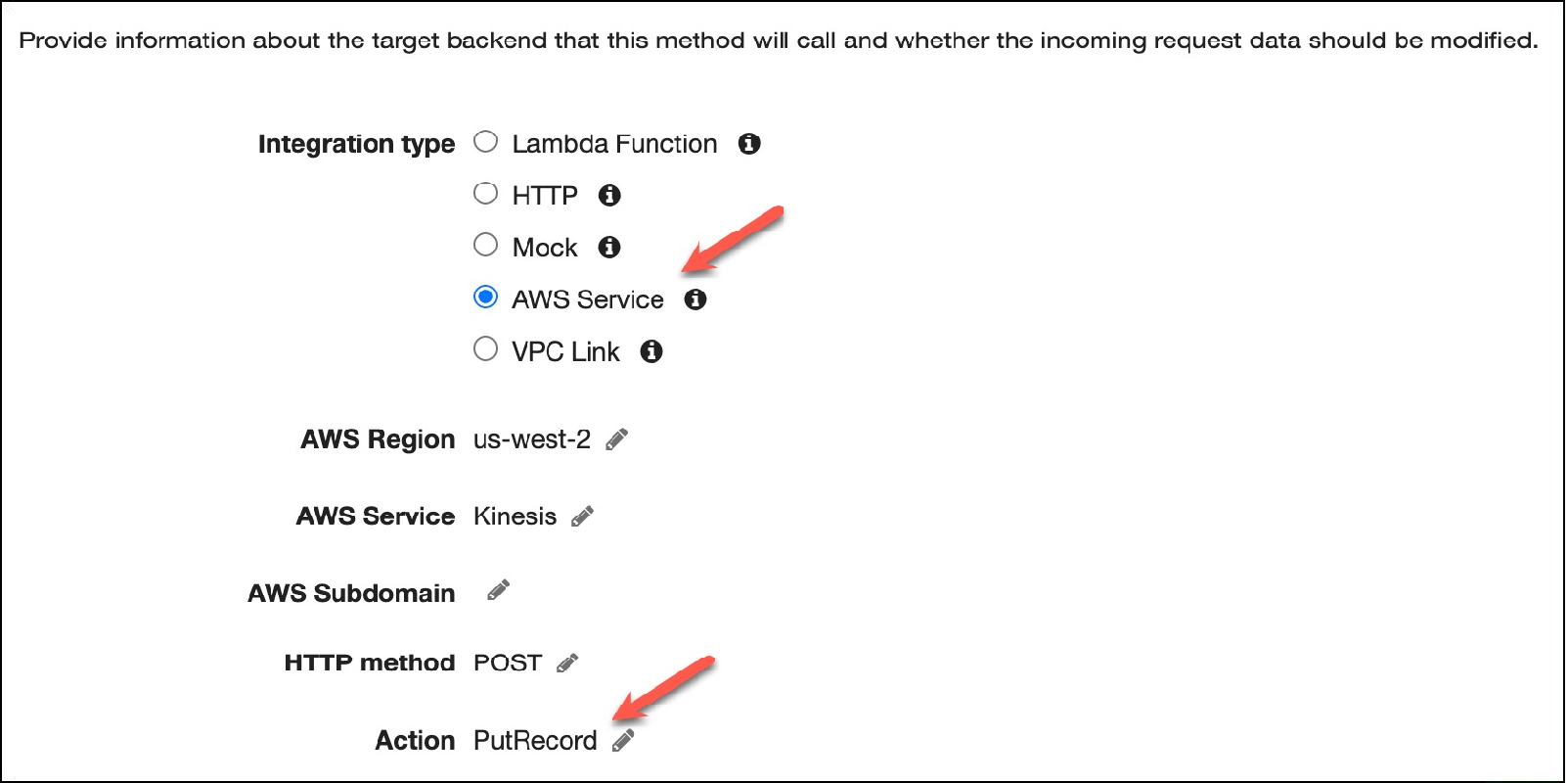
Figure 2 – Amazon API Gateway integration request values.
