AWS Architecture Blog
Implementing Multi-Region Disaster Recovery Using Event-Driven Architecture
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR).
We highlight the benefits of performing DR failover using event-driven, serverless architecture, which provides high reliability, one of the pillars of AWS Well Architected Framework.
With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. The main traffic flows through the primary and the secondary Region acts as a recovery Region in case of a disaster event. This makes your infrastructure more resilient and highly available and allows business continuity with minimal impact on production workloads. This blog post aligns with the Disaster Recovery Series that explains various DR strategies that you can implement based on your goals for recovery time objectives (RTO), recovery point objectives (RPO), and cost.

Figure 1. DR strategies
Keeping RTO and RPO low
DR allows you to recover from various unforeseen failures that may make a Region unusable, including human errors causing misconfiguration, technical failures, natural disasters, etc. DR also mitigates the impact of disaster events and improves resiliency, which keeps Service Level Agreements high with minimum impact on business continuity.
As shown in Figure 2, the multi-Region active-passive strategy switches request traffic from primary to secondary Region via DNS records via Amazon Route 53 routing policies. This keeps RTO and RPO low.
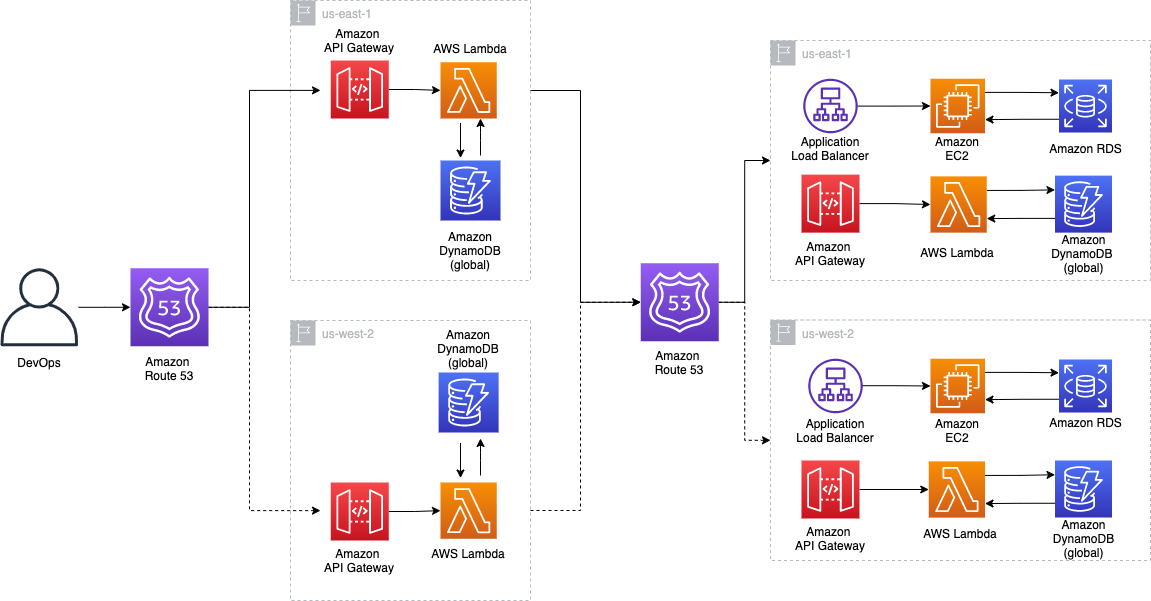
Figure 2. DR implementation architecture on multi-Region active/passive workloads
Deploying your multi-Region workload with AWS CodePipeline
In the multi-Region active/passive strategy, your workload handles full capacity in primary and secondary AWS Regions using AWS CloudFormation. By using AWS CodePipeline, one deploy stage within the pipeline will deploy the stack to the primary Region (Figure 3). After that, the same stack is copied to the secondary Region.
The workloads in the primary and secondary Regions will be treated as two different environments. However, they will run the same version of your application for consistency and availability in event of a failure.
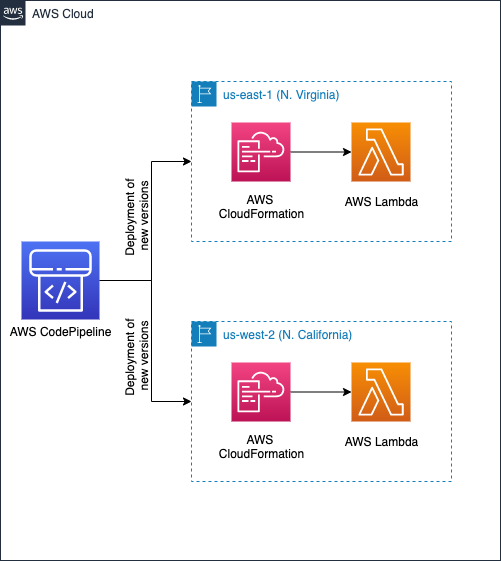
Figure 3. Deploying new versions to Lambda using CodePipeline and CloudFormation in two Regions
Fail over with event-driven serverless architecture
The event-driven serverless architecture performs failover by updating the weights of the Route 53 record. This shifts the traffic flow from the primary to the secondary Region. This operation specifies the source Region from where the failover is happening to the destination Region.
