AWS Partner Network (APN) Blog
Delivering Closed Loop Assurance with Infosys Digital Operations Ecosystem Platform on AWS
By Vikrama Adethyaa, Sr. Solutions Architect – AWS
By Jignesh Desai, WW Migration Solutions Architect – AWS
By Anuroop Awasthi, Industry Principal – Infosys
By Aloke Kumar Dey, Sr. Industry Principal – Infosys
 |
| Infosys |
 |
In telecommunications, service assurance (SA) is a business-critical function offered by a communication service provider (CSP). As a collection of policies and procedures, SA ensures services meet pre-defined levels of reliability and quality to provide an optimal subscriber experience.
Traditional SA systems are open loop systems that require human operation to address detected issues. This increases a CSP’s operation costs as it requires them to deploy multiple complex network operation centers (NOCs) and manage large teams to oversee operations.
The transition from 4G to 5G technology requires CSPs to transform their existing network infrastructure, support rapidly growing industrial applications of 5G with varying network traffic characteristics, and ensure high reliability for mission critical workloads using their services.
Unable to rapidly accommodate to the evolving technology system and its operations, existing SA systems are becoming outdated. A modern cost-effective approach is required to address challenges such as increased inter-dependency between business lines and domains, multi-vendor equipment and systems, complex technology ecosystems, increased data volumes, and autonomous operations.
A closed loop assurance (CLA) system predicts network events, such as faults and congestions, that are highly probable of causing service degradation or interruption, and automatically take preventive actions to avert service disruptions.
In contrast to traditional SA systems that are human-driven and reactive in nature, CLA systems are proactive and machine-driven—thus reducing operation costs. CLA systems use data analytics and machine learning (ML) to proactively detect issues and remediate using automation.
In this post, we will discuss how Infosys leveraged AWS data streaming, data analytics, and ML services to 1) ingest, process, and analyze high volumes of data from disparate sources; and 2) build machine learning models to predict network events that can cause service degradation, and respond with automated remediation actions.
Infosys is an AWS Premier Tier Consulting Partner and Managed Cloud Services Provider (MSP) that enables clients to outperform competition and stay ahead of the innovation curve.
Key Challenges in Closed Loop Assurance
A CLA system capable of operating self-healing autonomous network operations has five stages:
- Predict Issue. Ingest, normalize, and aggregate data from multiple sources to predict events that can cause service degradation or outage. If an event is detected, the system generates a trouble ticket and triggers the remediation workflow.
- Identify Solution. Identify an appropriate solution for the predicted event from an existing knowledge base.
- Automated Remediation. Trigger automations to remediate issues—for example, push configuration changes and resource provisioning.
- Close Issue. Close the trouble ticket and record metadata of the event.
- Self-Tuning. Establish a feedback mechanism to continually improve event detection and remediation action plan identification.
A CLA system needs to ingest data from multiple system and has to interact with multiple systems for autonomous operations. Common challenges faced while building a CLA system include the following:
- Data Ingestion. High-volume data ingestion, in various formats, from multiple sources in near real-time.
- Data Correlation and Classification. Correlate large volumes of data from multiple sources to identify an event at near real-time. In addition, the event must be mapped to a specific entity such as topology, services, customers, or episode. Classify events as open loop (human intervention needed) or closed loop (automated remediation).
- Data Exchange Standardization. Standardize data exchange formats and API to improve data exchange between various systems, and continuously improve and add features with minimum disruption and effort.
Solution Overview
Built on AWS, Infosys Digital Operations Ecosystem (DOE) platform is a data-driven solution for CSPs with closed loop assurance capability that enables self-healing autonomous operations.
Infosys is a service assurance operations partner and an implementation partner for multiple assurance platforms. Having extensive experience working with Telcos globally, Infosys identified limitations in existing traditional SA systems.
The Infosys DOE platform combines its expertise in CSP service assurance operations and aims to address the limitations of traditional SA systems. Infosys worked with AWS to build a cloud-native CLA solution that leverages AWS native data analytics and machine learning services to build a cost-effective and scalable solution designed to address the challenges outlined in this post.
The DOE solution was designed from the ground up to address the following requirements:
Intent-Based Management
A radio access network (RAN) makes millions of decisions per second to determine traffic prioritization based on user type, traffic type, among others, to guarantee predetermined quality of service (QoS) and adhere to agreed service level agreements (SLAs).
