AWS Partner Network (APN) Blog
Modernizing Data Assets from an On-Premises Data Warehouse to Amazon Redshift
By Mahesh Pakala, Principal Solutions Architect – AWS
By Srinivasan Swaminatha, Managing Director, AWS Modern Cloud Analytics – TEKsystems
By Lakshmanan Palaniappan, Sr. Practice Architect – TEKsystems
 |
| TEKsystems |
 |
In the world of consumer goods, real-time insights drive competitive advantage and business value.
A Fortune 500 global fast-moving consumer goods manufacturing company had the vision to maximize the benefit of analytics in decision support while increasing business growth and customer satisfaction opportunities.
This necessitated an architectural overhaul of the customer’s legacy ways of collecting, processing, and storing key consumer and payments data. It also required building strong data pipelines that are futuristic, scalable, and expandable to accommodate a variety of new sources, including point of sales (POS) and consumer sentiments.
How do you approach setting up a complex analytics platform involving billions of rows of data?
The difficulty primarily arises from the scale and complexity of the source environment, and only secondarily from functional discrepancy between source and destination system.
Most enterprise customers are trying to migrate their on-premises data warehouse from Oracle or other on-premises solutions to Amazon Redshift. This post will discuss the technical migration aspects for on-premises data warehouse solutions.
Typical challenges for such complex migrations include:
- Scale of the project—touching up millions of lines of SQL (no matter how miniscule the changes) turns any project into a non-scalable multi-year project.
- Upgrade of ETL (extract, transform, load) infrastructure needed.
- Rewrite any data loader scripts that were coded in data export tools and other loader languages.
- Upgrade of business intelligence (BI) and reporting infrastructure needed to leverage tools like Tableau or Amazon QuickSight to work with Redshift.
- Staff needs to retrain for ad-hoc data science interaction—solutioning to leverage existing client tools to work seamlessly with new cloud data warehouse.
- Redshift’s semantics implementation can differ from other data warehouse solutions even for identical queries, ensuring queries return the correct data set while running on Redshift.
In this post, we discuss a methodical approach to migrate an on-premises data warehouse solution such as Oracle or other flavors by moving to a cloud-native data warehouse like Amazon Redshift and achieve unparalleled scale while securing your business-critical data. Innovation is key to achieve success, and we’ll highlight all areas where automation fast-tracks the initiative.
TEKsystems Cloud Migration Toolkit
With several years of experience in migration and modernizing data assets, TEKsystems strives to put forth a series of tools, technologies, and methodologies to meet customers in their current AWS cloud journey path. This has resulted in several innovations which combined to form a “TEKsystems Cloud Migration Toolkit.”
TEKsystems Global Services is an AWS Advanced Tier Services Partner with Competencies in DevOps as well as Data and Analytics. TEKsystems is also a member of the AWS Well-Architected Partner Program and holds the Amazon Redshift Ready designation.
Here, we will discuss a real customer use case of moving data assets from an on-premises data warehouse into Amazon Redshift, a modern cloud data warehouse. However, the toolkit can help assist move data warehouses across several other platforms (Oracle and SQL Server, for example) into Amazon Redshift or Amazon Relational Database Service (Amazon RDS).
The TEKsystems toolkit’s key objectives are to provide efficient ways to:
- Transfer database structures
- Transfer data elements
- Transfer and optimize processes defined within the database
The goal is not to do a pure lift and shift, but to implement a methodical modernization of components that makes sense for your business.
Align Vision and Roadmap
Before initiating any series of activities, it’s critical to align with the cultural ethos and business aspirations of the customer. As a global provider of technology, business, and talent solutions, TEKsystems works in lockstep with customers in their business transformation.
Working through a series of well-defined brainstorming exercises as well as RACI (responsible, accountable, consulted, informed) discussions, a modern analytical framework (see Figure 1) was envisioned. TEKsystems developed a multi-step approach toward retiring a data warehouses and migrating it to Amazon Redshift.
