AWS Partner Network (APN) Blog
How LTIMindtree Solves for Cross-Account Sensitive Data Sharing Using AWS Services
By Rajan Seshadri, AWS COE Lead – LTIMindtree
By Shivaji Murkute, Lead AWS Data Architect – LTIMindtree
By Francois van Rensburg, Sr. Partner Management Solutions Architect – AWS
By Palak Shah, Partner Solutions Architect – AWS
 |
| LTIMindtree |
 |
Many customers come to LTIMindtree, an AWS Premier Tier Services Partner and Managed Service Provider (MSP), trying to solve for sensitive data sharing across multiple business units.
Changing and building on existing data movement processes can be a manual and intensive process, and often leads to analytical data being outdated which can lead to poor decision-making capabilities.
Organizations have a requirement to implement data governance due to the presence of personally identifiable information (PII), personal health information (PHI), and payment card industry (PCI) elements. The process of sharing and operationalizing data movement becomes an involved task, as it must encompass data governance, data security, and include audit capabilities.
Current challenges customers face when changing existing data movement processes include:
- Complex data movement process and lack of experience and tools capable to easily desensitize data.
- Building governance mechanisms are complex and not within a data engineers’ realm of experience.
In this post, we introduce a modern process LTIMindtree has introduced for data transfer using AWS Step Functions and for sharing transformed data to another account regardless of regional location.
Solution Overview
The automated process introduces a manual confirmation that notifies a data governance role by way of email and waits for a response before proceeding on to the action. On receipt of confirmation, the process resumes to the point of completion. A typical conversion process in this context involves desensitizing data because of data masking actions.
To illustrate the process, we break it into four steps:
- Regularly sync data from the online transactional processing (OLTP) database to an Amazon Simple Storage Service (Amazon S3) bucket using an AWS Lake Formation blueprint.
- Data transformation based on a configuration file; this process also involves manual approval.
- Post-approval, copy the approved dataset to the curated bucket and enable the data sharing to another account.
- Administrator in the shared account grants access to the shared data.
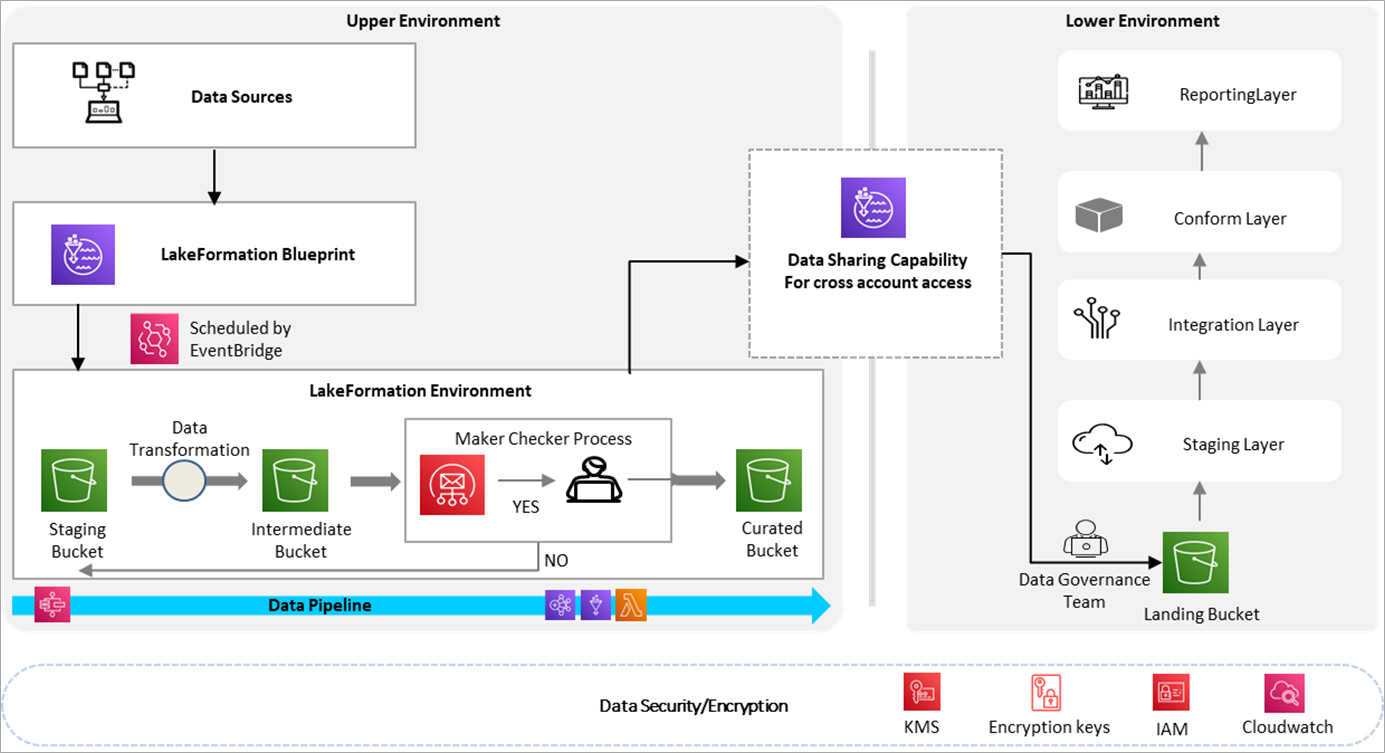
Figure 1 – Architecture overview.
Step 1: Data Extraction from Sources
For this illustration, we have two databases based upon Amazon Relational Database Service (Amazon RDS) synching the live data to a raw S3 bucket.
Data in the transaction systems is copied to S3 in the same structure as in the source relational database management system (RDBMS) tables. We’ll use an AWS Lake Formation blueprint to perform this.