The complex nature of CSP systems and operations makes it difficult to estimate how a configuration change would impact end users or services. Therefore, the SA solution must be able to use ML to automatically translate requirements into technical configurations, provision or configure respective services, and monitor to ensure the QoS and SLA are met against specified intent.
Intelligent Incident Detection and Alerts
The SA solution must be able to ingest and process large volumes of real-time data from various sources, such as network metrics, logs, and traps; use ML to detect patterns; identify anomalies; and predict potential outages or service degradation.
To improve operational efficiency, the solution must be capable of minimizing the overall number of alerts by, leveraging machine learning, minimize the overall number of alerts to intelligently determine a failure event from series of alerts, as well as detect false positive alerts.
To improve operational efficiency, the solution must be capable of minimizing the overall number of alerts—leveraging machine learning to intelligently determine a failure event from series of alerts, as well as detect false positive alerts.
Intelligent Diagnosis
The solution must be capable of using ML to correlate detected incidents with an existing knowledge base and intelligently determine impact to customer, service, and/or application. The solution must also be able to determine the likely root cause of the detected incident.
Intelligent Remediation
The solution must be able to determine a remediation plan for a detected incident using the existing knowledge base. It must determine the severity, owner, communication plan, and so on, for every action in the remediation plan.
Then, it must classify remediation action as a manual action (open loop) or an automated action (closed loop), and based on this choice, assign tasks to the respective personnel for manual actions or determine the workflow, scripts, and/or API to trigger for an automated remediation action. Finally, after executing the remediation plan, it must determine if the incident has been resolved.
Intelligent Task Routing
The solution must have the intelligence to route manual tasks to agents based on their skills, availability, and task priority. It must also be capable of identifying repetitive manual tasks and group them into an automation workflow to auto-remediate similar incidents in the future.
Intelligent Communication Management
The solution must send personalized notifications with the right information to the right stakeholder through the stakeholder’s preferred communication channel to improve operational efficiency and optimize the customer experience. It must also determine the communication channel—SMS, email, API, push notifications—to communicate with the respective stakeholder and/or system .
Self-Tuning
For the solution to evolve into complete unsupervised autonomous operations, a feedback mechanism must be established for continuous learning from new events, causes, and remediation actions observed during new incident handling. This allows for improvement of ML models to increase the accuracy of intent-based management, anomaly detection to predict network events, root cause analysis, and remediation actions.
Solution Architecture
Infosys Digital Operations Ecosystem (DOE) platform on AWS enables improved operational efficiency and resiliency through autonomous operations. This allows CSPs to allocate resources to providing innovative services, improved QoS, and SLAs for a superior customer experience.
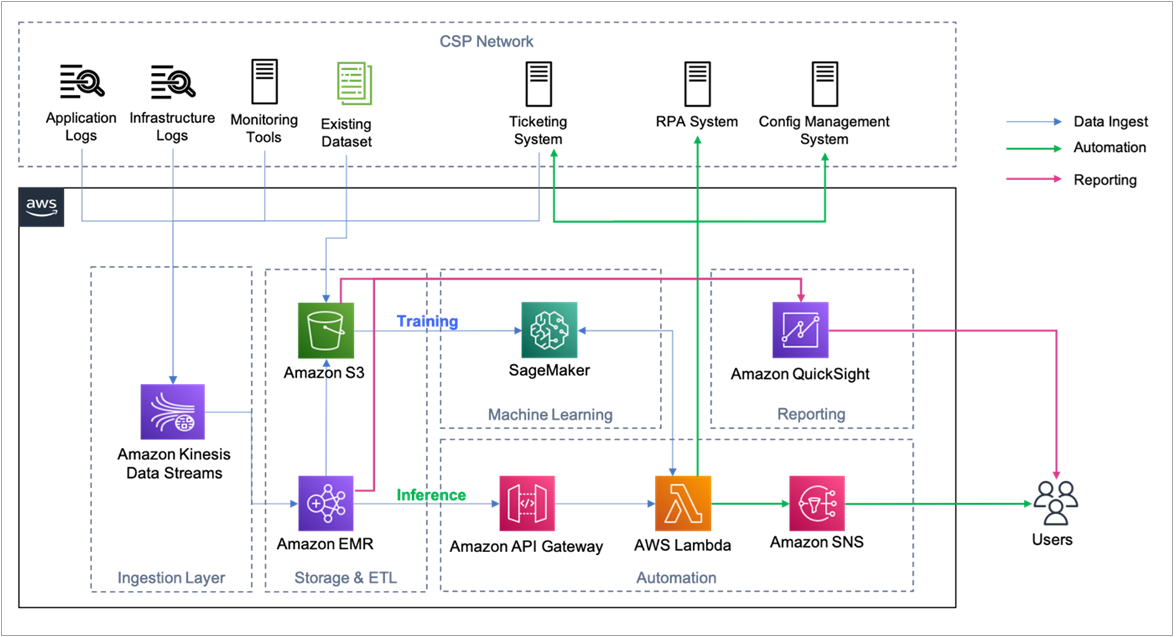
Figure 1 – Infosys Digital Operations Ecosystem (DOE) closed loop assurance solution architecture.
