AWS Partner Network (APN) Blog
SaaS Data Isolation with Dynamic Credentials Using HashiCorp Vault in Amazon EKS
By Farooq Ashraf, Sr. Solutions Architect – AWS
By Jitin “Jay” Aware, Sr. Solutions Engineer, Public Sector – HashiCorp
By Sean Doyle, Sr. Solutions Engineer, Partner Solutions Engineering – HashiCorp
 |
| HashiCorp |
 |
One of the most common requests from customers is “How do I isolate tenant data in the cloud?” Tenant data isolation is a core software-as-a-service (SaaS) concept, verifying that tenant resources remain in isolated environments. There are a number of ways to achieve this isolation, and one common approach is to use a token vending machine (TVM) that issues tenant-scoped credentials at runtime.
To date, the content in this space has focused on mechanisms that require builders to explicitly request credentials programmatically. In this post, we’ll explore an alternate approach to vending tokens that uses open-source HashiCorp Vault, simplifying access to the credentials and streamlining the overall management of tenant-scoped policies.
We’ll also outline the key elements of how this experience can be delivered in an Amazon Elastic Kubernetes Services (Amazon EKS) SaaS environment.
HashiCorp is an AWS Partner and cloud infrastructure automation company that provides the open-source tools Vagrant, Packer, Terraform, Vault, Consul, and Nomad. Enterprise versions of these products enhance the open-source tools with features that promote collaboration, operations, governance, and multi-data center functionality.
How Token Vending Works
The general strategy for using a TVM to isolate resources in multi-tenant environments with dynamic AWS Identity and Access Management (IAM) policies relies on the application code or a custom library to initiate and manage session credentials.

Figure 1 – Token vending with dynamic IAM policy.
In the figure above, a microservice makes a call to the AWS Security Token Service (STS), along with a tenant-scoped IAM policy to receive temporary AWS credentials. Once the credentials are received, they can be used to access tenant-specific data for the duration of the token’s validity.
Proposed Approach
HashiCorp Vault is an identity-based secrets and encryption management system that tightly controls access to secrets such as API encryption keys, passwords, PKI certificates, and more via secure authentication and authorization.
This post builds on the concept of token vending by implementing a system using Vault; creating a model where limited-scope and short-term credentials can be acquired and injected outside of your service.
Vault retrieves tenant-scoped temporary credentials from STS, and injects them into the microservice container as a memory-based Kubernetes volume. This credential brokering is facilitated via the Vault Agent which sits alongside the microservice, removing the need to build and maintain the functionality as part of application code, and enhancing separation of concerns between data access and policy enforcement.
Here, we’ll show how the approach works with Amazon DynamoDB tables; however, it would similarly apply to AWS services that support granular IAM permissions, such as Amazon Simple Storage Service (Amazon S3), AWS Lake Formation, and AWS Glue Data Catalog.
High-Level Architecture
In our design, Kubernetes namespaces and node isolation provide the foundation for the deployment of tenants and microservices, for both silo and pool SaaS tenant isolation strategies.
In a Kubernetes cluster, namespaces can be implemented to logically isolate tenants from each other. Nevertheless, the cluster is the only construct that provides a strong security boundary. We recommend reviewing the Amazon EKS best practices guide.

Figure 2 – Amazon EKS SaaS architecture with per-tenant namespace.
In Figure 2, you’ll see our Amazon EKS SaaS architecture. We’ve employed a namespace-per-tenant model where the microservices of each tenant are hosted within a namespace.
These microservices may need to access other resources. In this example, you’ll see the Products microservice is accessing a DynamoDB table. Whenever the code running in our container accesses another resource, we apply tenant-scoped policies to verify the code is not able to access the resources of another tenant.
In an EKS environment, you have multiple options for applying tenant-scoped policies. One common way to achieve this is through the use of a sidecar.
Kubernetes supports running multiple containers within a pod. Typically, one container runs the main microservice, while other containers provide supporting services to the main container, and are thus called sidecars. Containers within a pod share resources such as service accounts, networking, storage, secrets, and config maps.
A sidecar can assist the main microservice by retrieving the tenant-scoped credentials on its behalf. One approach is for the sidecar to receive an explicit request from the microservice. The sidecar then retrieves the credentials and returns them to the microservice.
Another approach is for the sidecar to retrieve credentials and serve them readily and transparently, as illustrated in Figure 3. In the latter approach, the microservice can access tenant-scoped credentials whenever it needs.

Figure 3 – Sidecar pattern for credentials retrieval.
We follow the second pattern and use HashiCorp Vault as the building block for the retrieval of credentials from the STS, their renewal, expiry, access policy, and transparent injection into the microservice.

