Category: CloudWatch
Using Enhanced RDS Monitoring with Datadog
Today’s guest post comes from K Young, Director of Strategic Initiatives at Datadog!
— Jeff;AWS recently announced enhanced monitoring for Amazon RDS instances running MySQL, MariaDB, and Aurora. Enhanced monitoring includes over 50 new CPU, memory, file system, and disk I/O metrics which can be collected on a per-instance basis as frequently as once per second.
AWS and Datadog
AWS worked closely with Datadog to help customers send this new high-resolution data to Datadog for monitoring. Datadog is an infrastructure monitoring platform that is very popular with AWS customers—you can see historical trends with full granularity and also visualize and alert on live data from any part of your stack.
With a few minutes of work your enhanced RDS metrics will immediately begin populating a pre-built, customizable dashboard in Datadog:
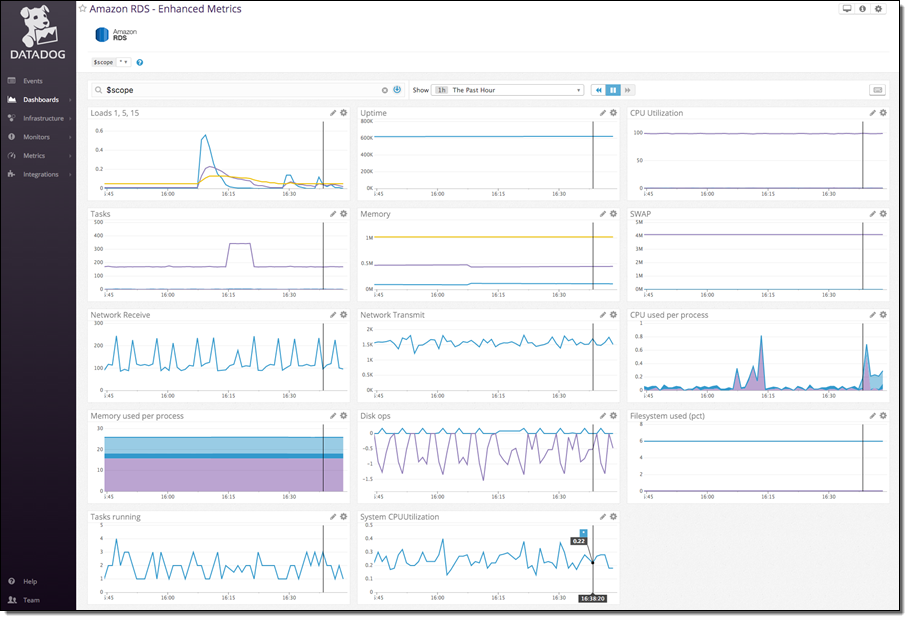
Connect RDS and Datadog
The first step is to send enhanced RDS metrics to CloudWatch Logs. You can enable the metrics during instance creation, or on an existing RDS instance by selecting it in the RDS Console and then choosing Instance Options → Modify:
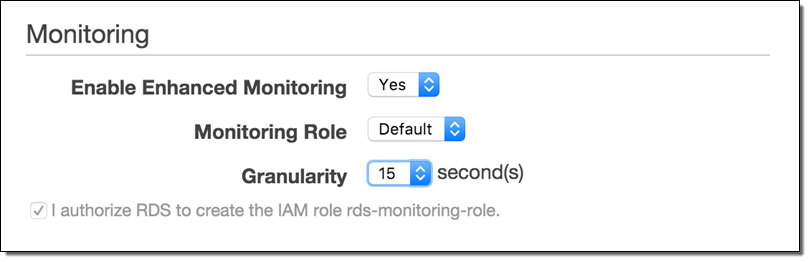
Set Granularity to 1–60 seconds; every 15 seconds is often a good choice. Once enabled, enhanced metrics will be sent to CloudWatch Logs.
The second step is to send the CloudWatch Log data to Datadog. Begin by setting up a Lambda function to process the logs and send the metrics:
- Create a role for your Lambda function. Name it something like
lambda-datadog-enhanced-rds-collectorand select AWS Lambda as the role type.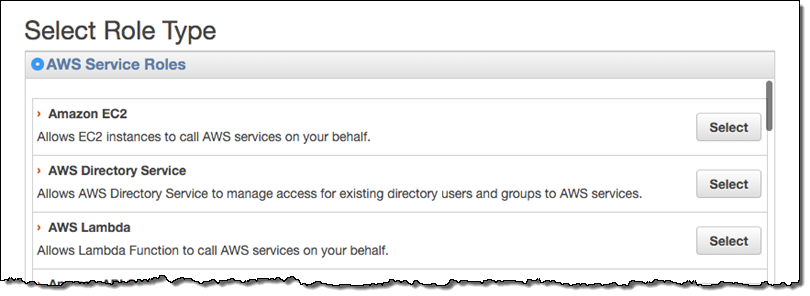
- From the Encryption Keys tab on the IAM Management Console, create a new encryption key. Enter an Alias for the key like
lambda-datadog-key. On the next page, add the appropriate administrators for the key. Next you’ll be prompted to add users to the key. Add at least two: yourself (so that you can encrypt the Datadog API key from the AWS CLI in the next step), and the role created above, e.g.lambda-datadog-enhanced-rds-collector(so that it can decrypt the API key and submit metrics to Datadog). Finish creating the key. - Encrypt the token using the AWS Command Line Interface (CLI), providing the Alias of your just-created key (e.g.
lambda-datadog-key) as well as your Datadog keys, available here. Use KMS to encrypt your key, like this:$ aws kms encrypt --key-id alias/ALIAS_KEY_NAME --plaintext '{"api_key":"DATADOG_API_KEY", "app_key":"DATADOG_APP_KEY"}'Save the output of this command; you will need it for the next step.
- From the Lambda Management Console, create a new Lambda Function. Filter blueprints by datadog, and select the
datadog-process-rds-metricsblueprint. - Choose RDSOSMetrics from the Log Group dropdown, enter the Filter Name of your choice, and go to the next page. If you have not yet enabled enhanced monitoring, you must do so before RDSOSMetrics will be presented an as option (see the instructions under Connect RDS and Datadog above):
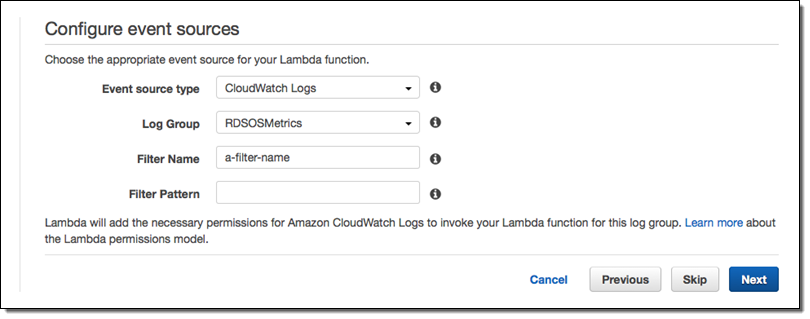
- Give your function a name like
send-enhanced-rds-to-datadog. In the Lambda function code area, replace the string after KMS_ENCRYPTED_KEYS with the ciphertext blob part of the CLI command output above.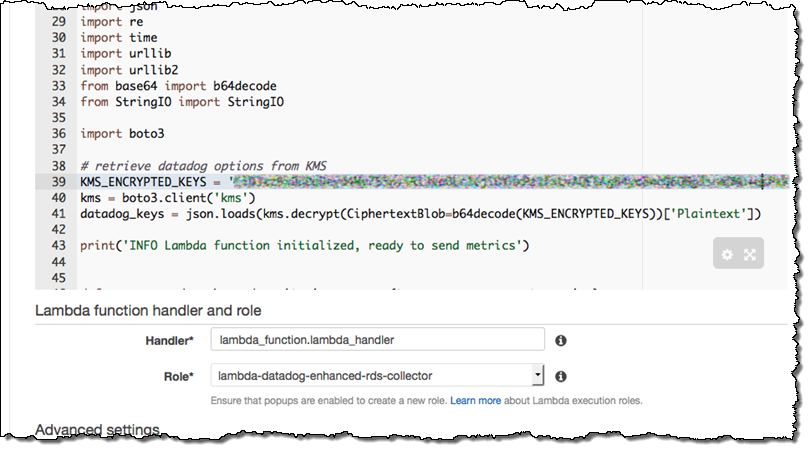
- Under Lambda function handler and role, choose the role you created in step 2, e.g.
lambda-datadog-enhanced-rds-collector. Go to the next page, select the Enable Now radio button, and create your function.