As shown in Figure 1, the solution continuously ingests data from various systems and applications and in near real-time, transforms the incoming raw data, identifies patterns to predict potential incidents using ML, and triggers automations to take remediate actions.
The following section explains the different layers in the DOE Closed Loop Assurance Solution:
Data Ingestion
The solution ingests real-time data from various systems and applications such as infrastructures logs, application logs, metrics from various monitoring tools, and other CSP commercial off-the-shelf (COTS) applications using Amazon Kinesis Data Streams (KDS) and delivers the data to Amazon EMR for processing.
KDS is an AWS managed scalable, durable, and low-cost serverless streaming data service capable of ingesting gigabytes of data per second from hundreds of thousands of sources.
Extract Transform and Load (ETL)
A traditional CSP network consists of multi-vendor equipment and various applications solving different business functions. Infosys chose Amazon EMR, a highly scalable cost-effective and AWS managed service, to help customers focus on transforming and analyzing data without having to worry about managing compute capacity or open-source applications.
Amazon EMR supports ingestion and transformation of high volumes of data and provides Amazon Simple Storage Service (S3) connectivity using EMR File System (EMRFS) to reliably store and access data. Apache Spark was used for in-memory data processing and Apache Flink was used for stream data processing.
Machine Learning
The solution required a cost-effective scalable platform that could support building new ML models and deploy existing ML models without the need for managing the underlying compute infrastructure. Amazon SageMaker—a fully managed service to build, train, and deploy ML models—was used to provide ML capabilities.
Automation
The solution leveraged Amazon API Gateway and AWS Lambda to execute the automations. Events that can cause potential incidents are sent to Lambda through API Gateway. Lambda then invokes the SageMaker endpoint to infer the probability of incident occurrence, remediation plan, and communication plan. Lambda executes the automation by contacting external systems based on the execution plan inferred by SageMaker. For example:
- Create trouble ticket in the ticketing system through REST API.
- Trigger the respective workflows/scripts in the Robotic Process Automation (RPA) tool through REST API.
- Execute respective configuration changes or provisioning through the configuration management system.
Amazon Simple Notification Service (Amazon SNS) was used to send personalized notification to respective end users using their preferred channel of communication—for example, SMS, email.
Business Intelligence (BI) Dashboard
Amazon QuickSight was used to provide personalized dashboards to respective users based on their role—allowing them to use existing data to gain valuable business insights from AWS data sources, such as Amazon S3 and Amazon EMR.
The insights allow CSPs to make data-driven decisions around planning and scheduling of field agents, prioritization of changes, and so on. The solution also leverages QuickSight’s embed functionality to embed dashboards into their existing web applications.
Conclusion
The Infosys Digital Operations Ecosystem (DOE) platform on AWS helps transform CSPs into data-driven digital operations organizations, allowing them to reduce their operation costs (OPEX) and provide an exceptional customer experience. The solution’s intelligent communication management feature delivers timely proactive personalized information, improving the overall experience of internal stakeholder and customers alike.
The DOE platform is now deployed in multiple CSPs globally—optimizing operations across business lines, including business operations, IT ops, and network operations, to name a few.
.

.
Infosys – AWS Partner Spotlight
Infosys is an AWS Premier Tier Services Partner and MSP that enables clients to outperform competition and stay ahead of the innovation curve.
Contact Infosys | Partner Overview
*Already worked with Infosys? Rate the Partner
*To review an AWS Partner, you must be a customer that has worked with them directly on a project.