AWS Partner Network (APN) Blog
Governing Databricks Data Access with AWS Lake Formation and Privacera
By Robert Dutcher, VP Product Marketing – Privacera
By Leon Stigter, Sr. Technical Product Manager – AWS
By Venkat Viswanathan, Sr. Partner Solutions Architect – AWS
By Ayan Ray, Sr. Partner Solutions Architect – AWS
 |
| Privacera |
 |
Many organizations have standardized or plan to standardize their unified data security governance on AWS Lake Formation, which provides powerful data access control to Amazon Redshift, Amazon Athena, and Amazon EMR.
Some of these organizations are also leveraging Databricks, however, and would like to create and manage data access policies for Databricks using AWS Lake Formation as well. They want to have consistent policy enforcement and monitoring across their AWS services, Databricks, and Amazon Simple Storage Service (Amazon S3).
In this post, we will discuss the AWS Lake Formation and Privacera integrated solution that extends AWS Lake Formation source support to Databricks. It provides data access policy authorship and maintenance from one safe and convenient location, AWS Lake Formation.
Privacera is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller that is a leading provider of unified data access governance solutions. It enables customers to deliver responsible data-powered performance from their ever-expanding data landscape.
AWS Lake Formation Overview
AWS Lake Formation is a fully managed service that makes it easy to build, secure, and manage data lakes. Together with AWS Glue Data Catalog, a persistent technical metadata store to store, annotate, and share metadata, Lake Formation is a critical component of unified data security governance for AWS customers. It provides AWS customers a single place to manage data access permissions for the data in their data lake.
Using Lake Formation capabilities like tag-based access control, data filters, and cross-account data sharing, customers are able to break down data silos. The available APIs make it straightforward to extend and augment the capabilities and reach of AWS Lake Formation.
Databricks Overview
Databricks is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller that allows customers to manage all of your data, analytics, and artificial intelligence (AI) on one platform.
The Databricks Lakehouse Platform combines the best of data warehouses and data lakes to offer end-to-end services like data ingestion, data engineering, machine learning (ML), and business analytics. With this unified approach, Databricks offers enterprises to simplify the modern data stack by eliminating data silos and helps them operate more efficiently and innovate faster.
The Databricks Lakehouse Platform delivers the reliability, strong governance, and performance of data warehouses with the openness, flexibility, and machine learning support of data lakes. Databricks is built on open source and open standards with a common approach to data management, security, and governance.
Privacera Overview
Privacera is an AWS Data and Analytics Competency Partner and AWS Marketplace Seller that delivers a unified data security governance platform based on open standards. Privacera enables organizations to discover sensitive data, protect and control access to data, and monitor data security and access across over 40 data sources, including Amazon S3, Amazon EMR, Amazon Redshift, Databricks, and Snowflake. This allows organizations to enhance data security while making data more accessible and reducing time to insights.
Privacera has also delivered two purpose-built solutions that integrate with AWS Lake Formation and allow AWS customers to augment their usage while having the choice to author, manage, and monitor data security and access policies in a single central location using either Lake Formation or Privacera.
These solutions are purpose built for AWS customers that want or need to use Lake Formation as part of their overall data security governance solution, but need additional functional capabilities or source support that Privacera can provide.
Integration Overview
This post covers the solution that uses Privacera to extend AWS Lake Formation to centrally author, manage, and monitor data security and access policies in Databricks.