Before the request is forwarded to the stream, we apply a transformation at the API Gateway, converting the request to a format the Kinesis Data Stream is expecting.
Amazon API Gateway lets you use mapping templates to map the payload from a method request to the corresponding integration request. In our solution, as shown in Figure 3, we use a template to set the values for StreamName, Data, and PartitionKey. We use the tenantId field we received as part of the context set by the Lambda Authorizer to set the PartitionKey value, which is a required attribute for Kinesis Data Streams.
Through this template, we make sure every request that’s passed to the downstream services has an association with the tenant that is making the request.
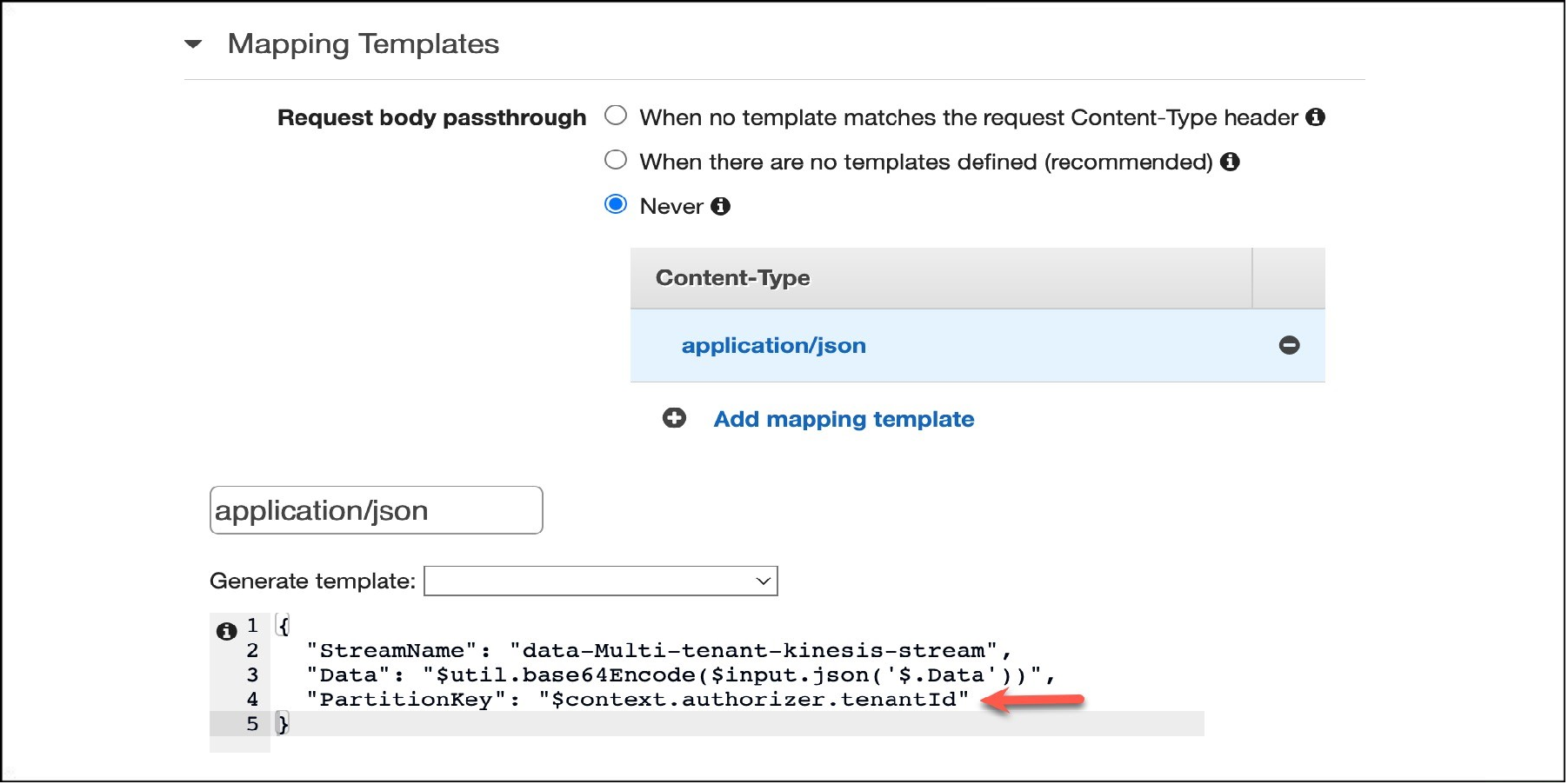
Figure 3 – Amazon API Gateway mapping template.
