Category: DynamoDB
New CloudWatch Events – Track and Respond to Changes to Your AWS Resources
When you pull the curtain back on an AWS-powered application, you’ll find that a lot is happening behind the scenes. EC2 instances are launched and terminated by Auto Scaling policies in response to changes in system load, Amazon DynamoDB tables, Amazon SNS topics and Amazon SQS queues are created and deleted, and attributes of existing resources are changed from the AWS Management Console, the AWS APIs, or the AWS Command Line Interface (CLI).
Many of our customers build their own high-level tools to track, monitor, and control the overall state of their AWS environments. Up until now, these tools have worked in a polling fashion. In other words, they periodically call AWS functions such as DescribeInstances, DescribeVolumes, and ListQueues to list the AWS resources of various types (EC2 instances, EBS volumes, and SQS queues here) and to track their state. Once they have these lists, they need to call other APIs to get additional state information for each resources, compare it against historical data to detect changes, and then take action as they see fit. As their systems grow larger and more complex, all of this polling and state tracking can become onerous.
New CloudWatch Events
In order to allow you to track changes to your AWS resources with less overhead and greater efficiency, we are introducing CloudWatch Events today.
 CloudWatch Events delivers a near real-time stream of system events that describe changes in AWS resources. Using simple rules that you can set up in a couple of minutes, you can easily route each type of event to one or more targets: AWS Lambda functions, Amazon Kinesis streams, Amazon SNS topics, and built-in targets.
CloudWatch Events delivers a near real-time stream of system events that describe changes in AWS resources. Using simple rules that you can set up in a couple of minutes, you can easily route each type of event to one or more targets: AWS Lambda functions, Amazon Kinesis streams, Amazon SNS topics, and built-in targets.
You can think of CloudWatch Events as the central nervous system for your AWS environment. It is wired in to every nook and cranny of the supported services, and becomes aware of operational changes as they happen. Then, driven by your rules, it activates functions and sends messages (activating muscles, if you will) to respond to the environment, making changes, capturing state information, or taking corrective action.
We are launching CloudWatch Events with an initial set of AWS services and events today, and plan to support many more over the next year or so.
Diving in to CloudWatch Events
The three main components that you need to know about are events, rules, and targets.
Events (represented as small blobs of JSON) are generated in four ways. First, they arise from within AWS when resources change state. For example, an event is generated when the state of an EC2 instance changes from pending to running or when Auto Scaling launches an instance. Second, events are generated by API calls and console sign-ins that are delivered to Amazon CloudWatch Events via CloudTrail. Third, your own code can generate application-level events and publish them to Amazon CloudWatch Events for processing. Fourth, they can be issued on a scheduled basis, with options for periodic or Cron-style scheduling.
Rules match incoming events and route them to one or more targets for processing. Rules are not processed in any particular order; all of the rules that match an event will be processed (this allows disparate parts of a single organization to independently look for and process events that are of interest).
Targets process events and are specified within rules. There are four initial target types: built-in, Lambda functions, Kinesis streams, and SNS topics, with more types on the drawing board. A single rule can specify multiple targets. Each event is passed to each target in JSON form. Each rule has the opportunity to customize the JSON that flows to the target. They can elect to pass the event as-is, pass only certain keys (and the associated values) to the target, or to pass a constant (literal) string.
CloudWatch Events in Action
Let’s go ahead and set up a rule or two! I’ll use a simple Lambda function called SomethingHappened. It will simply log the contents of the event:
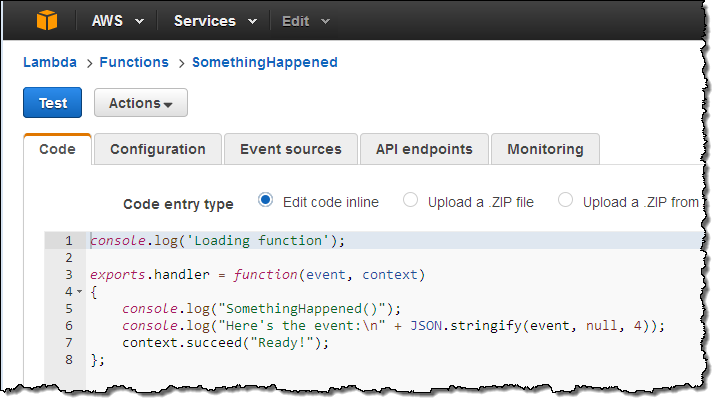
Next, I switch to the new CloudWatch Events Console, click on Create rule and choose an event source (here’s the menu with all of the choices):
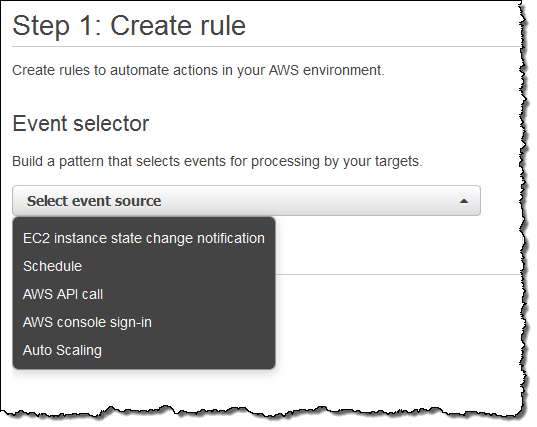
Just a quick note before going forward. Some of the AWS services fire events directly. Others are fired based on the events logged to CloudTrail; you’ll need to enable CloudTrail for the desired service(s) in order to receive them.