Figure 4 – Sidecar-based credentials retrieval with HashiCorp Vault.
The figure above depicts the high-level architecture we lay out, in which Vault retrieves from STS the credentials for each tenant based on the scoped IAM policy. A Vault Agent runs alongside the microservice pod, retrieves the IAM credentials from the Vault server for the tenant contexts that it’s authorized to access, and presents them to the microservice as AWS credentials files.
We have provided step-by-step deployment instructions and sample code for the proposed architecture in a GitHub repository and a Terraform sample.
Setting Up the Infrastructure
The baseline infrastructure required to make this solution work is depicted in the graphic below, outlining the key elements.

Figure 5 – Foundational infrastructure.
A private EKS cluster is deployed in a new Amazon Virtual Private Cloud (VPC) that has only private subnets, route tables, and security groups. A number of VPC endpoints are created, as shown in Figure 5, to facilitate cluster requests to AWS services.
The eksctl command line interface (CLI) is used for the deployment of EKS and the associated infrastructure, which generates AWS CloudFormation templates to create the various components needed to run a functioning EKS cluster.
When creating EKS managed nodes, eksctl also creates IAM roles with appropriate permissions required for cluster operations. Alternatively, HashiCorp Terraform can be used to provision the infrastructure as well, using the AWS and Vault providers.
In the context of this post, silo tenants are assigned dedicated Kubernetes pods, while pooled tenants share compute resources. We use a shared DynamoDB table for both silo and pooled tenants. In fully silo tenant scenarios, a separate database resource can be configured for each tenant.
Here, we create the Products table with the columns ShardID (which is also the partition key), ProductID, and ProductName. Each item in the table is associated with a tenantID stored as ShardID. tenanta and tenantb represent silo tenants, and tenantc-1, tenantc-2, tenantd-1, tenantd-2 represent pool tenants.

Figure 6 – Sample DynamoDB table.
Vault Deployment and Configuration
As part of setting up this model, we will configure and deploy the Vault service. There are two components to this service: the Vault Server and the Vault Agent.
The Vault Server is deployed as an EKS pod in its own namespace. The Vault Agent is deployed as a sidecar with the microservice that requires access to credentials, as was shown in Figure 4.
Note that this architectural pattern was chosen strictly for demo purposes—if possible, HashiCorp recommends deploying Vault to its own separate cluster per the Vault reference architecture. Alternatively, you can have different EKS nodes and use taints and tolerances to isolate the Vault servers from other workloads running on the nodes.
Once installed, Vault is initialized and unsealed. The initialization process makes Vault’s backend storage ready to receive data, and unsealing enables Vault to access its encrypted storage. The process generates a set of unseal keys and a root token. The root token contains the Vault super-user credentials. We capture and store the keys and the token in AWS Secrets Manager for subsequent use.
There are two important components of the Vault server which need to be specifically enabled, AWS secrets engine and AppRole auth method. The AWS secrets engine enables the generation and lifecycle of AWS credentials. The AppRole auth method provides authentication for incoming Vault Agent requests to the Vault server, governed by the policy attached to the Vault Agent’s role. An AppRole consists of a role_id and secret_id, which are both required to authenticate to Vault.
For silo tenanta, the AppRole is assigned a policy that allows access to a single secret aws/sts/tenanta.
For pooled tenants, with tenant IDs tenantc-1 and tenantc-2, the AppRole policy allows access to multiple secrets using regex.
The second part of the Vault infrastructure is the Vault Agent. Vault supports automatic injection of a Vault Agent sidecar into a microservice pod when provisioned with specific annotations. This is managed through the Agent Sidecar Injector that is deployed as a part of the Vault server.
As depicted in Figure 7 below, we configure Vault to use the STS AssumeRole API for retrieving tenant-scoped credentials. To facilitate this, we create vault-role in IAM, with a trust policy that allows the API call. This role is also assigned an IAM policy for DynamoDB, with the broadest set of permissions covering the entire set of tenants.
The Vault Agent is a Vault client, an entity that is mapped to a Vault role that defines the policy for accessing objects stored in Vault. We create a separate Vault role for each Vault Agent deployed in tenant namespaces.
For each of these roles, Vault calls AssumeRole with the scoped policy as an API parameter. The effective permissions of the role are the intersection of the vault-role’s base permissions and the scoped policy. The credentials returned by the API are cached within Vault’s storage.