That’s It
Once you have enabled RDS in Datadog’s AWS integration tile, Datadog will immediately begin displaying your enhanced RDS metrics. Your RDS instances will be individually identifiable in Datadog via automatically-created tags of the form dbinstanceidentifier:YOUR_DB_INSTANCE_NAME, as well as any tags you added through the RDS console.
You can clone the pre-built dashboard and customize it however you want: add RDS metrics that are not displayed by default, or start correlating RDS metrics with the performance of the rest of your stack.
— K Young, Director of Strategic Initiatives
New CloudWatch Events – Track and Respond to Changes to Your AWS Resources
When you pull the curtain back on an AWS-powered application, you’ll find that a lot is happening behind the scenes. EC2 instances are launched and terminated by Auto Scaling policies in response to changes in system load, Amazon DynamoDB tables, Amazon SNS topics and Amazon SQS queues are created and deleted, and attributes of existing resources are changed from the AWS Management Console, the AWS APIs, or the AWS Command Line Interface (CLI).
Many of our customers build their own high-level tools to track, monitor, and control the overall state of their AWS environments. Up until now, these tools have worked in a polling fashion. In other words, they periodically call AWS functions such as DescribeInstances, DescribeVolumes, and ListQueues to list the AWS resources of various types (EC2 instances, EBS volumes, and SQS queues here) and to track their state. Once they have these lists, they need to call other APIs to get additional state information for each resources, compare it against historical data to detect changes, and then take action as they see fit. As their systems grow larger and more complex, all of this polling and state tracking can become onerous.
New CloudWatch Events
In order to allow you to track changes to your AWS resources with less overhead and greater efficiency, we are introducing CloudWatch Events today.
 CloudWatch Events delivers a near real-time stream of system events that describe changes in AWS resources. Using simple rules that you can set up in a couple of minutes, you can easily route each type of event to one or more targets: AWS Lambda functions, Amazon Kinesis streams, Amazon SNS topics, and built-in targets.
CloudWatch Events delivers a near real-time stream of system events that describe changes in AWS resources. Using simple rules that you can set up in a couple of minutes, you can easily route each type of event to one or more targets: AWS Lambda functions, Amazon Kinesis streams, Amazon SNS topics, and built-in targets.
You can think of CloudWatch Events as the central nervous system for your AWS environment. It is wired in to every nook and cranny of the supported services, and becomes aware of operational changes as they happen. Then, driven by your rules, it activates functions and sends messages (activating muscles, if you will) to respond to the environment, making changes, capturing state information, or taking corrective action.
We are launching CloudWatch Events with an initial set of AWS services and events today, and plan to support many more over the next year or so.
Diving in to CloudWatch Events
The three main components that you need to know about are events, rules, and targets.
Events (represented as small blobs of JSON) are generated in four ways. First, they arise from within AWS when resources change state. For example, an event is generated when the state of an EC2 instance changes from pending to running or when Auto Scaling launches an instance. Second, events are generated by API calls and console sign-ins that are delivered to Amazon CloudWatch Events via CloudTrail. Third, your own code can generate application-level events and publish them to Amazon CloudWatch Events for processing. Fourth, they can be issued on a scheduled basis, with options for periodic or Cron-style scheduling.
Rules match incoming events and route them to one or more targets for processing. Rules are not processed in any particular order; all of the rules that match an event will be processed (this allows disparate parts of a single organization to independently look for and process events that are of interest).
Targets process events and are specified within rules. There are four initial target types: built-in, Lambda functions, Kinesis streams, and SNS topics, with more types on the drawing board. A single rule can specify multiple targets. Each event is passed to each target in JSON form. Each rule has the opportunity to customize the JSON that flows to the target. They can elect to pass the event as-is, pass only certain keys (and the associated values) to the target, or to pass a constant (literal) string.
CloudWatch Events in Action
Let’s go ahead and set up a rule or two! I’ll use a simple Lambda function called SomethingHappened. It will simply log the contents of the event:
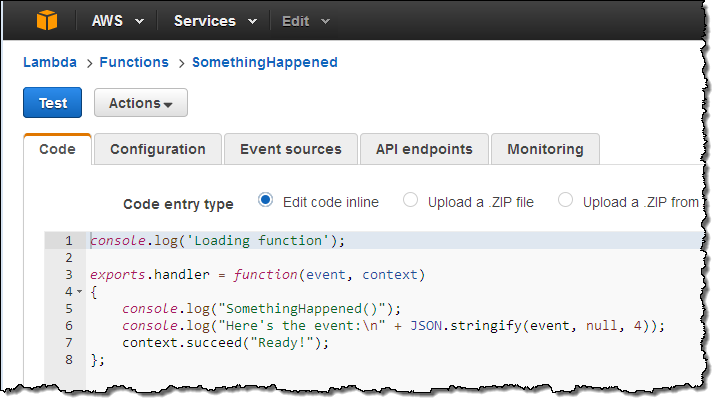
Next, I switch to the new CloudWatch Events Console, click on Create rule and choose an event source (here’s the menu with all of the choices):
Just a quick note before going forward. Some of the AWS services fire events directly. Others are fired based on the events logged to CloudTrail; you’ll need to enable CloudTrail for the desired service(s) in order to receive them.