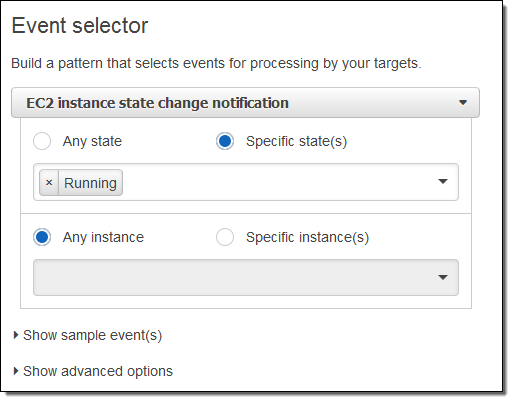
I want to keep tabs on my EC2 instances, so I choose EC2 from the menu. I can choose to create a rule that fires on any state transition, or on a transition to one or more states that are of interest:
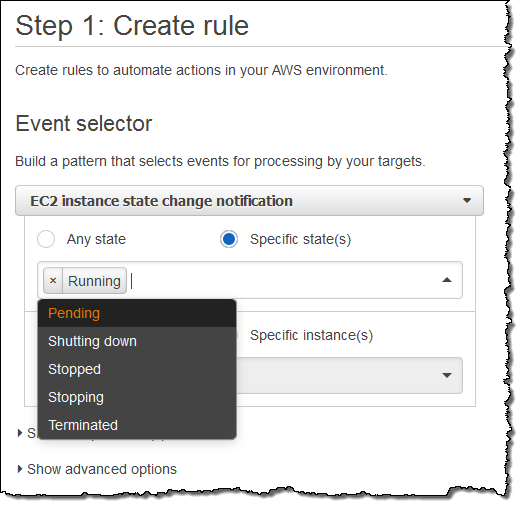
I want to know about newly launched instances, so I’ll choose Running. I can make the rule respond to any of my instances in the region, or to specific instances. I’ll go with the first option; here’s my pattern:
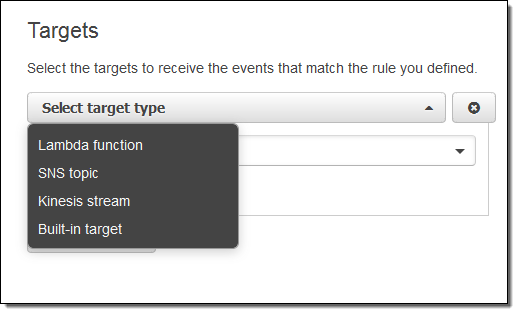
Now I need to make something happen. I do this by picking a target. Again, here are my choices:
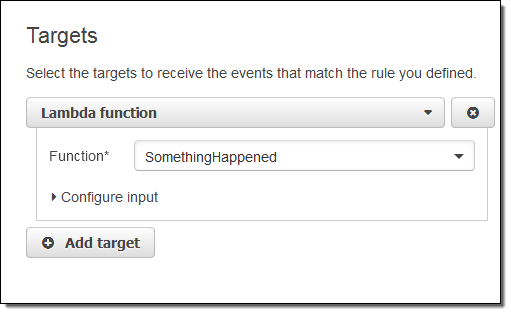
I simply choose Lambda and pick my function:
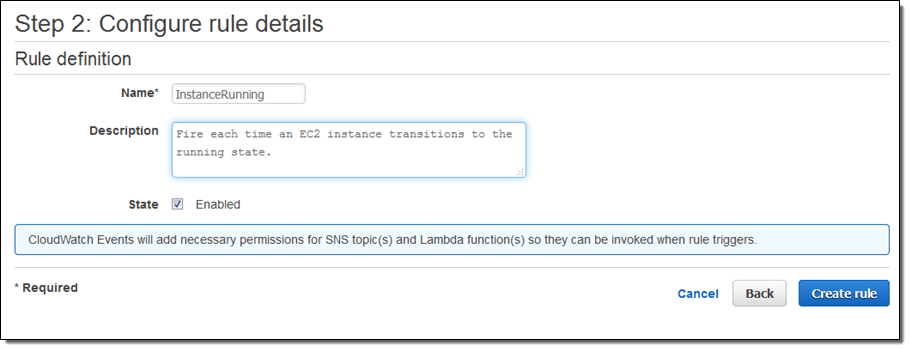
I’m almost there! I just need to name and describe my rule, and then click on Create rule:
I click on Create Rule and the rule is all set to go:
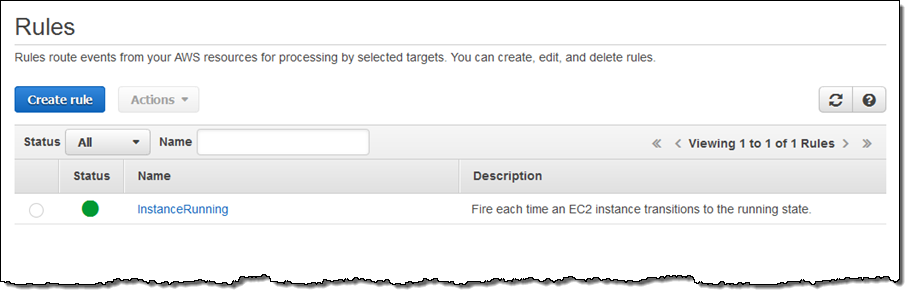