It is important to note that updating weights on a Route 53 record is a control plane action, and we recommend data plane actions when architecting for availability. For more information, see Control and data plane concepts in the Route 53 documentation.
For a given application, there will be two Route 53 records with the same name. The two records will point at two different endpoints for the application deployed in two different Regions.
The record will use a weighted policy with the weight as 100 for the record pointing at the endpoint in the primary Region. This means that all the request traffic will be served by the endpoint in the primary Region. Similarly, the second record will have weight as 0 and will be pointing to the endpoint in the secondary Region. This means none of the request traffic will reach that endpoint. This process can be repeated for multiple API endpoints. The information about the applications, like DNS records, endpoints, hosted zone IDs, Regions, and weights will all be stored in a DynamoDB table.
Then the Amazon API Gateway calls an AWS Lambda function that scans each item in an Amazon DynamoDB table. The API Gateway also updates the weighted policy of the Route 53 record and the DynamoDB table weight attribute.
The API Gateway, Lambda, function and global DynamoDB table will all be deployed in the primary and secondary Regions.
To make this architecture more resilient to failure, use data plane actions instead of control plane actions, as outlined in the Best practices for Amazon Route 53 DNS documentation.
Ensuring workload availability after a disaster
In the event of disaster, the data in the affected Region must be available in the recovery Region. In this section, we talk about fail over of databases like DynamoDB tables and Amazon Relational Database Service (Amazon RDS) databases.
Global DynamoDB tables
If you have two tables coexisting in two different Regions, any changes made to the table in the primary Region will be replicated to the secondary Region and vice versa. Once failover occurs, the request traffic moves through the recovery Region and connects to its databases, meaning your data and workloads are still working and available.
Amazon RDS database
Amazon RDS does not offer the same failover features that DynamoDB tables do. However, Amazon Aurora does offer a Global Database feature that creates a read-only replica cluster in other Regions.
To use this feature, follow the Getting started with Amazon Aurora global databases instructions. In case of a DR event, you can choose to promote the secondary cluster in the destination Region.
Approach
Initiating DR
The DR process can be initiated manually or automatically based on certain metrics like status checks, error rates, etc. If the established thresholds are reached for these metrics, it signifies the workloads in the primary Region are failing.
You can initiate the DR process automatically by invoking an API call that can initiate backend automation. This allows you to measure how resilient and reliable your workload is and how quickly you can switch traffic to another Region if a real disaster happens. Review designing a reliable failover mechanism to understand best practices in this area.
Failover
In our example, the failover process is initiated by the API Gateway invoking a Lambda function, as shown on the left side of the diagram in Figure 2. The Lambda function then performs failover by updating the weights of the Route 53 and DynamoDB table records. Similar steps can be performed for failing over database endpoints.
Once failover is complete, you’ll want to monitor traffic using Amazon CloudWatch. The List the available CloudWatch metrics for your instances user guide provides common metrics for you to monitor for Amazon Elastic Compute Cloud (Amazon EC2). The Amazon ECS CloudWatch metrics user guide provides common metrics to monitor for Amazon Elastic Container Service (Amazon ECS).
Failback
Once failover is successful and you’ve proven that traffic is being successfully routed to the new Region, you’ll failback to the primary Region. Similar metrics can be monitored in the secondary Region like you did in the Failover section.
Testing and results
Regularly test your DR process and evaluate the results and metrics. Based on the success and misses, you can make nearly continuous improvements in the DR process.
The critical applications within your organization will likely change over time, so it is important to evaluate which applications are mission critical and require an active/passive DR strategy. If an application is no longer mission critical, another DR strategy may be more appropriate.
Conclusion
The multi-Region active/passive strategy is one way to implement DR for applications hosted on AWS. It can fail over several applications in a short period of time by using serverless capabilities.
By using this strategy, your applications will be highly available and resilient to issues impacting Regional failures. It provides high business continuity, limits losses due to revenue reduction, and your customers will see minimum impact on performance efficiency, which is one of the pillars of AWS Well Architected Framework. By using this strategy, you can significantly reduce DR time by trading lower RTO and RPO for higher costs for critical applications.
Related information
- Disaster recovery options in the cloud
- Disaster Recovery (DR) Architecture on AWS, Part I: Strategies for Recovery in the Cloud
- Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery
- Disaster Recovery (DR) Architecture on AWS, Part III: Pilot Light and Warm Standby
- Disaster Recovery (DR) Architecture on AWS, Part IV: Multi-site Active/Active