I want to keep tabs on my EC2 instances, so I choose EC2 from the menu. I can choose to create a rule that fires on any state transition, or on a transition to one or more states that are of interest:
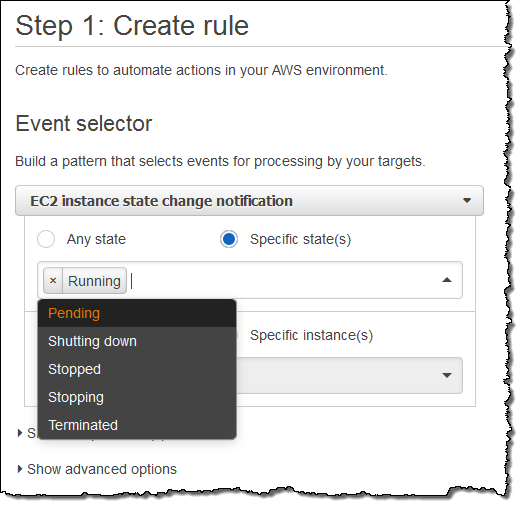
I want to know about newly launched instances, so I’ll choose Running. I can make the rule respond to any of my instances in the region, or to specific instances. I’ll go with the first option; here’s my pattern:
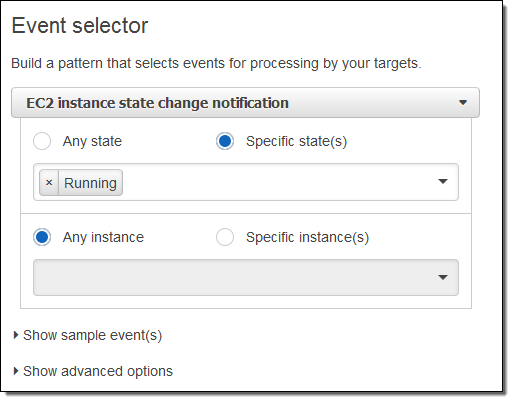
Now I need to make something happen. I do this by picking a target. Again, here are my choices:
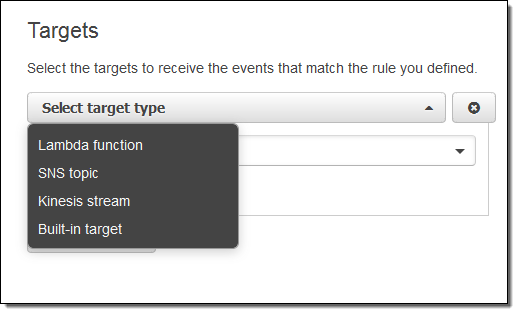
I simply choose Lambda and pick my function:
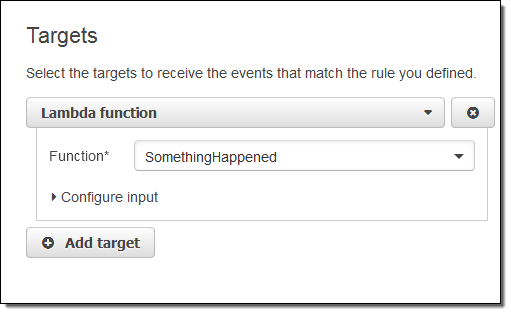
I’m almost there! I just need to name and describe my rule, and then click on Create rule:
I click on Create Rule and the rule is all set to go:
Now I can test it by launching an EC2 instance. In fact, I’ll launch 5 of them just to exercise my code! After waiting a minute or so for the instances to launch and to initialize, I can check my Lambda metrics to verify that my function was invoked:
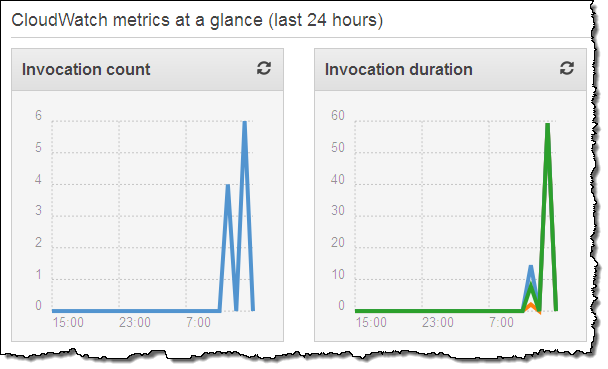
This looks good (the earlier invocations were for testing). Then I can visit the CloudWatch logs to view the output from my function:
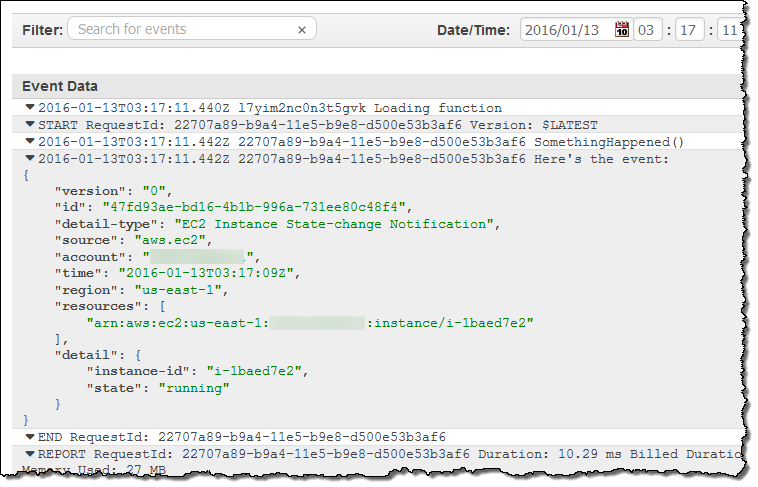
As you can see, the event contains essential information about the newly launched instance. Your code can call AWS functions in order to learn more about what’s going on. For example, you could call DescribeInstances to access more information about newly launched instances.
Clearly, a “real” function would do something a lot more interesting. It could add some mandatory tags to the instance, update a dynamic visualization, or send me a text message via SNS. If you want to do any (or all of these things), you would need to have a more permissive IAM role for the function, of course. I could make the rule more general (or create another one) if I wanted to capture some of the other state transitions.
Scheduled Execution of Rules
I can also set up a rule that fires periodically or according to a pattern described in a Cron expression. Here’s how I would do that:
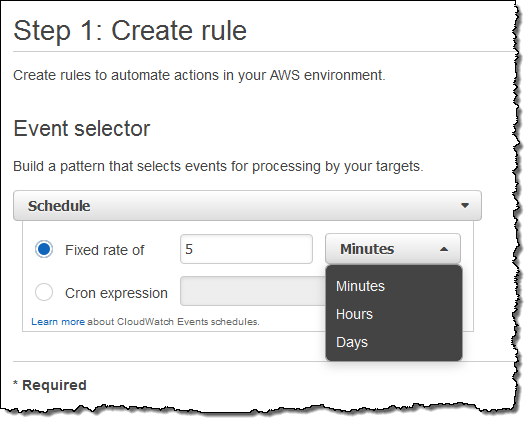
You might find it interesting to know that this is the underlying mechanism used to set up scheduled Lambda jobs, as announced at AWS re:Invent.
API Access
Like most AWS services, you can access CloudWatch Events through an API. Here are some of the principal functions:
PutRuleto create a new rule.PutTargetsandRemoveTargetsto connect targets to rules, and to disconnect them.ListRules,ListTargetsByRule, andDescribeRuleto find out more about existing rules.PutEventsto submit a set of events to CloudWatch events. You can use this function (or the CLI equivalent) to submit application-level events.
Metrics for Events
CloudWatch Events reports a number of metrics to CloudWatch, all within the AWS/Events namespace. You can use these metrics to verify that your rules are firing as expected, and to track the overall activity level of your rule collection.
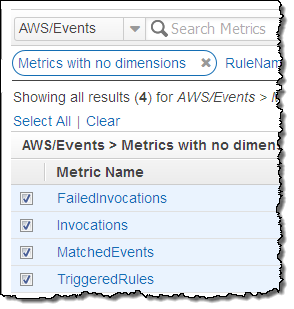 The following metrics are reported for the service as a whole:
The following metrics are reported for the service as a whole:
- Invocations – The number of times that target have been invoked.
- FailedInvocations – The number of times that an invocation of a target failed.
- MatchedEvents – The number of events that matched one or more rules.
- TriggeredRules – The number of rules that have been triggered.
The following metrics are reported for each rule:
- Invocations – The number of times that the rule’s targets have been invoked.
- TriggeredRules – The number of times that the rule has been triggered.
In the Works
Like many emerging AWS services, we are launching CloudWatch Events with an initial set of features (and a lot of infrastructure behind the scenes) and some really big plans, including AWS CloudFormation support. We’ll adjust our plans based on your feedback, but you can expect coverage of many more AWS services and access to additional targets over time. I’ll do my best to keep you informed.
Getting Started
We are launching CloudWatch Events in the US East (Northern Virginia), US West (Oregon), Europe (Ireland), and Asia Pacific (Tokyo) regions. It is available now and you can start using it today!
— Jeff;
New Metrics for EC2 Container Service: Clusters & Services
 The Amazon EC2 Container Service helps you to build, run, and scale Docker-based applications. As I noted in an earlier post (EC2 Container Service – Latest Features, Customer Successes, and More), you will benefit from easy cluster management, high performance, flexible scheduling, extensibility, portability, and AWS integration while running in an AWS-powered environment that is secure and efficient.
The Amazon EC2 Container Service helps you to build, run, and scale Docker-based applications. As I noted in an earlier post (EC2 Container Service – Latest Features, Customer Successes, and More), you will benefit from easy cluster management, high performance, flexible scheduling, extensibility, portability, and AWS integration while running in an AWS-powered environment that is secure and efficient.
Container-based applications are built from tasks. A task is one or more Docker containers that run together on the same EC2 instance; instances are grouped in to a cluster. The instances form a pool of resources that can be used to run tasks.