TEKsystems proposes executing such large-scale technical projects in a phased manner. Several intermediate streams can be introduced depending on the current state of the customer’s cloud journey path, but here are some phases that help set the right foundation for building a robust architecture:
- Three P’s (people, process, planning) alignment and envisioning workshop: Identify success factors, key stakeholders, users, team/roles alignment, and aspirational future state.
- Deep dive and workload categorization: Comprehensive assessment document touching upon business processes, technology platforms, security, future-state strategy, and roadmap.
- Execute: Set up a one-team approach to work as a natural extension of the customer to realize project goals.
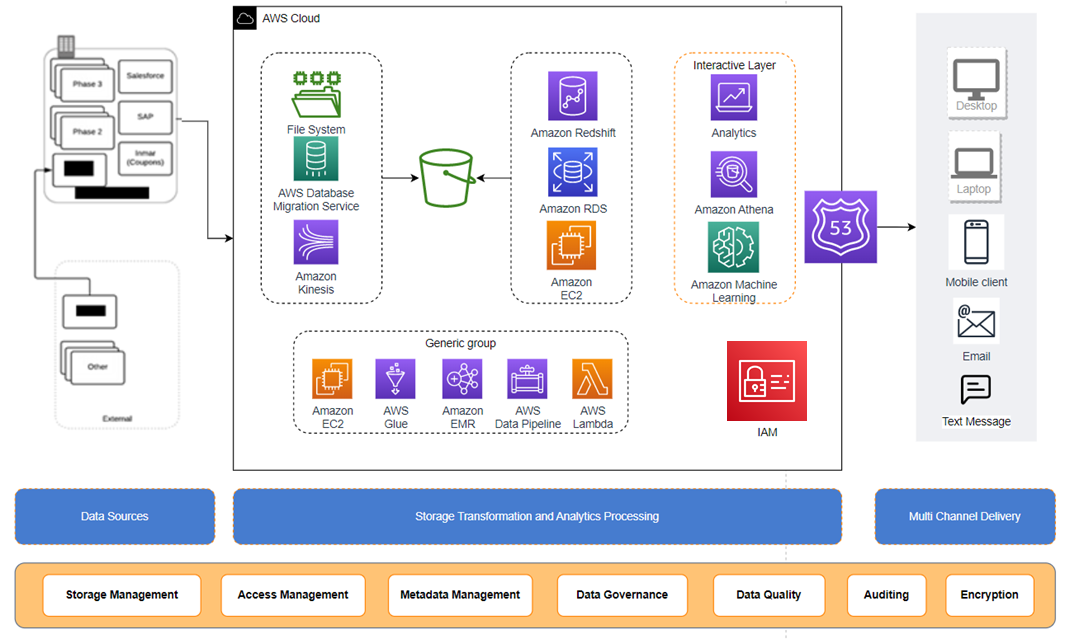
Figure 1 – Next-generation analytical platform framework.
The output from a comprehensive assessment and technical discovery could include:
- New architecture business and technical benefits
- Business requirements
- People, process, and technology matrix
- Data governance and personas
- Security (types of users, roles, security controls)
- Future-state architecture vision (roadmap)
- Foundation
- Phase 1
- Phase 2, etc.
- Lock-in considerations
- Glossary (to allow adoption to cloud terminologies quickly)
The logical step from here is enablement of this future-state architecture in a step-by-step method. We will now cover each of these steps in detail.
Lift, Shift, and Validate Data Using Accelerators
Analytics processes and projects depend on data of many types—transactional data, event data, and reference data—that comes from enterprise systems and databases as well as from big data sources. Big data, in fact, has little context and meaning for analytics until it is connected with enterprise data.
Existing data warehouses need to integrate into the analytics ecosystem, working together with a data lake, to provide the full range of data needed for analytics. A modern data lake needs to be flexible to accommodate new sources (from acquisitions) and higher frequency of incoming data.
To achieve this, the ingestion needs to be:
- Loosely coupled: Be flexible on data types and structures.
- Metadata-driven: Configuration driven, agile to changes.
- Built-in self-heal process: Quality checks embedded throughout in case of failures.