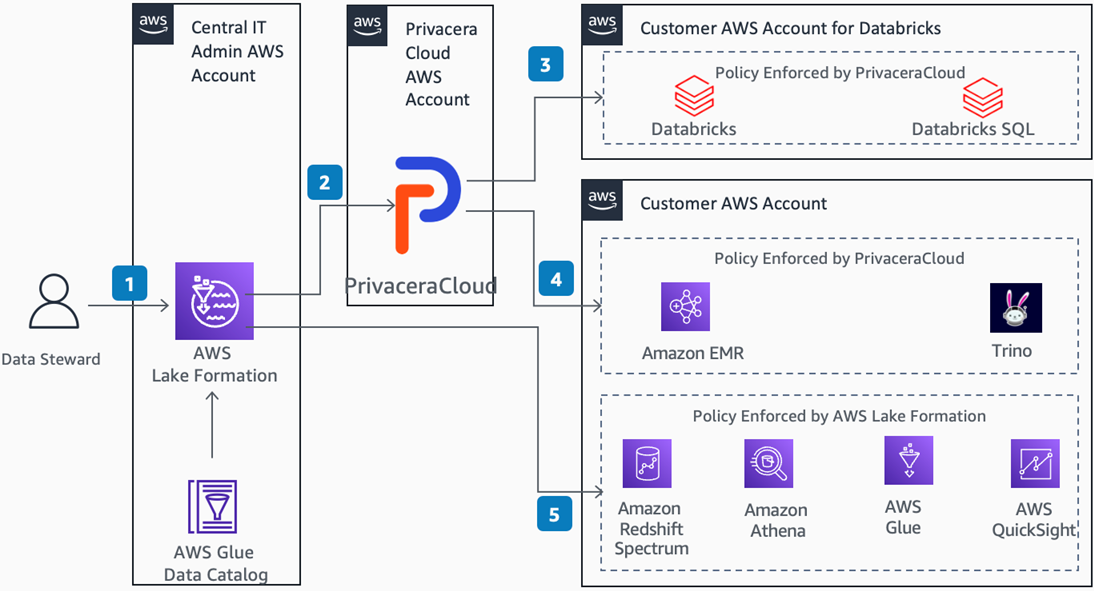
Figure 1 – AWS Lake Formation-centric architecture to govern Databricks access.
As described in the diagram above, Data Steward creates data access policies in AWS Lake Formation.
Data Access Policies are then synced to PrivaceraCloud, which is a fully managed software-as-a-service (SaaS) solution delivering unified data access governance. It’s built on the core attribute-based access control (ABAC) policy model of Apache Ranger.
PrivaceraCloud translates the AWS Lake Formation policy to Apache Ranger policies. It then uses a plugin to enforce policies to Databricks, and uses PolicySync to sync policies to Databricks SQL Analytics.
PrivaceraCloud also enforces policies created in Lake Formation on AWS services that are not natively supported by Lake Formation, such as Amazon Redshift and Amazon EMR. Lake Formation supports Apache Spark on Amazon EMR and Apache Hive on Amazon EMR. PrivaceraCloud can extend that and support policies on Presto and Trino.
AWS Lake Formation can natively enforce policies to AWS services like Amazon Redshift Spectrum, Amazon Athena, AWS Glue, and Amazon QuickSight. Using PrivaceraCloud, AWS Lake Formation can serve as a single pane of glass for data access policies for any customer using Databricks along with AWS services.
Walkthrough
Terminologies
- Principal: This could be the AWS Identity and Access Management (IAM) user, group, role, or SAML ARN.
- Resource: This means either catalog, database, table, or column.
Prerequisites
- Follow these steps to create a test database in AWS Glue.
- Next, follow these steps to create a test table in AWS Glue.
- Create a PrivaceraCloud account.
- Ideally, IAM groups and IAM users are synchronized from AD/LDAP or Okta/SCIM into Privacera. You can also synchronize it manually by following these steps. If the users/groups are not present in Privacera, then these permissions won’t be synchronized. However, for IAM roles, Privacera will automatically sync the IAM roles as Apache Ranger roles into Privacera.
Step 1: Create Cross-Account Trust IAM Role
- Create an IAM role called privacera_cloud_lf_connector_to_lf_and_glue with the following custom trust policy.

Figure 2 – IAM role trust policy.
- After the role is created, grant the IAM role read-only privileges to AWS Glue Data Catalog and AWS Lake Formation.
- Create an inline policy and add the permissions as shown below.

Figure 3 – IAM policies attached to IAM role.
- Go to AWS Lake Formation, click on Administrative roles and tasks, choose Administrators, and add the IAM role created in the above steps. This enables Privacera to get the policies from AWS Lake Formation.
Step 2: Configure AWS Lake Formation Connector in Privacera
- Log in to Privacera and navigate to Lake Formation, which is listed under Application.
- Click on Access Management and update the AWS account ID, ARN of the IAM role created in the previous step, and the AWS region.
- The Lake Formation permissions sink type should be listed as reverse_sink.