Now I can test it by launching an EC2 instance. In fact, I’ll launch 5 of them just to exercise my code! After waiting a minute or so for the instances to launch and to initialize, I can check my Lambda metrics to verify that my function was invoked:
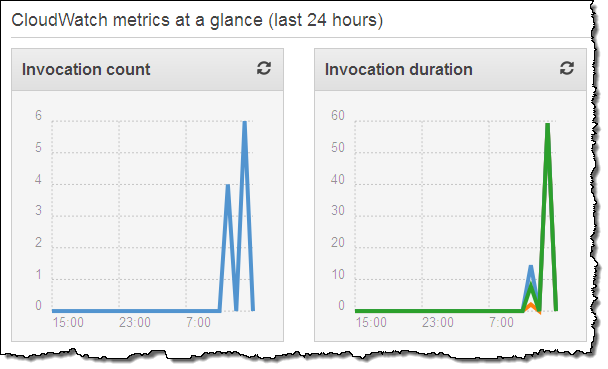
This looks good (the earlier invocations were for testing). Then I can visit the CloudWatch logs to view the output from my function:
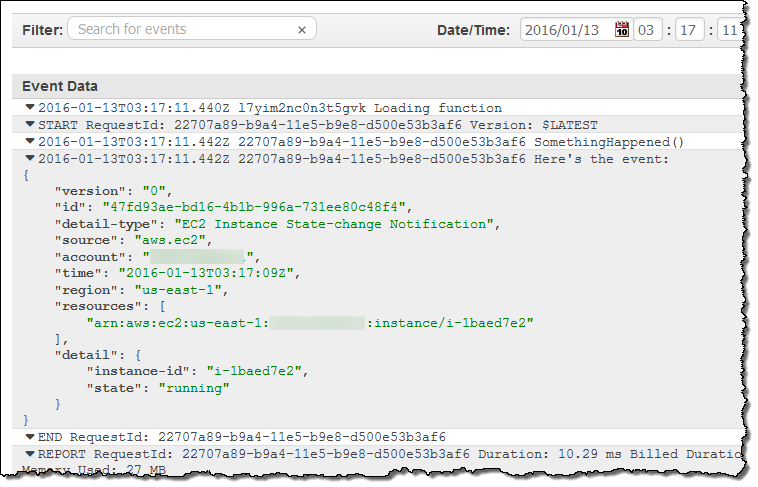
As you can see, the event contains essential information about the newly launched instance. Your code can call AWS functions in order to learn more about what’s going on. For example, you could call DescribeInstances to access more information about newly launched instances.
Clearly, a “real” function would do something a lot more interesting. It could add some mandatory tags to the instance, update a dynamic visualization, or send me a text message via SNS. If you want to do any (or all of these things), you would need to have a more permissive IAM role for the function, of course. I could make the rule more general (or create another one) if I wanted to capture some of the other state transitions.