This model creates some new measuring and monitoring challenges. In order to keep the cluster at an appropriate size (not too big and not too small), you need to watch memory and CPU utilization for the entire cluster rather than for individual instances. This becomes even more challenging when a single cluster contains EC2 instances with varied amounts of compute power and memory.
New Cluster Metrics
In order to allow you to properly measure, monitor, and scale your clusters, we are introducing new metrics that are collected from individual instances, normalized based on the instance size and the container configuration, and then reported to Amazon CloudWatch. You can observe the metrics in the AWS Management Console and you can use them to drive Auto Scaling activities.
The ECS Container Agent runs on each of the instances. It collects the CPU and memory metrics at the instance and task level, and sends them to a telemetry service for normalization. The normalization process creates blended metrics that represent CPU and memory usage for the entire cluster. These metrics give you a picture of overall cluster utilization.
Let’s take a look! My cluster is named default and it has one t2.medium instance:
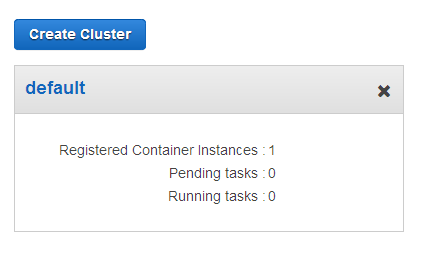
At this point no tasks are running and the cluster is idle:
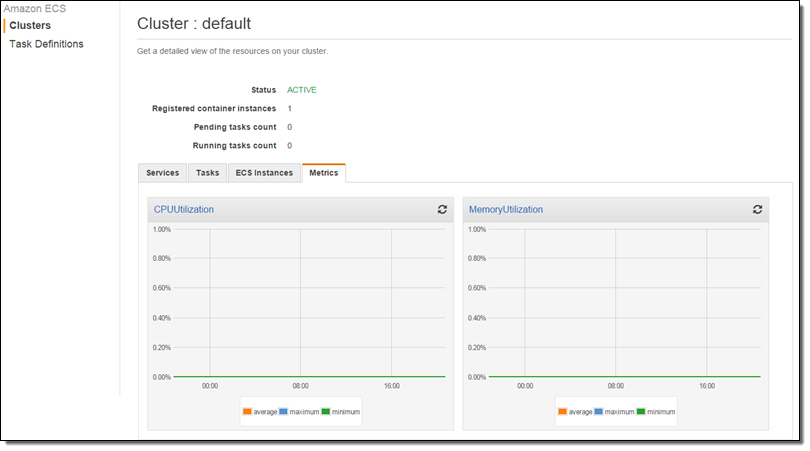
I ran two tasks (as a service) with the expectation that they will consume all of the CPU:
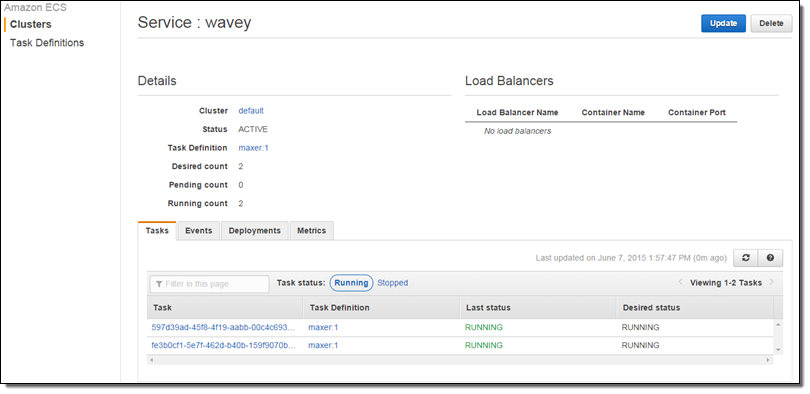
I took a short break to water my garden while the task burned some CPU and the metrics accumulated! I came back and here’s what the CPU Utilization looked like:
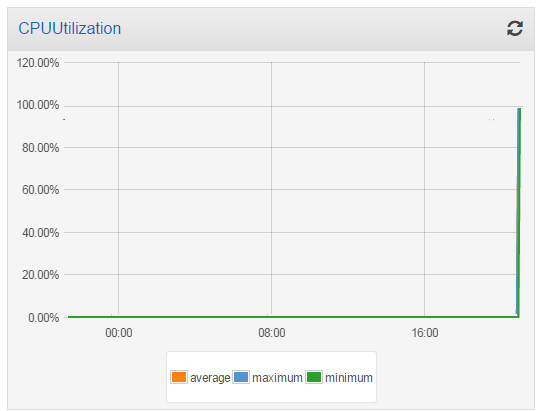
Then I launched another t2.medium instance into my cluster, and checked the utilization again. The additional processing power reduced the overall utilization to 50%:
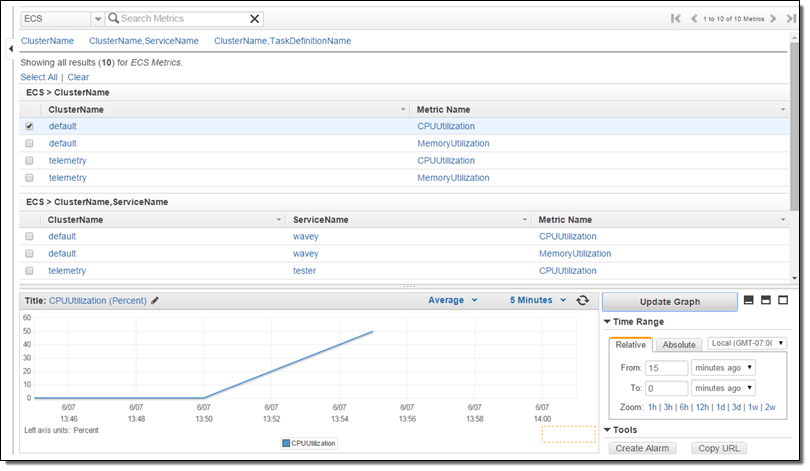
The new metrics (CPUUtilization and MemoryUtilization) are available via CloudWatch and can also be used to create alarms. Here’s how to find them:
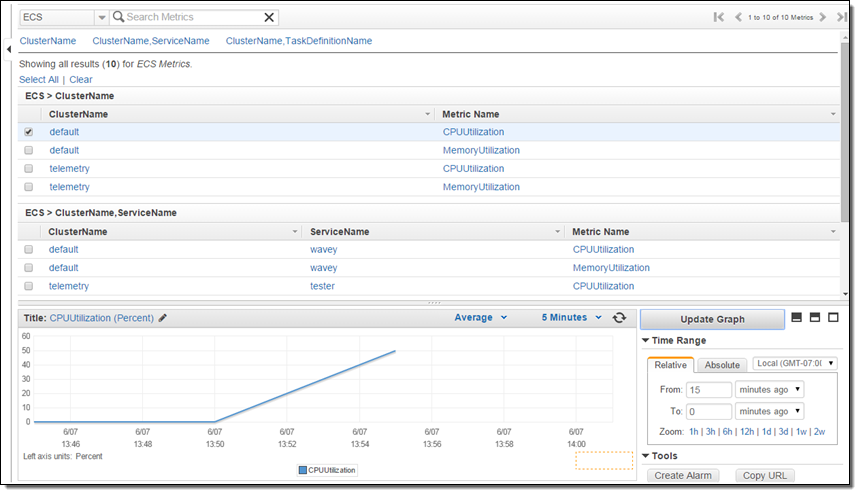
New Service Metrics
Earlier this year we announced that the EC2 Container Service supports long-running applications and load balancing. The Service scheduler allows you to manage long-running applications and services by keeping them healthy and scaled to the desired level. CPU and memory utilization metrics are now collected and processed on a per-service basis, and are visible in the Console:
The new cluster and server metrics are available now and you can start using them today!