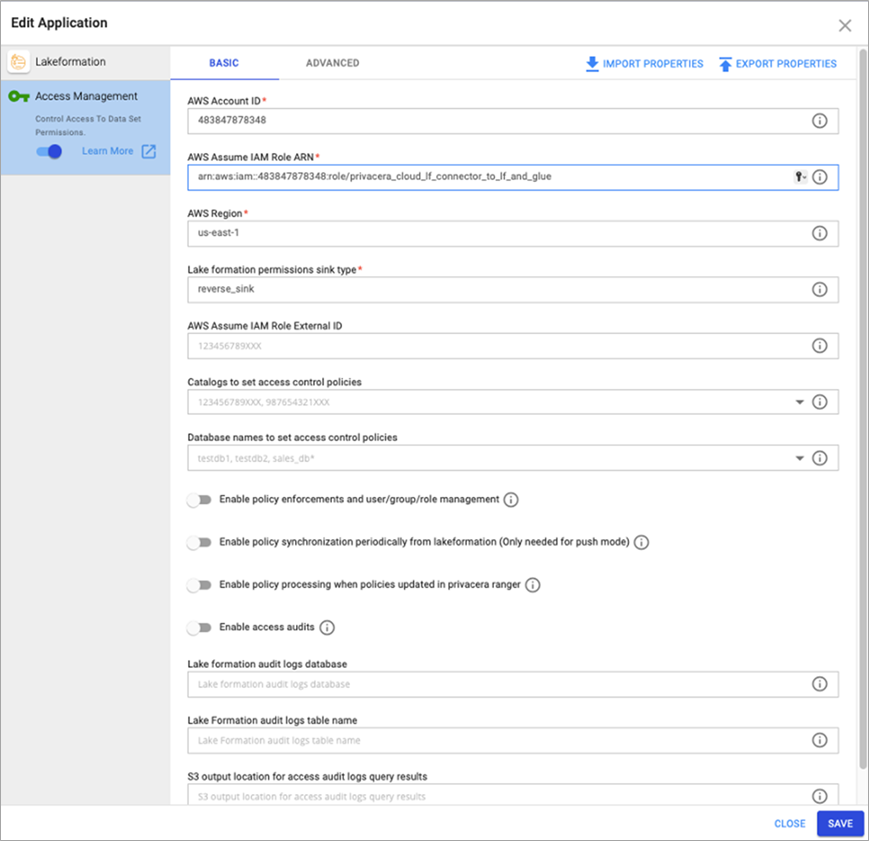
Figure 4 – AWS Lake Formation connector configuration in Privacera.
- If everything is done correctly, you should see the privacera_lakeformation tile under Access Management > Audit > Plugin. You should also see connector audit logs in PolicySync tab.
- The Privacera Lake Formation connector will automatically pull the IAM roles and add them to Apache Ranger. You can check it under Access Management > Users/ Groups/ Roles > Roles.
- The existing policies in Lake Formation will be synchronized in Privacera. You can check this by going to Access Management > Resource Policies > privacera_lakeformation.
Step 3: Create Data Access Policies in AWS Lake Formation
- Navigate to AWS Lake Formation and select Grant Data Lake Permissions.
- Select the IAM user under IAM Users and roles.
- Select Named data catalog resources and select sales_db and table sales_data. This database and table are already present in AWS Glue Data Catalog.
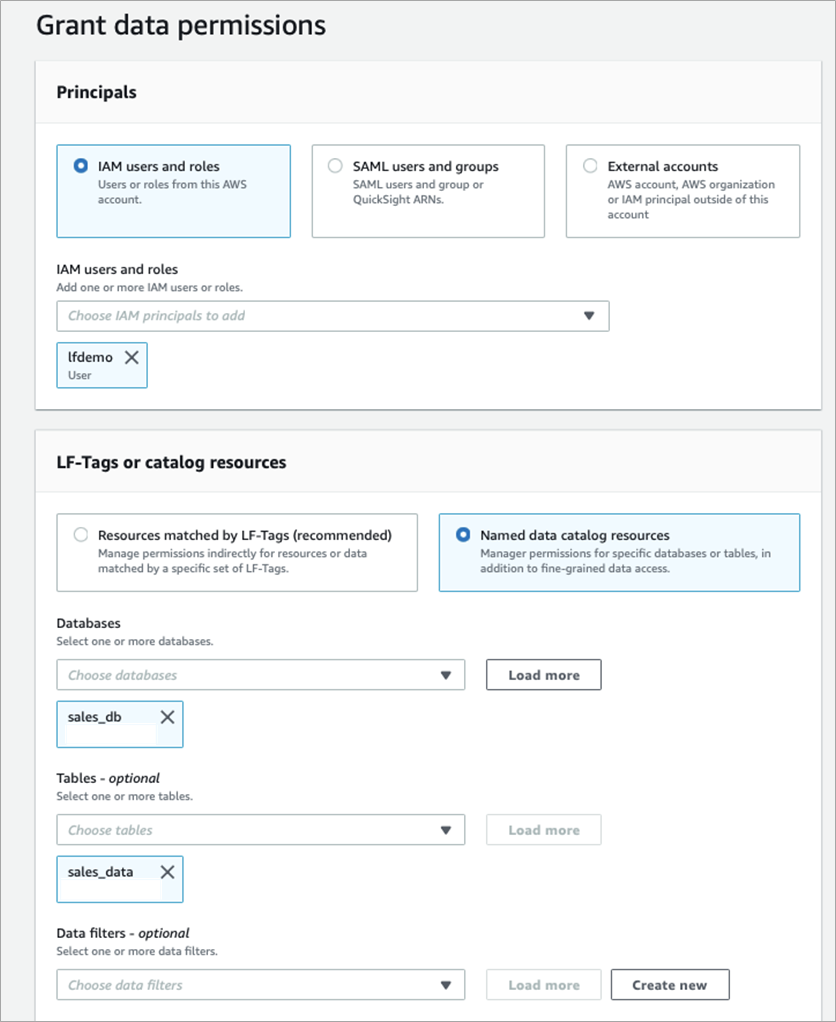
Figure 5 – Defining table access policy in AWS Lake Formation.
Step 4: Visualize Data Access Policy in Privacera
- The access policy created in AWS Lake Formation should be synced to Privacera. You should be able to see it in Access Management > Resource Policies > privacera_lakeformation. You won’t be able edit this policy in Privacera.