Zone-based data lake architecture is essential to move data from one layer to another. The complexity increases when dealing with thousands of tables. TEKsystems evaluated various technical methods to perform the lift and shift to AWS.
| Extraction Approach Path | Observations |
| AWS DataSync | Simplifies data movement from on-premises storage to Amazon S3 or Amazon EFS. |
| Amazon EFS | Amazon EFS is a fully managed service that automatically grows and shrinks as you add and remove files with no need for management or provisioning. |
| AWS SCT | AWS Schema Conversion Tool (AWS SCT) was used to convert existing database schemas (metadata) to Redshift. It converts schemas, tables, views and procedures. |
| AWS Data Pipeline | AWS Data Pipeline is a web service to move data between AWS compute and storage services as well as on-premised data sources. It’s a good candidate to move from Amazon S3 to Redshift. |
Amazon Redshift as a data warehouse solution aggregates all of the datasets and provides daily, weekly, and monthly reporting to end customers.
Every byte of information is crucial and should not be missed in a data engagement. A purpose-built validation tool was utilized as part of this project. By transferring the entire row into an MD5 hash key at each row level, the differences were quickly observed if any data got lost in the transit. The data validation phase helped gain the technical confidence to enhance the solution further in the next phase of optimization and reporting enhancements.
The Importance of Parallelism
Initial loads need to process large amounts of data and utilize parallel threads to move data quickly. While the benefits of parallelism are known, the constraints associated with firing up parallel queries can result in resource constraints in terms of CPU and memory availability as one of the biggest hurdles.
To resolve this, TEKsystems utilized compression strategies to minimize file transfer sizes, parallel run orchestrations, and create “loader daemon scripts” (see Figure 2). This improved performance to maintain continuous data transfers in an all-hands-free mode.
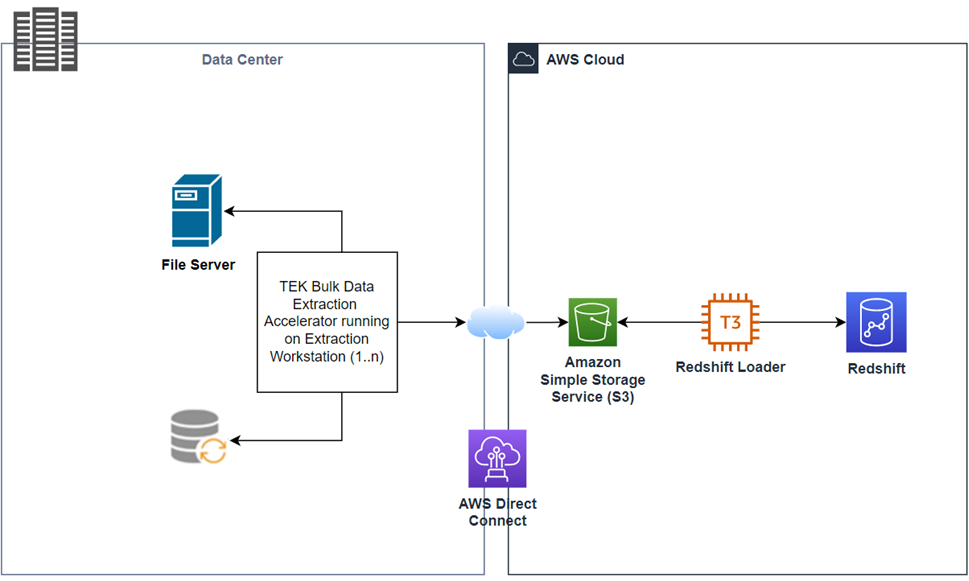
Figure 2 – Parallel extractor threads to sync data in parallel.
The diagram above illustrates the modular and iterative method used with utility scripts enclosed in a parameterized configuration bulk accelerator, that was chosen to move data to Amazon Redshift.
Initial Data Migration
The initial data migration encompasses moving “in bulk” all of the data from the on-premises data warehouse into Amazon Redshift.