Figure 2 – AWS Lake Formation blueprint data flow.
We designate a S3 bucket as one of the Lake Formation locations and secure it by granting access to no one. We then create the Lake Formation database with the S3 bucket.

Figure 3 – Amazon S3 bucket configuration.
Next, we create a Lake Formation blueprint process to regularly ingest data from the OLTP databases to Lake Formation, and designate the S3 folder to serve as the raw bucket.
To create a Lake Formation blueprint, follow these steps:
- Select the type of blueprint and specify the necessary database connection along with source path in a format, “<database-name>/<schema-name>/%”

Figure 4 – Create a blueprint.
- Specify a target database in AWS Glue, its S3 location (raw bucket), and the data format (CSV, Parquet). Note that the blueprint import frequency should be selected.

Figure 5 – Define target database, storage location, and import frequency.
- To initiate the workflow, we need the following:
- AWS Identity and Access Management (IAM) role to grant access to the source databases.
- Amazon S3 bucket where the Lake Formation process will write the data files.
- Click on “Create” to initialize the Lake Formation blueprint. The figure below depicts this workflow initiation.
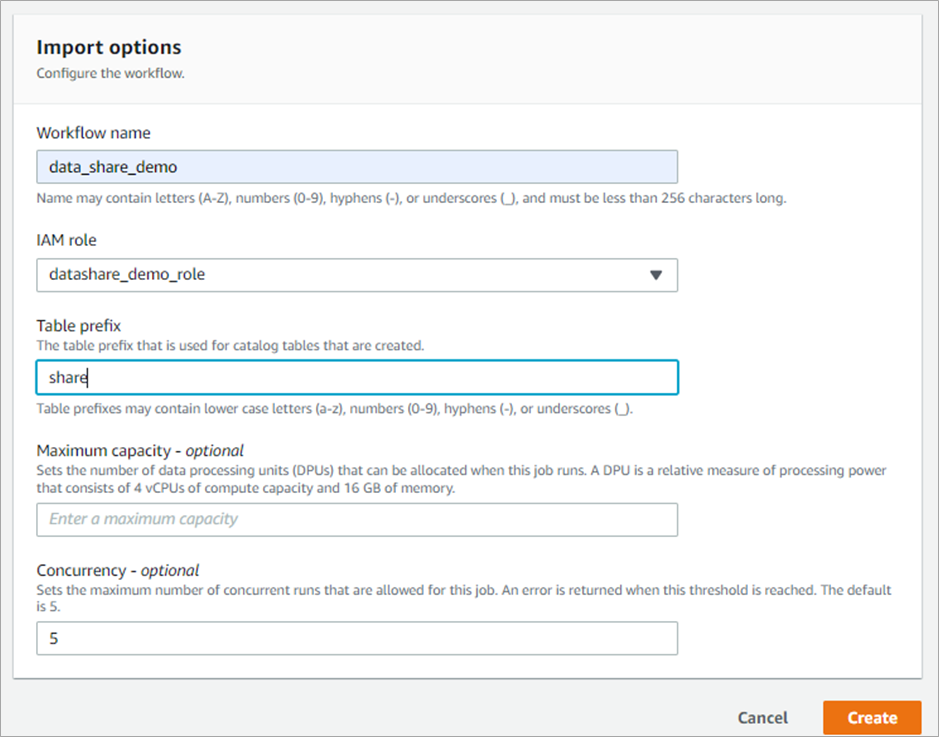
Figure 6 – Import table settings.
- The S3 bucket “s3://data_share_db /staging/” is used for this data movement.
- Each workflow creates and updates the data in S3 raw folder in the same structure as in the original OLTP database. The databases, schema, and tables are organized hierarchically in the S3 folder, with one folder per table and data files inside respective folder.