Scheduled Execution of Rules
I can also set up a rule that fires periodically or according to a pattern described in a Cron expression. Here’s how I would do that:
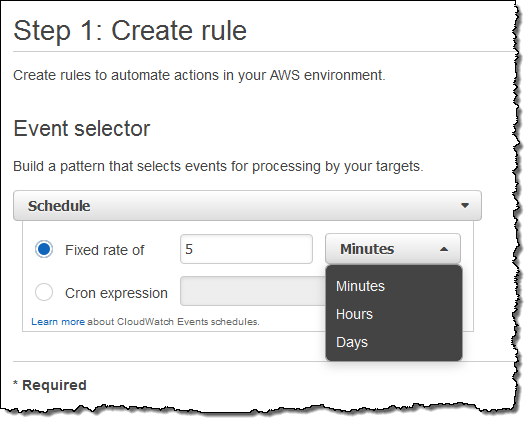
You might find it interesting to know that this is the underlying mechanism used to set up scheduled Lambda jobs, as announced at AWS re:Invent.
API Access
Like most AWS services, you can access CloudWatch Events through an API. Here are some of the principal functions:
PutRuleto create a new rule.PutTargetsandRemoveTargetsto connect targets to rules, and to disconnect them.ListRules,ListTargetsByRule, andDescribeRuleto find out more about existing rules.PutEventsto submit a set of events to CloudWatch events. You can use this function (or the CLI equivalent) to submit application-level events.
Metrics for Events
CloudWatch Events reports a number of metrics to CloudWatch, all within the AWS/Events namespace. You can use these metrics to verify that your rules are firing as expected, and to track the overall activity level of your rule collection.
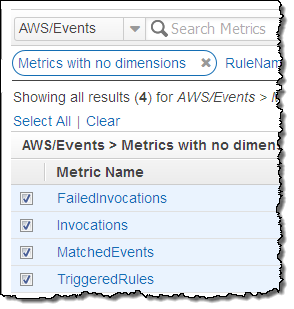 The following metrics are reported for the service as a whole:
The following metrics are reported for the service as a whole:
- Invocations – The number of times that target have been invoked.
- FailedInvocations – The number of times that an invocation of a target failed.
- MatchedEvents – The number of events that matched one or more rules.
- TriggeredRules – The number of rules that have been triggered.
The following metrics are reported for each rule:
- Invocations – The number of times that the rule’s targets have been invoked.
- TriggeredRules – The number of times that the rule has been triggered.
In the Works
Like many emerging AWS services, we are launching CloudWatch Events with an initial set of features (and a lot of infrastructure behind the scenes) and some really big plans, including AWS CloudFormation support. We’ll adjust our plans based on your feedback, but you can expect coverage of many more AWS services and access to additional targets over time. I’ll do my best to keep you informed.
Getting Started
We are launching CloudWatch Events in the US East (Northern Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo) regions. It is available now and you can start using it today!
— Jeff;
AWS Lambda – Run Code in the Cloud
We want to make it even easier for you to build applications that run in the Cloud. We want you to be able to focus on your code, and to work within a cloud-centric environment where scalability, reliability, and runtime efficiency are all high enough to be simply taken for granted!
 Today we are launching a preview of AWS Lambda, a brand-new way to build and run applications in the cloud, one that lets you take advantage of your existing programming skills and your knowledge of AWS. With Lambda, you simply create a Lambda function, give it permission to access specific AWS resources, and then connect the function to your AWS resources. Lambda will automatically run code in response to modifications to objects uploaded to Amazon Simple Storage Service (S3) buckets, messages arriving in Amazon Kinesis streams, or table updates in Amazon DynamoDB.
Today we are launching a preview of AWS Lambda, a brand-new way to build and run applications in the cloud, one that lets you take advantage of your existing programming skills and your knowledge of AWS. With Lambda, you simply create a Lambda function, give it permission to access specific AWS resources, and then connect the function to your AWS resources. Lambda will automatically run code in response to modifications to objects uploaded to Amazon Simple Storage Service (S3) buckets, messages arriving in Amazon Kinesis streams, or table updates in Amazon DynamoDB.
Lambda is a zero-administration compute platform. You don’t have to configure, launch, or monitor EC2 instances. You don’t have to install any operating systems or language environments. You don’t need to think about scale or fault tolerance and you don’t need to request or reserve capacity. A freshly created function is ready and able to handle tens of thousands of requests per hour with absolutely no incremental effort on your part, and on a very cost-effective basis.