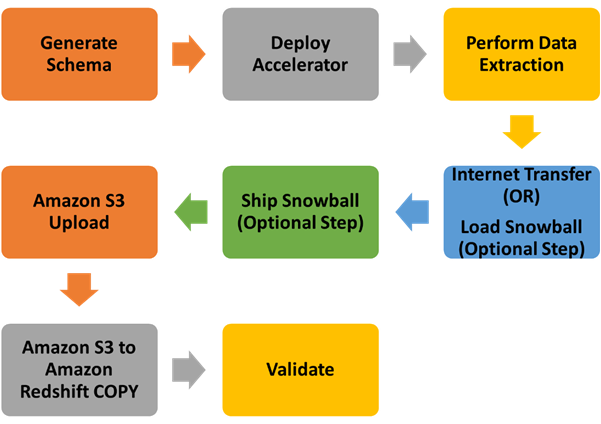
Figure 3 – Initial data migration step by step.
- Convert the source data warehouse schema into Redshift schema using AWS Schema Conversion Tool (AWS SCT).
- Deploy TEKsystems Bulk Extraction Accelerator scripts onto a migration instance on premises.
- Extract the full load of initial data from on premises and stage it locally.
- Load an AWS Snowball device orchestrating from the migration instance. The device is helpful when needing to migrate large amounts of data without impacting production systems on a long timeframe.
- Ship the Snowball device to AWS.
- Transfer enterprise data warehouse data from Snowball device to the data lake (Amazon S3 landing zone).
- Load the Amazon Redshift cluster using the COPY command.
- Validate loading process.
The Snowball device is leveraged for the initial load as a best practice to minimize migration time and avoid latency issues if there are constraints.
The following two diagrams call out the data movement from the on-premises data warehouse systems into Redshift utilizing AWS services along the way. The accelerator helps speed up the entire migration process, including taking care of compression, encryption, transfer, and validation processes.
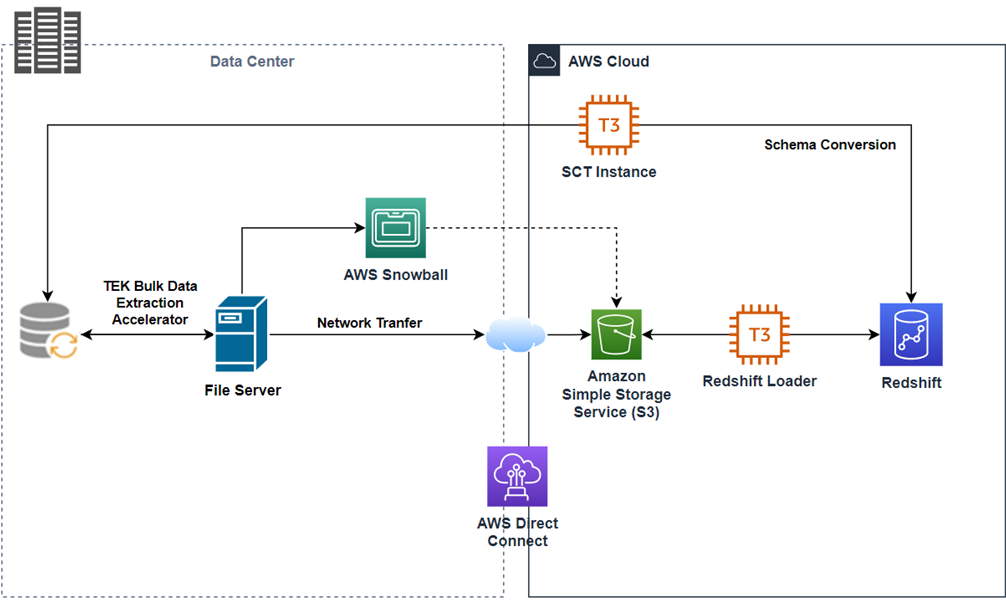
Figure 4 – AWS architecture moving bulk data from on premises to cloud.
The bulk accelerator, in turn, is executed with parallel threads, fully configured through parameterized options, resulting in fast transfer to the data lake as “things happen.” This is further elaborated in the incremental strategy section below.
By adapting to a seamless “acceleration method,” the table-level transfer is successful in moving data to Amazon S3-based data lake zones.
