AWS Partner Network (APN) Blog
How CubeAngle Built a Serverless File Ingestion and Processing Framework Powered by AWS
By Mohammad Meimandi, Cloud Solution Architect – CubeAngle
By Abhijith Ramesh Chandra, Partner Sales Solutions Architect – AWS
By Gerardo Vazquez, Sr. Partner Management Solutions Architect – AWS
 |
| CubeAngle |
 |
As organizations strive to drive business results and better serve their customers, there’s an increased demand for technology teams to come up with innovative ways to reduce time-to-market and optimize operational costs.
Optimizing operational costs means organizations can transfer the savings to clients through service improvements or discounted prices and attract more customers and increase revenue. A cloud-native approach helps organizations gain competitive advantages by increasing efficiency, reducing costs, and ensuring availability.
In this post, we present a customer story about an organization which had challenges with a 10-year-old file ingestion and processing framework. Due to business growth, the framework could no longer keep up with demand and caused a lot of operational issues. Maintenance was becoming increasingly costly as well.
CubeAngle is an AWS Partner and team of data experts taking pride in working with companies where data is mission-critical. CubeAngle helps clients to collect, transform, and process their data in the most efficient way and become a data-driven enterprise.
Overview of Legacy Solutions
The customer organization provides inventory management, online catalogue, purchasing, and scheduling services to small and medium sized manufacturing and distribution companies. It has third-party integration processes and receives several files from third-party entities (customers, vendors).
As part of its solution, the company built a framework to allow customers to upload catalogues, bill of materials, quotations, and a few other documents to the SFTP server. Once the files are transferred, the framework parses and transforms the data and refreshes the backend database. Figure 1 shows the high-level data flow.
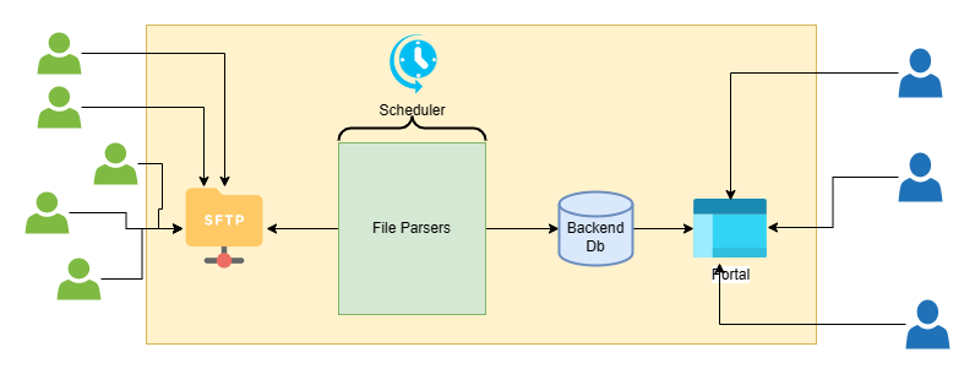
Figure 1 – Existing data flow.
- File gets uploaded to the SFTP server.
- A scheduler triggers custom coded file parsers in different intervals to pick up the files, parse them, and refresh the backend database.
Challenges of the Legacy Solution
The framework was able to support the workload before the company’s growth when it had only a handful of small clients. As the company onboarded more customers, however, several issues emerged and maintaining the framework was not feasible anymore.
- The amount of time to process the files increased, and by the time the data gets refreshed in the database it has become stale and new data has arrived.
- Failures go unnoticed, resulting in customer dissatisfaction due to missed timelines.
- Changes in file structures or introducing new file structures impacts the whole framework.
- Capacity planning, provisioning, and operation was challenging.
CubeAngle’s Solution to Operational Challenges
CubeAngle proposed a solution with the following guiding principles:
- Customer is a small business with a small IT team; therefore, the first principle was to design the architecture in a way to minimize operation and maintenance overhead with built-in monitoring, logging, notification, and remediation capabilities.