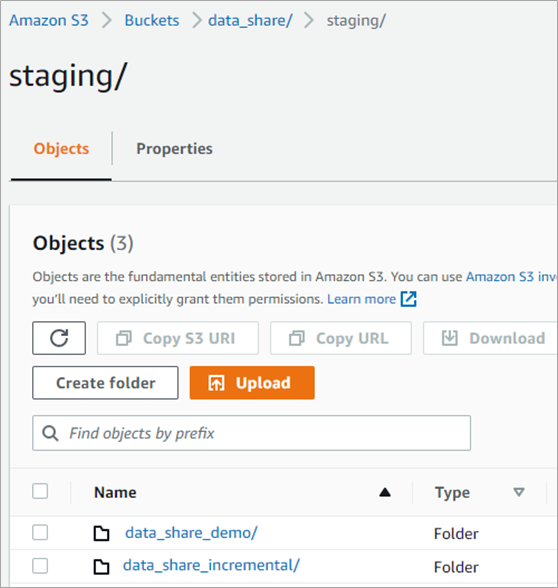
Figure 7 – Amazon S3 staging folder.
- Data in the OLTP databases is continuously replicated into the AWS Lake Formation blueprint. The replicated data resides in S3 and will contain all table data from all sources. The data is catalogued in Glue using APIs that create external tables.
Step 2: Data Transformation Using Custom Process
In this step, we perform data transformation using a custom process to desensitize the data. A config file with actions such as encryption, masking, bucketing, scrambling, and pseudonymization by various columns is passed as a parameter.
The data transformation process based upon PySpark will look up this file and perform the various actions.

Figure 8 – End-to-end process flow with user approval.
A sample config file in JSON format with actions corresponding to each column is included below.
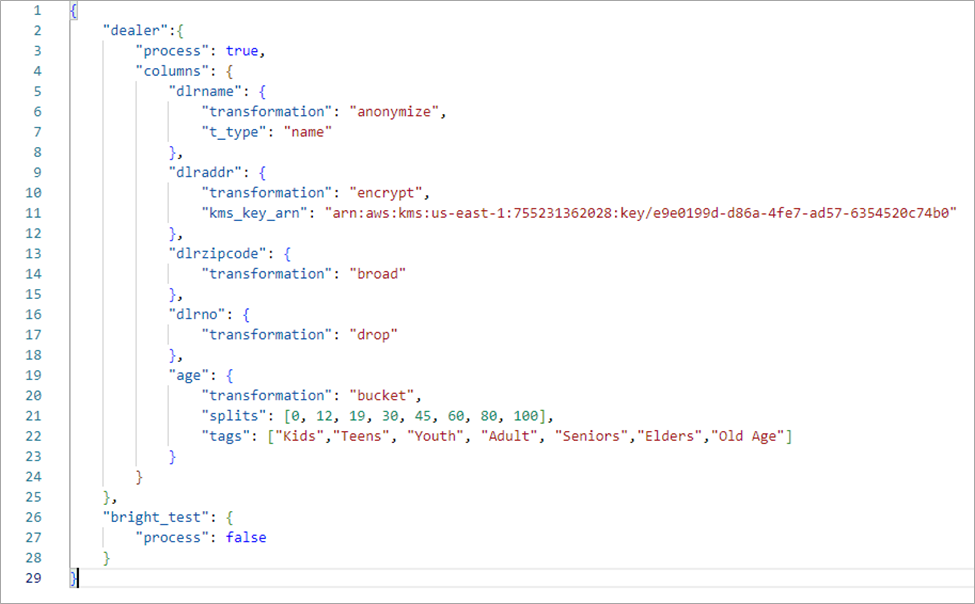
Figure 9 – Sample configuration file.
The process orchestrated by an AWS Step Function will be started at configured intervals by Amazon EventBridge.
The following will be passed as parameters to the Step Function:
- Python script
- Location of the S3 raw bucket
- Config file
The program applies the transformation and stores output data in a new bucket folder named “Intermediate” and sends a notification by email. The email contains a summary of the actions taken and a link one each for “Approve” and “Deny.”