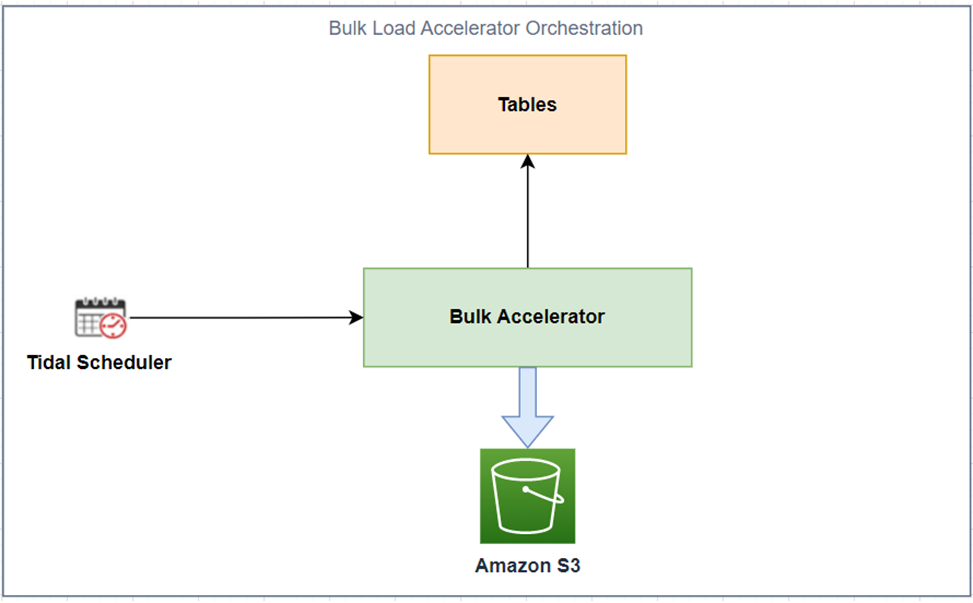
Figure 5 – Scheduled orchestration of loads using the Bulk Load Accelerator.
Incremental Load Strategy
The incremental data migration encompasses moving “changed” data set into Amazon Redshift.
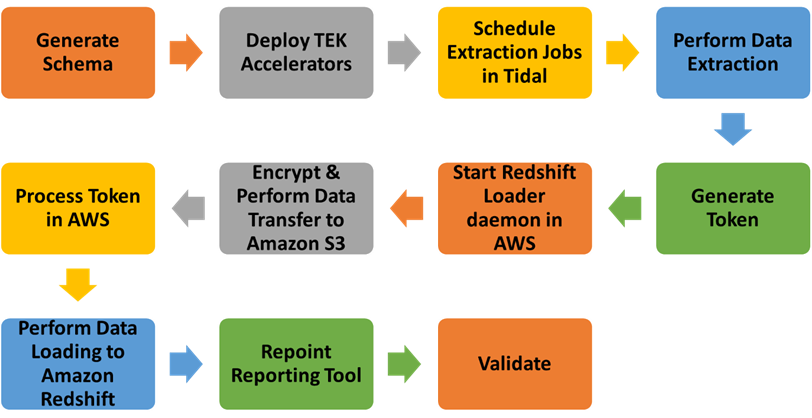
Figure 6 – Scheduled orchestration of loads using the Bulk Load Accelerator.
- After creating tabular structures and initial data, generate a token for each of the tables extracted from the on-premises data warehouse.
- Start the Amazon Redshift daemon process that polls the Amazon S3 bucket for data transfer files.
- Upon receiving a fresh set of files in S3, the Redshift loader daemon moves data to the Redshift cluster using the COPY command.
- Repoint your reporting toolset to utilize Redshift connections.
- Validate loading process.
Sample code performing the actual file transfer:
Extracted jobs are stored under a $frequency/$table_name format for dynamic creation and storage of the data set.
Measure Results and Continuously Refine
Replacing a decade-long legacy system has several pressure points to revert to status quo. This is where proactive measurement of success and continuously refining to project the value and benefits of the new architecture becomes critical.