Step 5: Validate Data Access in Databricks
Go to the Databricks environment and try to access the table. If everything is right, you should be able to access the sales_data table present in the sales_db database.
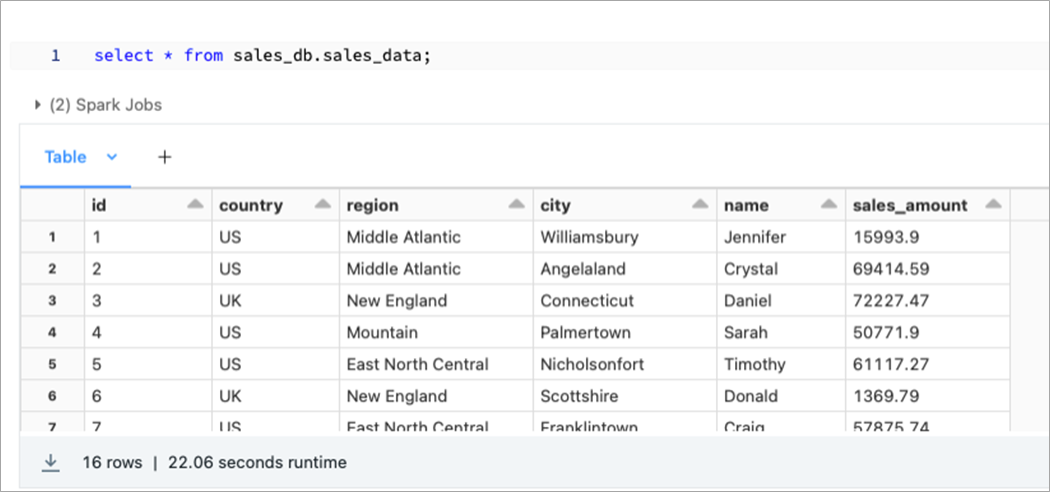
Figure 6 – Accessing the table in Databricks.
You can also define a column-level access policy and row-level filters in AWS Lake Formation, and Privacera can enforce that to the Databricks environment.
Conclusion
This post demonstrates how AWS customers can extend AWS Lake Formation to centrally author, manage, and monitor data security and access policies in Databricks using Privacera’s Lake Formation-centric solution and the Privacera-AWS Glue integration.
Data access policies can be created in Lake Formation and Privacera will automatically pull policies and translate them into Databricks access controls for native data access enforcement. This solution extends your Lake Formation capabilities into Databricks and delivers greater data security and data accessibility to data consumers.
Learn more about Privacera in AWS Marketplace.
.

.
Privacera – AWS Partner Spotlight
Privacera is an AWS Data and Analytics Partner that provides security and privacy tools for enterprises to secure and govern user access to databases and datastores in the cloud.