Let’s dig in! We’ll take a more in-depth look at Lambda, sneak a peek at the programming model and runtime environment, and then walk through a programming example. As you read through this post, keep in mind that we have plenty of items on the Lambda roadmap and that what I am able to share today is just the first step on what we expect to be an enduring and feature-filled journey.
Lambda Concepts
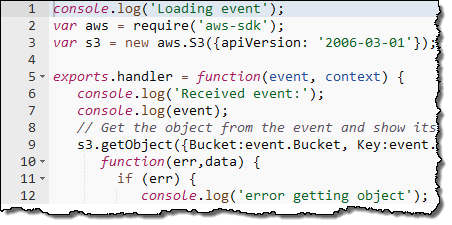 The most important Lambda concept is the Lambda function, or function for short. You write your functions in Node.js (an event-driven, server side implementation of JavaScript).
The most important Lambda concept is the Lambda function, or function for short. You write your functions in Node.js (an event-driven, server side implementation of JavaScript).
You upload your code and then specify context information to AWS Lambda to create a function. The context information specifies the execution environment (language, memory requirements, a timeout period, and IAM role) and also points to the function you’d like to invoke within your code. The code and the metadata are durably stored in AWS and can later be referred to by name or by ARN (Amazon Resource Name). You an also include any necessary third-party libraries in the upload (which takes the form of a single ZIP file per function).
After uploading, you associate your function with specific AWS resources (a particular S3 bucket, DynamoDB table, or Kinesis stream). Lambda will then arrange to route events (generally signifying that the resource has changed) to your function.
When a resource changes, Lambda will execute any functions that are associated with it. It will launch and manage compute resources as needed in order to keep up with incoming requests. You don’t need to worry about this; Lambda will manage the resources for you and will shut them down if they are no longer needed.
Lambda is accessible from the AWS Management Console, the AWS SDKs and the AWS Command Line Interface (CLI). The Lambda APIs are fully documented and can be used to connect existing code editors and other development tools to Lambda.
Lambda Programming Model
Functions are activated after the associated resource has been changed. Execution starts at the designated Node.js function and proceeds from there. The function has access (via a parameter supplied along with the POST) to a JSON data structure. This structure contains detailed information about the change (or other event) that caused the function to be activated.
Lambda will activate additional copies of function as needed in order to keep pace with changes. The functions cannot store durable state on the compute instance and should use S3 or DynamoDB instead.
Your code can make use of just about any functionality that is intrinsic to Node.js and to the underlying Linux environment. It can also use the AWS SDK for JavaScript in Node.js to make calls to other AWS services.
Lambda Runtime Environment
The context information that you supply for each function specifies a maximum execution time for the function. This is typically set fairly low (you can do a lot of work in a couple of seconds) but can be set to up 60 seconds as your needs dictate.
Lambda uses multiple IAM roles to manage access to your functions and your AWS resources. The invocation role gives Lambda permission to run a particular function. The execution role gives a function permission to access specific AWS resources. You can use distinct roles for each function in order to implement a fine-grained set of permissions.
Lambda monitors the execution of each function and stores request count, latency, availability, and error rate metrics in Amazon CloudWatch. The metrics are retained for 30 days and can be viewed in the Console.
Here are a few things to keep in mind when as you start to think about how you will put Lambda to use:
- The context information for a function specifies the amount of memory needed to run it. You can set this to any desired value between 128 MB and 1 GB. The memory setting also determines the amount of CPU power, network bandwidth, and I/O bandwidth that are made available to the function.
- Each invocation of a function can make use of up to 256 processes or threads. It can consume up to 512 MB of local storage and up to 1,024 file descriptors.
- Lambda imposes a set of administrative limits on each AWS account. During the preview, you can have up to 25 invocation requests underway simultaneously.