Process Streaming Data Using Kinesis Data Analytics for Apache Flink
As described in the earlier section, every message we send to the data stream has a partition key of tenantId. This value of the partition key will have an impact on which shard will process the message.
Each Kinesis stream will have one or more shards and the number of shards will have a direct impact on the amount of data Kinesis can process. We need to keep this in mind as the partition key could introduce a hot shard and effect the performance of the stream.
Once the message is processed by the data stream, we use Amazon Kinesis Data Analytics for Apache Flink to further analyze the data. With this service, you can use a programming language like Java to process and analyze streaming data.
In our solution, we use a Flink job to enhance the message with additional fields before the data is forwarded to the next service.
As you can see in the implementation in Figure 4, the Flink job has an inputStreamName which denotes where the data comes from, which in our case is the Kinesis Data Stream. As we mentioned above, the Flink job adds additional attributes for the tenantId and also a timestamp field before it pushes the message to a Kinesis Data Firehose delivery stream.
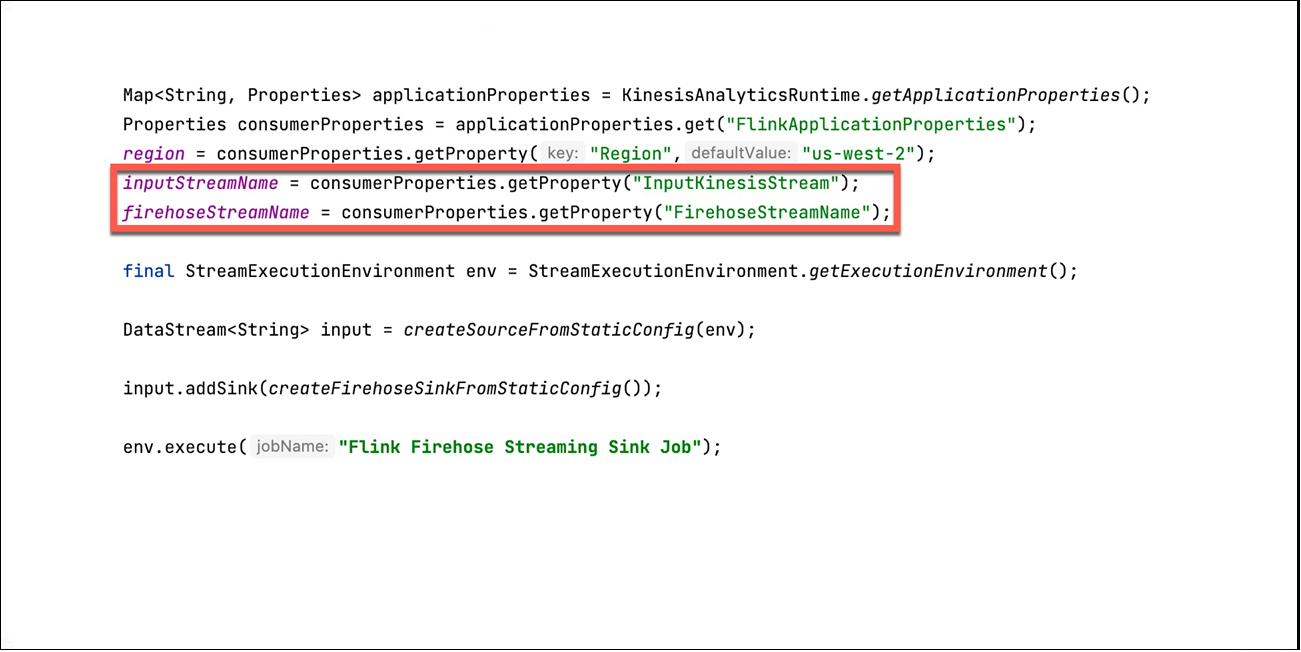
Figure 4 – KDA Flink – Set the InputStream and the FirehoseOutputStream.