— Jeff;
New – CloudTrail Integration with CloudWatch Logs; 2 Partner Solutions
As you may know, AWS CloudTrail records API activity in your AWS account and delivers a log file with the recorded API activity to a designated S3 bucket (see my post, AWS CloudTrail – Capture AWS API Activity, for more info). Earlier this year we announced CloudWatch Logs and gave you the ability to store and monitor OS and application log files. As I told you at the time, CloudWatch Logs gives you the ability to monitor for specific phrases, values or patterns.
CloudTrail, Meet CloudWatch
Today, we are announcing CloudTrail integration with CloudWatch Logs. This integration enables you to receive SNS notifications from CloudWatch, triggered by specific API activity captured by CloudTrail.
With SNS notifications, you can take immediate action when a pattern of interest is detected. You can contact the affected user to learn more, automatically create a trouble ticket, or initiate other troubleshooting operations. For example, you can create a CloudWatch Logs metric filter that watches for API calls related to a VPC, then create a CloudWatch metric and CloudWatch alarm and receive SNS notifications when the metric count exceeds the threshold values you specify.
Once you turn on this integration from the CloudTrail console, CloudTrail will deliver log files containing API activity to the CloudWatch log group that you specify:
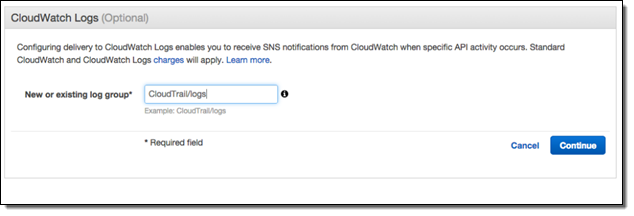
As with any AWS feature, you can turn on this integration using the AWS Command Line Interface (CLI) or one of the AWS SDKs. CloudTrail will continue to deposit log files in the designated S3 bucket even after you enable this new integration feature.
Setting Metrics, Filters, and Alarms
Now that I have turned on the integration, I need to create CloudWatch metric filters, metrics and alarms to receive SNS notifications and take immediate action. Suppose I want to receive an SNS notification whenever an authorization failure occurs for your AWS account. We can set this up in three steps!
Since, CloudTrail provides an error code in its payload whenever an API call fails due to improper or insufficient permission, I can scan the CloudTrail events for the strings “AccessDenied” and “UnauthorizedOperation” using a Metric Filter:
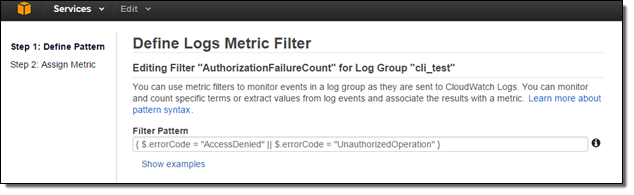
Now I need to set the filter up so that it generates a CloudWatch metric named “AuthorizationFailureCount” in the “LogMetrics” namespace. Each occurrence of “AccessDenied” or “UnauthorizedOperation” will increase the value (count) of the metric by 1:
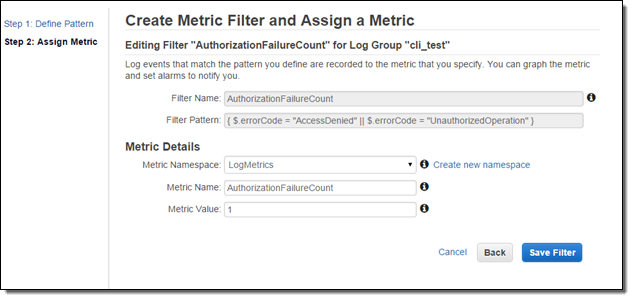
Now I can create a CloudWatch alarm and set up a threshold. Since I want to now about every authorization failure, I will set the alarm threshold so that the alarm will fire if one or more failures occur per minute. You can, of course, customize this as needed.
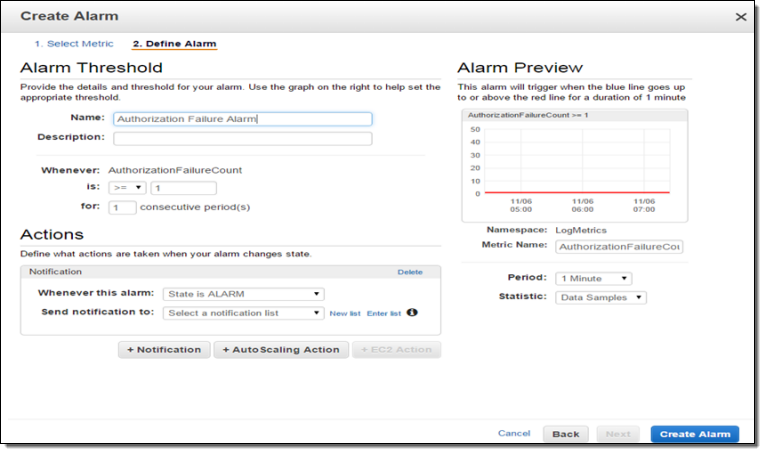
I can test this by creating an email subscription to my SNS topic and then initiating an operation that results in a failed authorization. The notification text will read as follows:
You are receiving this email because your Amazon CloudWatch Alarm “AuthorizationFailureCount” in the US – N. Virginia region has entered the ALARM state, because “Threshold Crossed: 1 datapoint (3.0) was greater than the threshold (1.0).” at “Wednesday 05 November, 2014 19:12:58 UTC
As you can see, the process of connecting CloudTrail to CloudWatch and setting up SNS notifications takes just a few minutes. The CloudTrail team is very interested in your feedback on this new feature. They are particularly interested in learning more about specific APIs and API activities you would like to monitor. Please visit the CloudTrail Forum and leave some feedback for them!
Pricing and Availability
This integration is currently available in the Regions where CloudWatch Logs are supported: US East (Northern Virginia),US West (Oregon), and Europe (Ireland). You will incur standard CloudWatch logs and CloudWatch charges.
Support from Partners
AWS Partners CloudNexa and Graylog2 have announced tools that analyze CloudTrail log files.
CloudNexa (a premier consulting partner and AWS reseller) provides Cloud Management as a Service. They are providing their new CloudTrail functionality at no charge at part of their vNOC Platform. You can use this tool to view CloudTrail events by region or to look at the most popular API Calls and most frequently used services. You can also filter out irrelevant events and quickly drill down to those that are of interest to you. Here’s a snapshot of the VNOC dashboard:
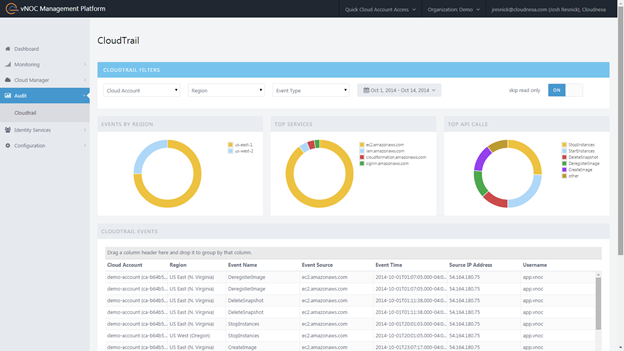
To learn more, visit their site or watch their one minute video.
Graylog2 is an open source solution that allows you to combine log files from CloudTrail with your operating system or application logs. Once these events are ingested, Graylog2 enables you to perform quick searches on vast amounts of data, correlate events from multiple sources and create your dashboards on the data.
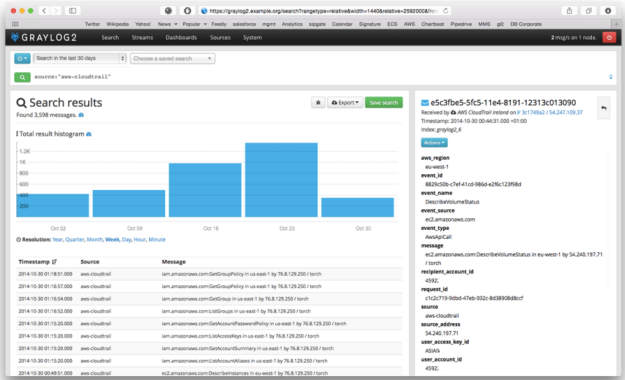
To learn more, visit their site or watch their one minute video.