Lambda in Action
Let’s step through the process of creating a simple function using the AWS Management Console. As I mentioned earlier, you can also do this from the SDKs and the CLI. The console displays all of my functions:
I simply click on Create Function to get started. Then I fill in all of the details:
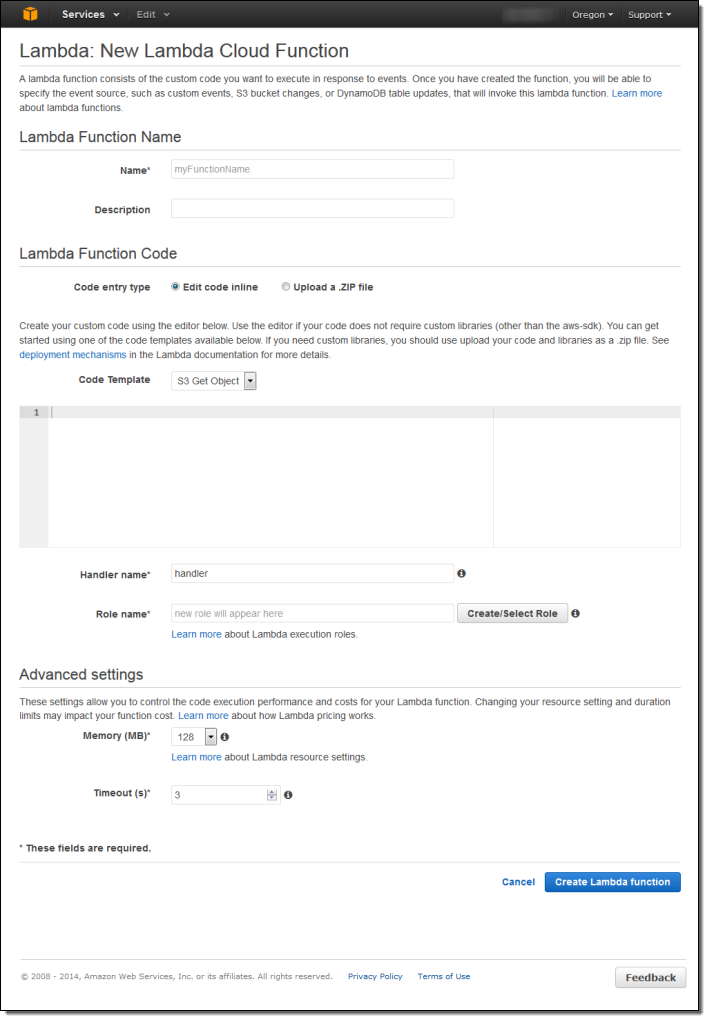
I name and describe my function:

Then I enter the code or upload a ZIP file. The console also offers a choice of sample code snippets to help me to get started:
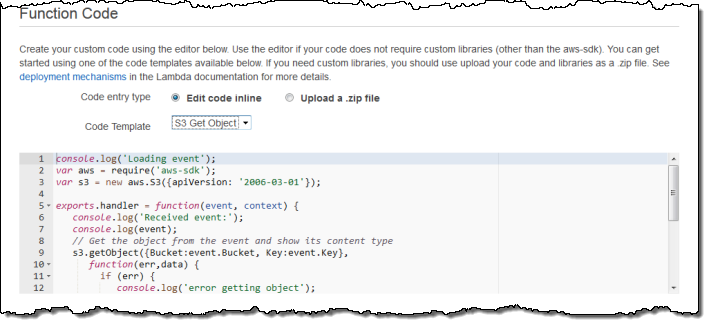
Now I tell Lambda which function to run and which IAM role to use when the code runs:
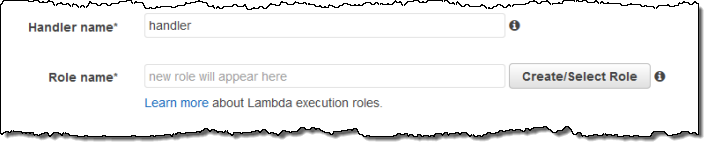
I can also fine-tune the memory requirements and set a limit on execution time:
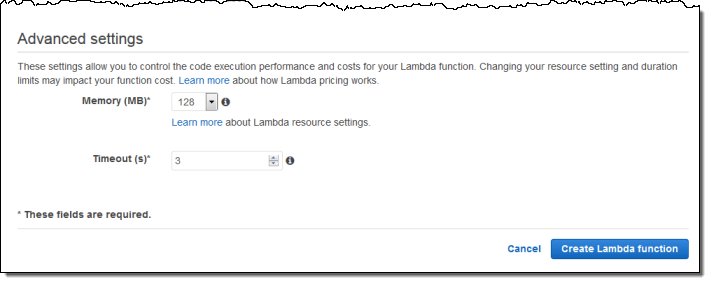