Figure 7 – Vault infrastructure.
Tenant Provisioning in Vault
Now, let’s look at the onboarding experience of a tenant in Vault. As explained in the previous section, for each onboarded tenant, we create a Vault role aws/roles/tenantX. The scoped-down DynamoDB policy associated with the role is:
Vault Agent Deployment and Configuration
When an instance of the pod is deployed, it’s configured with the following annotations:
Annotations are the means by which the Agent Sidecar Injector is notified that an injection will be required for this particular application. Setting agent-inject to true indicates we want to automatically inject the Vault Agent sidecar, as shown in Figure 8.
The injection will use the configuration referenced by the agent-configmap and the secret containing the agent’s AppRole credentials (agent-extra-secret).
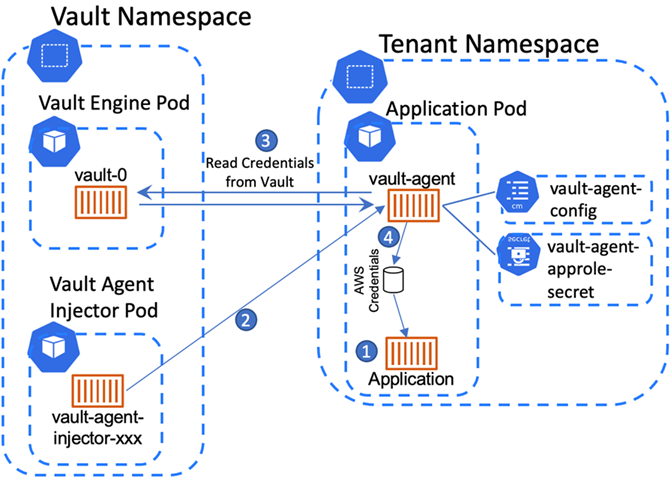
Figure 8 – Vault Agent configuration.
The agent’s configuration specifies the approle it is assigned, the Vault server address, and the destination location for rendering credentials, as shown in the following snippet:
The Vault Agent authenticates to the Vault server using its AppRole credentials, allowing it to access authorized IAM credentials. It retrieves those credentials, renders them into /vault/secrets/credentials, and makes them available to the microservice container through a shared volume with the same path.
The microservice for which the Vault Agent is deployed can be servicing a silo or pooled tenants. For a silo tenant, a single credentials file is rendered. For pooled tenants, a separate credentials file is rendered for each tenant. The Vault Agent template specifies the structure of the rendered credentials file.
For a silo tenant, we define the template in the Agent config map as:
For pooled tenants, we create multiple template configuration blocks; one for each tenant, where source contains the template definition and destination points to the location of the generated credentials.
Once these credentials are rendered into files, the microservice can access data in the DynamoDB Products table, by reading the credentials from tenant-specific file names.
Pooled Tenant Environment Bootstrapping
The Vault Agent for a pooled microservice depends on a dynamically generated template file. The tenant provisioning process generates or updates this file and pushes it to an S3 bucket, s3://vault-agent-template-xxxxxxxxx/tenantX/tenantX.ctmpl.
Access to the S3 bucket is provided through an IAM role attached to the pod service account (tenantX-sa), as shown in Figure 9. We inject the file into the microservice pod using the init container vault-template-bootstrap which copies the file to /vault/template where vault-agent-template-volume is mounted.
The microservice pod is configured with an annotation:
vault.hashicorp.com/agent-copy-volume-mounts: vault-template-bootstrap
This instructs the Vault Agent to copy the specified volume from the init container to the Vault Agent container, mounted as /vault/template, allowing the Vault Agent to read the template file and configure itself.

Figure 9 – Tenant environment bootstrapping.
When provisioning new tenants to a pooled deployment, the template file is updated and copied into the /vault/template/tenantX.ctmpl, on every microservice pod of the tenant, using kubectl cp. It’s also copied to the S3 bucket so that new pods or restarting pods receive the latest updates.
After updating the template file, the Vault Agent process is sent a SIGHUP to re-read the config map as well as the template, without interrupting the microservice as described in the Vault Agent support documentation.
Sample Microservice
The sample microservice used for this demonstration consists of the container image public.ecr.aws/aws-cli/aws-cli:latest running an infinite loop with a long sleep:
while true; do sleep infinity; done
We run kubectl exec -it to shell into the container and run AWS CLI commands and access data from the Products table.
Solution Testing
Next, we shell into the microservice container myapp in tenantX’s namespace, and set the environment variable AWS_SHARED_CREDENTIALS_FILE to /vault/secrets/tenantX so that it can be picked up by AWS CLI to get the associated credentials.
Then we run the following AWS CLI command:
As a result, only those data items are pulled from the Products table where the ShardID matches the tenant ID. Data items where the ShardID doesn’t match the tenant ID are inaccessible and trying to access them generates an AccessDeniedException.
Conclusion
In this post, we examined a solution for implementing multi-tenant SaaS data isolation with dynamic credentials using HashiCorp Vault in an Amazon EKS environment.
The proposed architecture creates a model to acquire and inject scoped credentials into microservices, decoupling applications from credentials handling and reducing the effort needed to maintain security and compliance.
It also improves the separation of concerns between data access and policy enforcement, and accelerates innovation by increasing secrets retrieval and rotation velocity. It reduces the risk of downtime due to exposure or rotation failure, and the risk of breach by centralizing and limiting the scope of credentials to only the intended applications.
A step-by-step implementation guide and the associated sample code are available in GitHub and as a Terraform sample, which can be helpful in understanding the solution and its various components.
.

.
HashiCorp – AWS Partner Spotlight
HashiCorp is an AWS Competency Partner that provides consistent workflows to provision, secure, connect, and run any infrastructure for any application.