Figure 10 – Example user email.
The Step Function will stop here and wait for a confirmation from the user. For this, we introduce a manual activity as part of the Step Function to pause the execution until it receives a signal.
To send this signal, we include an Amazon API Gateway that listens to an HTTPS URL request. The HTTPS request also includes a secure token for the sake of validating the user who initiated the request.
The users and recipients, upon receipt of the email, can validate the message’s content by using Amazon Athena. Each AWS Glue object the user queries in the intermediate bucket will be a consolidation of data across the two buckets: Curated and Intermediate.
Together, the data will represent the production data in OLTP systems. A user can validate the data by performing SQL queries on the curated and the source database.
Post-validation, a user can click the “Approve” button within the mail. This initiates an HTTPS request with a secure token included in the link to the URL exposed by Amazon API Gateway.
The request will be validated by API Gateway and pass a signal to the Step Function to resume where it paused earlier. It then calls another serverless data processing powered by transient Amazon EMR to copy the data from the Intermediate bucket to the Curated bucket.
The transformation process updates the external table definitions with the new partition of the data added to the Intermediate bucket for each table.
Upon completion of the data transformation, an AWS Lambda function will be invoked for sanity checking and an email generated to notify recipients on file. The process is then termed “Complete.”
Step 3: Cross-Account Data Sharing
Next, we’ll demonstrate sharing data from the Curated bucket in account “A” (sharing account) to the account “B” (shared account).
Following are the two steps that are performed in order.
- Grant the data catalog permissions using the named resource method to a target account, which is typically another account. Include the database “data_share_db” as the resource to share. To include the “SELECT” permissions to all of the tables in the database, we have used the wild card for tables.
.
Executing the below command will grant permissions to the target account “accountB” for the Data Catalog owned by this “accountA.”
.
aws lakeformation grant-permissions
–principal DataLakePrincipalIdentifier= accountB
–permissions “SELECT”
–permissions-with-grant-option “SELECT”
–resource ‘{ “Table”: {“CatalogId”:”accountA”,
“DatabaseName”:”data_share_db”, “Name”:”*”}}’
. - After granting the permissions to the target account, as explained in the previous step, a user with the data lake administrator privilege in the target account must grant permissions on the shared resource to principals in his account as illustrated using the below command.
.
aws lakeformation grant-permissions
–principal DataLakePrincipalIdentifier=arn:aws:iam::accountB:user/bob
–permissions “SELECT”
–resource ‘{ “Table”: {“CatalogId”:” accountA”,
“DatabaseName”:”data_share_db”, “Name”:”*”}}’
.
The command above grants the principal “bob” with ARN “arn:aws:iam::accountB:user/bob”, permissions to do “SELECT” on the database “data_share_db” in “accountA” to all tables in that database.
.
In above command, the user “bob” identified by his ARN is granted “SELECT” access to all tables in the shared database resource “data_share_db” in sharing account “accountA.”
Conclusion
In this post, we created an AWS Lake Formation process to regularly sync data from OLTP database into an Amazon S3 storage, process it using a customizable program, and store the curated data into another S3 bucket for consumption and sharing with another account. Quality control is included as part of the process using a manual approval.
We also demonstrated how to configure data sharing across accounts with permissions at database and table granular level.
Any questions or suggestions, to reach out to LTIMindtree at lti_data_aws@lntinfotech.com.
.

.
LTIMindtree – AWS Partner Spotlight
LTIMindtree is an AWS Premier Tier Services Partner and MSP that enables enterprises across industries to reimagine business models, accelerate innovation, and maximize growth by harnessing digital technologies.