Also, as shown in the code in Figure 5 below, the TenantId field is used to denote the path where the message will land in Amazon S3 and the timestamp would reflect the exact time that the Flink job processed the message.

Figure 5 – Setting tenantId in the Flink job.
Data Delivery Using Amazon Kinesis Data Firehose
In our solution, we use have used Amazon Kinesis Data Firehose to deliver the message to S3, using a prefix-per-tenant partitioning model to achieve better scale, especially when you have many tenants in your SaaS system.
With Flink, you can directly deliver the message from a Flink job to S3. However, by sending the data to Kinesis Data Firehose, you’ll have the flexibility to extend this solution in the future, allowing you to support other destinations like Amazon Redshift, Amazon OpenSearch Service, and other monitoring solutions.
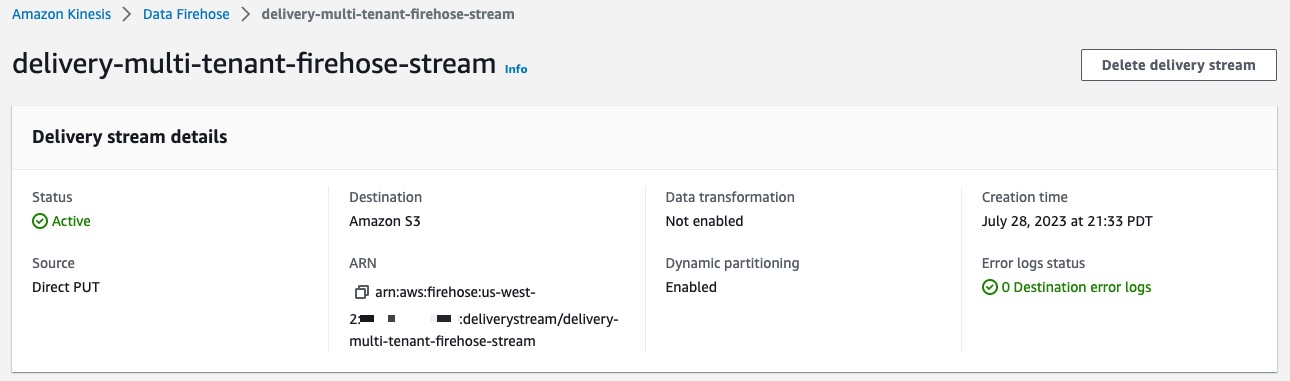
Figure 6 – Amazon Kinesis Data Firehose delivery stream.
As you can see in Figure 6, our Kinesis Data delivery stream delivery-multi-tenant-firehose-stream leverages the dynamic partitioning feature. This enables you to partition streaming data in Kinesis Data Firehose by using keys within data.