After I create my function, I can iteratively edit and test it from within the Console. As you can see, the pane on the left shows a sample of the JSON data that will be passed to my function:
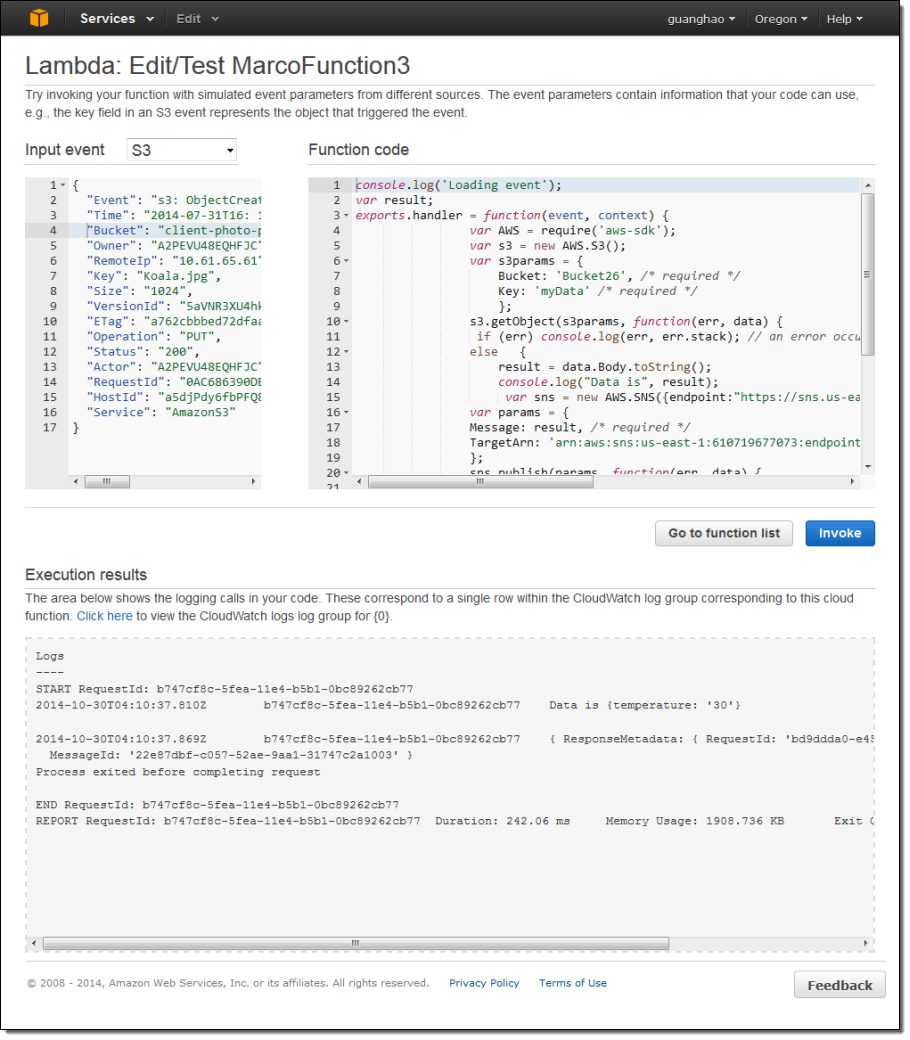
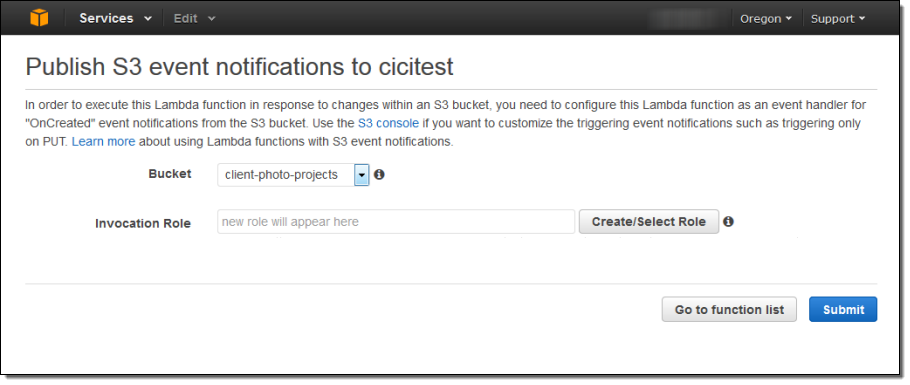
When the function is working as expected, I can attach it to an event source such as Amazon S3 event notification. I will to provide an invocation role in order to give S3 the permission that it needs to have in order to invoke the function:
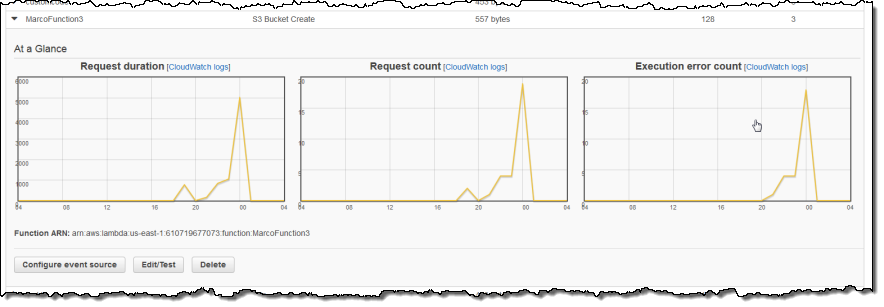
Lambda collects a set of metrics for each of my functions and sends them to Amazon CloudWatch. I can view the metrics from the Console:
On the Roadmap
We have a great roadmap for Lambda! While I won’t spill all of the beans today, I will tell you that we expect to add support for additional AWS services and other languages. As always, we love your feedback; please leave a note in the Lambda Forum.