Database modernization success results in a few key factors that are demonstrable through a quantified process, not guesswork.
A few examples include:
- Quality: Trust in data results in confident decision-making; 100% match is the starting point.
- Security: Protect business-critical data using fine-grained access control; trust but verify.
- Agility: Incremental wins, fast turnaround; velocity should be upward, not otherwise.
- Cost savings: Measure cost savings of moving from CAPEX to OPEX style; match predicted versus actual.
What’s Next?
Setting up a strong data platform is a stepping stone toward major transformation initiatives. Consumer behavior and tracking changes in patterns allows organizations to devise machine learning models to leapfrog competition and set up innovative sales and product strategies. This includes processing millions of POS systems as they happen to provide customers with immediate benefits in the form of coupons and reward points.
The new architecture outlined in this post makes it easier to maintain legacy systems and long cycles of development. The focus now shifts to what improvements in customer experience can be provided.
A few key advantages of Amazon Redshift are:
- Better security out of the box: Amazon Redshift customers can encrypt data at rest and in transit using hardware-accelerated AES-256 and SSL, isolate clusters using Amazon Virtual Private Cloud (VPC), and manage keys using AWS Key Management Service (AWS KMS) and hardware security modules (HSMs).
.
Amazon Redshift, by default, is compliant with SOC1, SOC2, SOC3, PCI DSS Level 1 requirements, DoD, ISO, FedRAMP, and HIPAA. Redshift, by default, is instantiated in a single-tenant model as a dedicated cluster. While many on-premises data warehouses also support encryption at rest, it may come with an additional implementation cost depending on the support level and engineering expertise.
. - Built-in disaster recovery: AWS and Amazon Redshift are inherently built to be resilient. With Redshift, there’s no additional cost for active-passive disaster recovery (DR). Automatic snapshot copy and refresh in another region is available at no charge for an active/passive scenario.
.
The newly restored Amazon Redshift cluster built can be accessed immediately as the restore process begins. On-premises data warehouses often require a standalone live DR environment to achieve DR, which leads to additional cost compared to a data warehouse running on the cloud such as redshift.
. - Free seamless upgrades: AWS manages the provisioning and installation of the upgrade to the Amazon Redshift cluster at no extra charge. The agile releases every few weeks are automatically and iteratively applied to the entire fleet. Customers can either be “current release” or “trailing release,” which is 2-3 weeks lagging and they can choose their own maintenance window.
.
Hardware failures and software updates require IT support involvement. This traditional on-premises upgrade process is long, where customers wait for six months to try out the new release, spend one month of regression testing, and then incur a weekend outage to install it in production. After all this, the hope is that only three to five P1 incidents occur.
. - Backups: With Amazon Redshift, space equivalent to the size of the Redshift cluster is available at no charge on Amazon S3. This is where automatic and incremental backups are stored. Customers can take manual backups as well at no charge, and lifecycle policies are built in.
.
With on-premises data warehouses, backups have historically been painful to manage. Customers have to budget and procure a tape library, establish the backup process and manually take backups.
Summary
Amazon Redshift isn’t just faster—it also costs less. Amazon Redshift costs up to 97.5% less than on-premises data warehouse solutions and 80% less than the base data warehouse edition when customers take advantage of Redshift reserved instances (RIs).
With a phased migration approach, TEKsystems’s customer realized immediate savings moving off an on-premises data warehouse while running its current applications against Amazon Redshift through partner solutions. Even greater savings are experienced by converting the application over to use full AWS services.
Finally, Amazon Redshift is the only cloud data warehouse that easily integrates with customers’ data lakes. Amazon Redshift Spectrum allows customers to easily run ad-hoc queries to combine data from their data lake and data warehouses in their reports and dashboards without unnecessary data movement. Querying data from the data lake does not affect the performance of their data warehouse.
Customers can also leverage the breadth of the AWS analytics services to gain insights from the data lake.
.

.
TEKsystems – AWS Partner Spotlight
TEKsystems is an AWS Advanced Tier Services Partner that helps clients activate ideas and solutions to take advantage of a new world of opportunity.