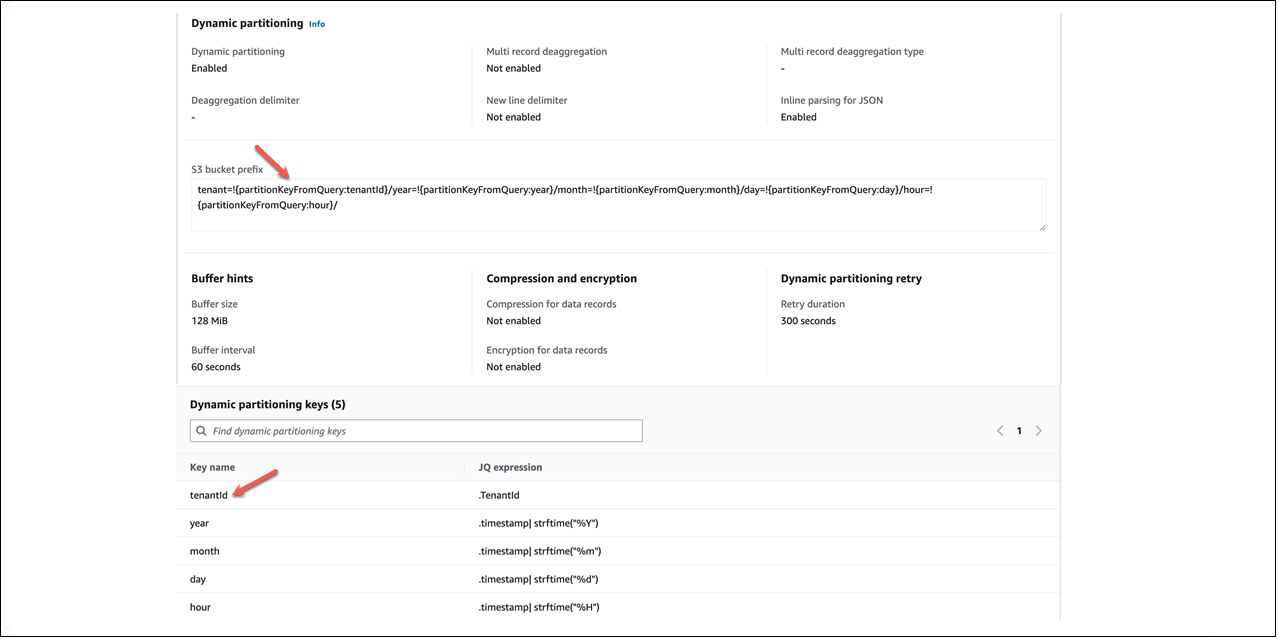
Figure 7 -Dynamic partitioning using tenantId and timestamp.
The keys help with grouping of the data before it’s delivered to the corresponding tenant’s S3 prefix locations. As you can see in Figure 7, we have used the fields tenantId and timestamp that were part of the incoming message to implement dynamic partitioning. By having the tenantId as part of the S3 prefix, we could create IAM policies that could be used as part of the tenant isolation strategy for S3 when consuming the data.
Finally, for data delivery to S3, Amazon Kinesis Data Firehose concatenates multiple incoming records based on the buffering configuration of your delivery stream. The frequency of data delivery to S3 is determined by the S3 Buffer size and Buffer interval value you configured for your delivery stream. More details on this can be found in the AWS documentation.
Conclusion
In this post, we explored how you can build a multi-tenant data ingestion and processing engine using AWS services. We examined each component of this data pipeline and some of the key considerations that can influence how you approach designing a SaaS multi-tenant data ingestion process.
We also looked at how multi-tenant streaming data can be ingested, transformed, and stored using AWS services while ensuring there are constructs built in to the pipeline to ensure secure processing of the data.
As you dig into sample application we presented here, you’ll get a better sense of the overall end-to-end experience of building a complete working solution on AWS. This should give you a good head start while allowing you to shape it around the policies that align with the needs of your SaaS data ingestion process.
For a more in-depth view of this solution, we invite you to look at the GitHub repo, where you’ll find step-by-step deployment instructions to assist with understanding all the moving pieces of the environment.
About AWS SaaS Factory
AWS SaaS Factory helps organizations at any stage of the SaaS journey. Whether looking to build new products, migrate existing applications, or optimize SaaS solutions on AWS, we can help. Visit the AWS SaaS Factory Insights Hub to discover more technical and business content and best practices.
SaaS builders are encouraged to reach out to their account representative to inquire about engagement models and to work with the AWS SaaS Factory team.
Sign up to stay informed about the latest SaaS on AWS news, resources, and events.