- De-coupling the file ingestion and processing. Files can arrive at any time and in any numbers. The on-demand strategy was a better fit because the files can be processed as soon as they arrive. There’s no need to have a scheduler trigger jobs every N hours to check if there’s anything to be processed. In addition, processing the files in parallel was an obvious choice.
- Built-in scalability and the ability to handle peaks and troughs in demand.
- Cost optimization and security.
Based on the above principles, CubeAngle decided to design a serverless architecture. Using AWS serverless services, the company can onboard thousands of new clients without worrying about capacity and scaling the infrastructure. The team also doesn’t have to worry about updating, patching, and maintaining the servers and operating systems anymore.
The cloud business optimization team helped evaluate and avoid several expensive licenses for proprietary software (scheduling, database software) and replacing them with AWS services, resulting in 63% of cost savings. In addition, they helped the customer to migrate the monolithic application to a modern application architecture using microservices, which allowed them to build new file parsers or modify existing ones with confidence and minimal impact.
Figure 2 illustrates the high-level architecture of the modern, serverless solution.

Figure 2 – Serverless architecture.
- AWS Transfer Family is used as SFTP provider. This service is compatible with SFTP, FTPS, and FTP standards. Users continue to use their choice of SFTP client to upload files to the same SFTP address and don’t see any change.
- The backend storage of AWS Transfer Family is an Amazon Simple Storage Service (Amazon S3) bucket. An S3 event is configured on the bucket that inserts a message into an Amazon Simple Queue Service (SQS) queue anytime a file is dropped into the bucket. Later, this queue is used by an AWS Glue crawler to process the files that were dropped into the bucket/prefix. This is to avoid any errors when multiple files arrive at the same time and prevents having instances of the same crawler running at the same time, which will cause the AWS Glue service to throw errors.
- An Amazon EventBridge rule is configured on the bucket that triggers and fires off an AWS Step Function, which is the main orchestrator of the workflow.
- The workflow starts by a triggering an AWS Lambda function which inserts a record in an Amazon DynamoDB table with information about the file to be ingested. This record can later be used for analytics (for example, the number of files successfully ingested), error handling, and failure notification messages to the user.
- The queues, crawlers, and jobs are built separately for each file type. This means if a thousand different files arrive at the same time the system can identify each file type (for each client) using S3 prefixes, and then trigger the right crawler and job for that file type. All of this will be processed in parallel.
- The Lambda function retrieves some configuration data from DynamoDB; for example, the relevant crawler for the file type.
- Another Lambda function triggers the relevant Glue crawler for the file type. This Lambda waits for the crawler to finish processing and returns the status to the Step Function.
- The Glue crawler reads the messages from the queue, processes the files, and makes sure it’s in the right structure (schema) and updates the Glue catalog.
- Upon successful completion of the crawler, another Lambda function triggers an AWS Glue job which uses the Glue catalog as source, performs any necessary transformations, and writes the data into another S3 bucket with a standard format (Parquet).
- Finally, another Lambda function loads the data into an Amazon Aurora Serverless database that’s used as the backend database for the web application. The web application is built using AWS Amplify for ease of deployment, scaling, and serverless hosting.
- Amazon CloudWatch is used end-to-end for logging and notification purposes.
- Infrastructure as code (IaC) using AWS CloudFormation templates allows the team to provision multiple environments in minutes.
Conclusion
In this post, we discussed how a legacy application can be modernized using several AWS services to reduce costs, increase reliability and security, and provide agility and faster time to market.
Harnessing cloud advancements and integrating sophisticated automation tools, the customer showcased in this post has heightened its responsiveness and streamlined operations, resulting in superior product. This transformation emphasizes the essential influence of cloud technologies and adaptive process automation in the prevailing business arena.
Serverless and event-driven architecture enable organization to reduce time to market with faster development, build scalable solutions, optimize IT infrastructure costs, and reduce outages and deliver a highly secure solution.
.

.
CubeAngle – AWS Partner Spotlight
CubeAngle is an AWS Partner and team of data experts taking pride in working with companies where data is mission-critical. CubeAngle helps clients to collect, transform, and process their data in the most efficient way and become a data-driven enterprise.