Pricing & Availability
Let’s talk about pricing a bit before wrapping up! Lambda uses a fine-grained pricing model. You pay for compute time in units of 100 milliseconds and you pay for each request. The Lambda free tier includes 1 million free requests per month and up to 3.2 million seconds of compute time per month depending on the amount of memory allocated per function.
Lambda is available today in preview form in the US East (Northern Virginia), US West (Oregon), and Europe (Ireland) Regions. If you would like to get started, register now.
— Jeff;
Sneak Preview – DynamoDB Streams
I would like to give you a quick, sneak preview of a new Amazon DynamoDB feature. We will be demonstrating it at AWS re:Invent and making it available to curious developers and partners for testing and feedback.
Many AWS customers are using DynamoDB as the primary storage mechanism for their applications. Some of them use it as a key-value store, some of them denormalize their relational schemas in accordance with the NoSQL philosophy, and others make use of the new support for JSON documents.
DynamoDB Streams
Many of our customers have let us know that they would like to track the changes made to their DynamoDB tables. They would like to build and update caches, run business processes, drive real-time analytics, and create global replicas.
The new DynamoDB Streams feature is designed to address this very intriguing use case. Once you enable it for a DynamoDB table, all changes (puts, updates, and deletes) made to the table are tracked on a rolling 24-hour basis. You can retrieve this stream of update records with a single API call and use the results to build tools and applications that function as described above. You have full control over the records that appear in the DynamoDB Stream: no values, all values, or changed values.
If you are building mobile, ad-tech, gaming, web or IoT applications, you can use the DynamoDB Streams capability to make your applications respond to high velocity data changes without having to track the changes yourself. With the recent free tier increase (now including 25 GB of storage and over 200 million requests per month), you can try DynamoDB for your new applications at little or no cost.
This feature will be accessible from the AWS Management Console. You’ll be able to enable it for existing tables by clicking Modify Table. You will also be able to enable it when you create a new table. Once enabled, changes will be visible in a new Streams tab.
You will be able to retrieve updates at roughly twice the rate of the provisioned write capacity of your table. If you have provisioned enough capacity to perform 1,000 updates per second to a table, you can retrieve up to 2,000 per second. The stream will contain every update made to the table. If multiple updates are made to the same item in the table, those updates will show up in the stream in the same order in which they are made. Updates will be stored for 24 hours, and will stick around for the same amount of time after a table has been deleted.
We will be updating the Kinesis Client Library with support for DynamoDB Streams. We also plan to provide connectors for Amazon CloudSearch, Amazon Redshift, and other relevant AWS services.
Get Started Today
 The preliminary documentation contains more information about the newest additions to the DynamoDB API along with a download link for a version of DynamoDB Local that already includes an initial implementation of DynamoDB Streams. It also includes references to an updated AWS SDK for Java, the updated Kinesis Client Library, and a cool library that will show you how to implement Multi-Master Cross Region Replication.
The preliminary documentation contains more information about the newest additions to the DynamoDB API along with a download link for a version of DynamoDB Local that already includes an initial implementation of DynamoDB Streams. It also includes references to an updated AWS SDK for Java, the updated Kinesis Client Library, and a cool library that will show you how to implement Multi-Master Cross Region Replication.
The Cross Region Replication Library is a preview release of an application that uses DynamoDB Streams to keep DynamoDB tables in sync across multiple regions in near real time. When you write to a DynamoDB table in one region, those changes are automatically propagated by the Cross Region Replication Library to your tables in other regions.
I will share additional news about availability of DynamoDB Streams just as soon as I have it. If you would like to get an early start, please contact us and tell us more. We are especially interested in speaking to anyone who’s interested in integrating this feature with other storage, processing, and analytical tools.
— Jeff;