— Jeff;
CloudWatch Update – Enhanced Support for Windows Log Files
Earlier this year, we launched a log storage and monitoring feature for Amazon CloudWatch. As a quick recap, this feature allows you to upload log files from your Amazon Elastic Compute Cloud (EC2) instances to CloudWatch, where they are stored durably and easily monitored for specific symbols or messages.
The EC2Config service runs on Microsoft Windows instances on EC2, and takes on a number of important tasks. For example it is responsible for uploading log files to CloudWatch. Today we are enhancing this service with support for Windows Performance Counter data and ETW (Event Tracing for Windows) logs. We are also adding support for custom log files.
In order to use this feature, you must enable CloudWatch logs integration and then tell it which files to upload. You can do this from the instance by running EC2Config and checking Enable CloudWatch Logs integration:
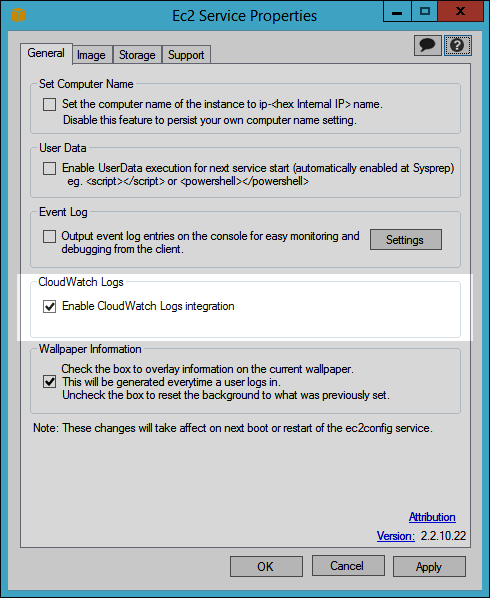
The file %PROGRAMFILES%\Amazon\Ec2ConfigService\Settings\AWS.EC2.Windows.CloudWatch.json specifies the files to be uploaded.
To learn more about how this feature works and how to configure it, head on over to the AWS DevOps Blog and read about Using CloudWatch Logs with Amazon EC2 Running Microsoft Windows Server.
— Jeff;
Store and Monitor OS & Application Log Files with Amazon CloudWatch
When you move from a static operating environment to a dynamically scaled, cloud-powered environment, you need to take a fresh look at your model for capturing, storing, and analyzing the log files produced by your operating system and your applications. Because instances come and go, storing them locally for the long term is simply not appropriate. When running at scale, simply finding storage space for new log files and managing expiration of older ones can become a chore. Further, there’s often actionable information buried within those files. Failures, even if they are one in a million or one in a billion, represent opportunities to increase the reliability of your system and to improve the customer experience.
Today we are introducing a powerful new log storage and monitoring feature for Amazon CloudWatch. You can now route your operating system, application, and custom log files to CloudWatch, where they will be stored in durable fashion for as long as you’d like. You can also configure CloudWatch to monitor the incoming log entries for any desired symbols or messages and to surface the results as CloudWatch metrics. You could, for example, monitor your web server’s log files for 404 errors to detect bad inbound links or 503 errors to detect a possible overload condition. You could monitor your Linux server log files to detect resource depletion issues such as a lack of swap space or file descriptors. You can even use the metrics to raise alarms or to initiate Auto Scaling activities.
Vocabulary Lesson
Before we dig any deeper, let’s agree on some basic terminology! Here are some new terms that you will need to understand in order to use CloudWatch to store and monitor your logs:
 Log Event – A Log Event is an activity recorded by the application or resource being monitored. It contains a timestamp and raw message data in UTF-8 form.
Log Event – A Log Event is an activity recorded by the application or resource being monitored. It contains a timestamp and raw message data in UTF-8 form.- Log Stream – A Log Stream is a sequence of Log Events from the same source (a particular application instance or resource).
- Log Group – A Log Group is a group of Log Streams that share the same properties, policies, and access controls.
- Metric Filters – The Metric Filters tell CloudWatch how to extract metric observations from ingested events and turn them in to CloudWatch metrics.
- Retention Policies – The Retention Policies determine how long events are retained. Policies are assigned to Log Groups and apply to all of the Log Streams in the group.
- Log Agent – You can install CloudWatch Log Agents on your EC2 instances and direct them to store Log Events in CloudWatch. The Agent has been tested on the Amazon Linux AMIs and the Ubuntu AMIs. If you are running Microsoft Windows, you can configure the ec2config service on your instance to send systems logs to CloudWatch. To learn more about this option, read the documentation on Configuring a Windows Instance Using the EC2Config Service.
Getting Started With CloudWatch Logs
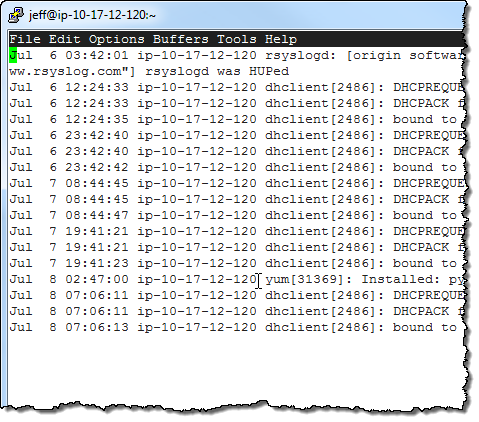
In order to learn more about CloudWatch Logs, I installed the CloudWatch Log Agent on the EC2 instance that I am using to write this blog post! I started by downloading the install script:
$ wget https://s3.amazonaws.com/aws-cloudwatch/downloads/awslogs-agent-setup-v1.0.py
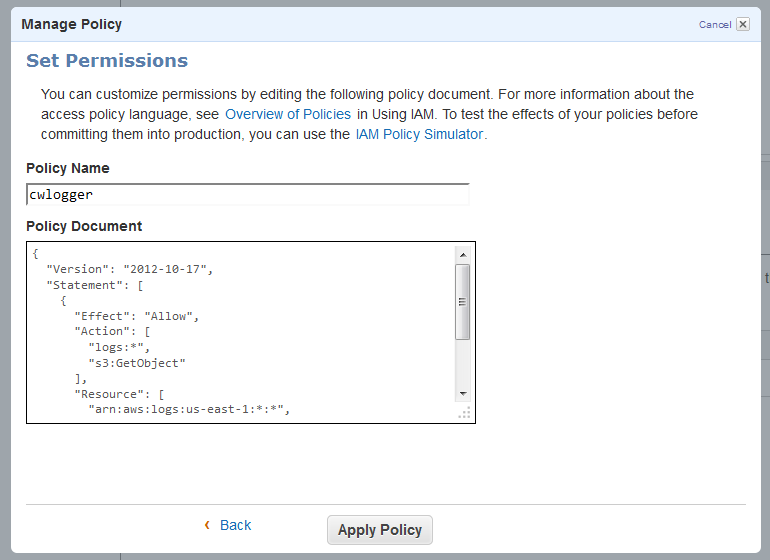
Then I created an IAM user using the policy document provided in the documentation and saved the credentials:
I ran the installation script. The script downloaded, installed, and configured the AWS CLI for me (including a prompt for AWS credentials for my IAM user), and then walked me through the process of configuring the Log Agent to capture Log Events from the /var/log/messages and /var/log/secure files on the instance:
Path of log file to upload [/var/log/messages]:
Destination Log Group name [/var/log/messages]:
Choose Log Stream name:
1. Use EC2 instance id.
2. Use hostname.
3. Custom.
Enter choice [1]:
Choose Log Event timestamp format:
1. %b %d %H:%M:%S (Dec 31 23:59:59)
2. %d/%b/%Y:%H:%M:%S (10/Oct/2000:13:55:36)
3. %Y-%m-%d %H:%M:%S (2008-09-08 11:52:54)
4. Custom
Enter choice [1]: 1
Choose initial position of upload:
1. From start of file.
2. From end of file.
Enter choice [1]: 1
The Log Groups were visible in the AWS Management Console a few minutes later:
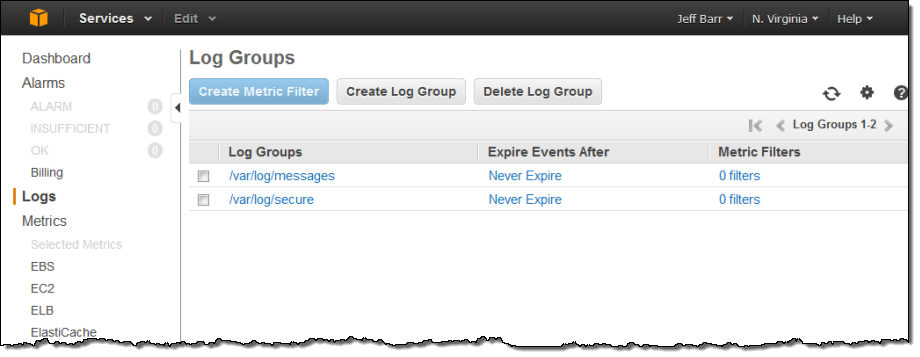
Since I installed the Log Agent on a single EC2 instance, each Log Group contained a single Log Stream. As I specified when I installed the Log Agent, the instance id was used to name the stream:
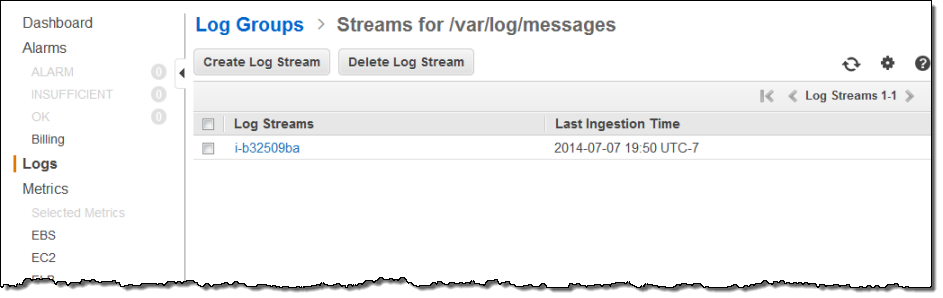
The Log Stream for /var/log/secure was visible with another click:
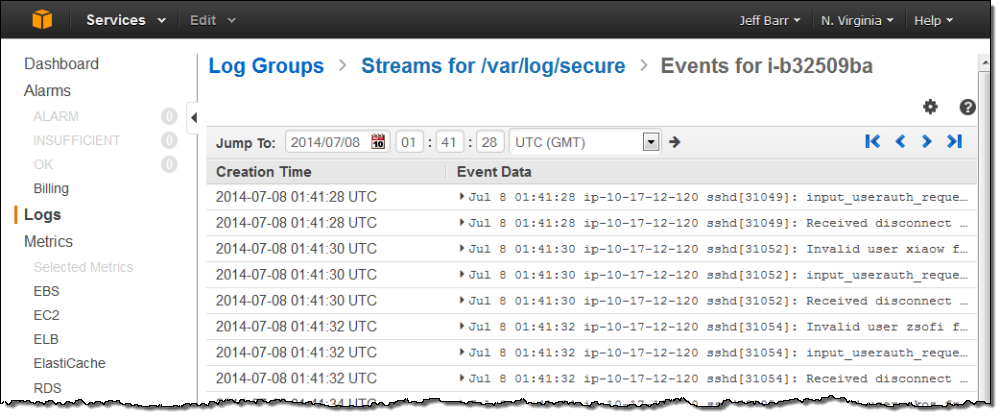
I decided to track the “Invalid user” messages so that I could see how often spurious login attempts were made on my instance. I returned to the list of Log Groups, selected the stream, and clicked on Create Metric Filter. Then I created a filter that would look for the string “Invalid user” (the patterns are case-sensitive):
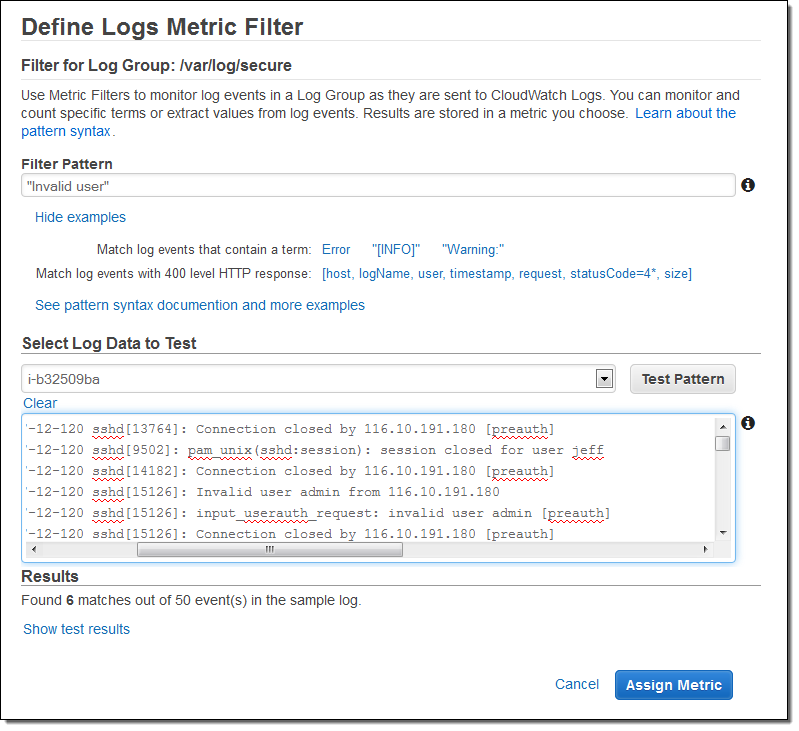
As you can see, the console allowed me to test potential filter patterns against actual log data. When I inspected the results, I realized that a single login attempt would generate several entries in the log file. I was fine with this, and stepped ahead, named the filter and mapped it to a CloudWatch namespace and metric:
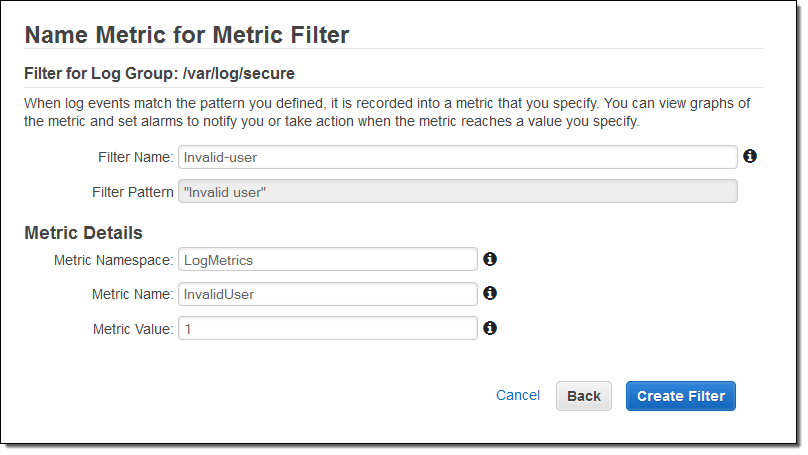
I also created an alarm to send me an email heads-up if the number of invalid login attempts grows to a suspiciously high level:
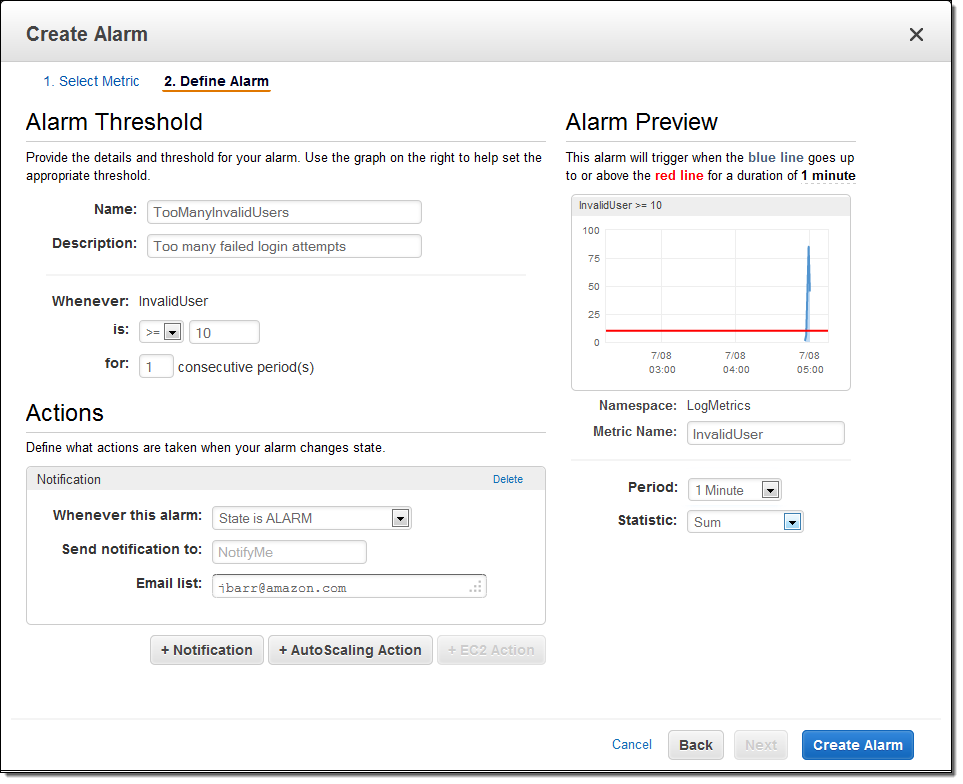
With the logging and the alarm in place, I fired off a volley of spurious login attempts from another EC2 instance and waited for the alarm to fire, as expected:

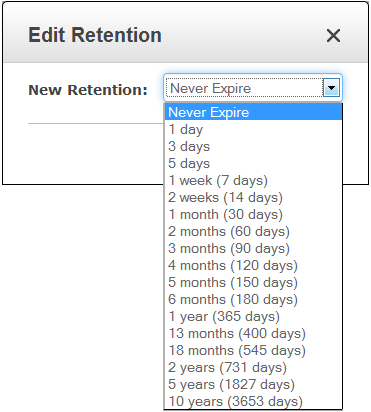
I also have control over the retention period for each Log Group. As you can see, logs can be retained forever (see my notes on Pricing and Availability to learn more about the cost associated with doing this):
Elastic Beanstalk and CloudWatch Logs
You can also generate CloudWatch Logs from your Elastic Beanstalk applications. To get you going with a running start, we have created a sample configuration file that you can copy to the .ebextensions directory at the root of your application. You can find the files at the following locations:
- Tomcat (Java) Configuration Files
- Apache (PHP and Python) Configuration Files
- Nginx (Ruby, Node.js, and Docker) Configuration Files
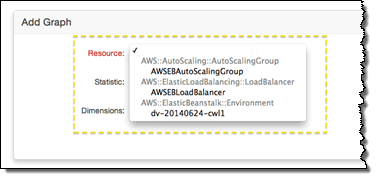
Place CWLogsApache-us-east-1.zip in the folder, then build and deploy your application as normal. Click on the Monitoring tab in the Elastic Beanstalk Console, and then press the Edit button to locate the new resource and select it for monitoring and graphing:
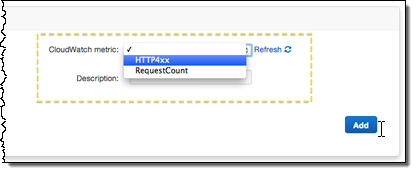
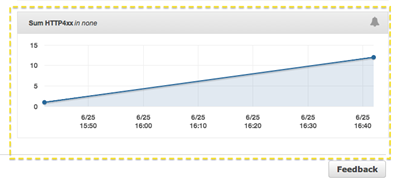
Add the desired statistic, and Elastic Beanstalk will display the graph:
To learn more, read about Using AWS Elastic Beanstalk with Amazon CloudWatch Logs.
Other Logging Options
You can push log data to CloudWatch from AWS OpsWorks, or through the CloudWatch APIs. You can also configure and use logs using AWS CloudFormation.
In a new post on the AWS Application Management Blog, Using Amazon CloudWatch Logs with AWS OpsWorks, my colleague Chris Barclay shows you how to use Chef recipes to create a scalable, centralized logging solution with nothing more than a couple of simple recipes.
To learn more about configuring and using CloudWatch Logs and Metrics Filters through CloudFormation, take a look at the Amazon CloudWatch Logs Sample. Here’s an excerpt from the template:
"404MetricFilter": {
"Type": "AWS::Logs::MetricFilter",
"Properties": {
"LogGroupName": {
"Ref": "WebServerLogGroup"
},
"FilterPattern": "[ip, identity, user_id, timestamp, request, status_code = 404, size, ...]",
"MetricTransformations": [
{
"MetricValue": "1",
"MetricNamespace": "test/404s",
"MetricName": "test404Count"
}
]
}
}
Your code can push a single Log Event to a Long Stream using the putLogEvents function. Here’s a PHP snippet to get you started:
$result = $client->putLogEvents(array(
'logGroupName' => 'AppLog,
'logStreamName' => 'ThisInstance',
'logEvents' => array(
array(
'timestamp' => round(microtime(true) * 1000),
'message' => 'Click!',
)
),
'sequenceToken' => 'string',
));
Pricing and Availability
This new feature is available now in US East (Northern Virginia) Region and you can start using it today.
Pricing is based on the volume of Log Entries that you store and how long you choose to retain them. For more information, please take a look at the CloudWatch Pricing page. Log Events are stored in compressed fashion to reduce storage charges; there is 26 bytes of storage overhead per Log Event.
— Jeff;
New CloudWatch Metrics for Amazon Simple Workflow
The Amazon Simple Workflow Service (SWF for short) coordinates tasks and manages state for cloud-based applications. You can focus on your business logic and on your application instead of building complex glue code and implementing your own state machines. Among many other use cases, our customers are using SWF to manage complex video encoding pipelines, migrate applications and business processes from on-premises data centers to the cloud, and to manage applications that combine automated processing and human-powered data validation.
Today we are launching an important addition to SWF. It now collects and publishes a wide variety of workflow and activity metrics to Amazon CloudWatch. You can use these metrics to monitor progress, raise alarms if activities are not completed at the expected rate, or to drive Auto Scaling activities to adapt to an environment where the number of workflows and activities varies over time.
Times and Counts, Activities and Workflows
Some of the new metrics report on time intervals. For example, the DecisionTaskStartToCloseTime metric tells you how long a decision task took to complete after it began executing. Other metrics report on counts. As you might guess, the WorkflowsCompleted metric reports on the number of workflows that completed.
If you are hosting your worker tasks on an auto scaling group of EC2 instances, you can use the StartToCloseTime and ScheduleToCloseTime metrics to initiate scale-up and scale-down operations.
Metrics are published for SWF workflows and activities. The Workflow metrics report on both times and counts, as do the activity metrics.
You can view the metrics in the CloudWatch section of the AWS Management Console. Here are some sample workflow metrics:
And here are some sample activity metrics:
Learn More
You can learn more about these new metrics in the newest version of the Amazon SWF Developer Guide:
— Jeff;
