AWS Big Data Blog
Category: Amazon EMR
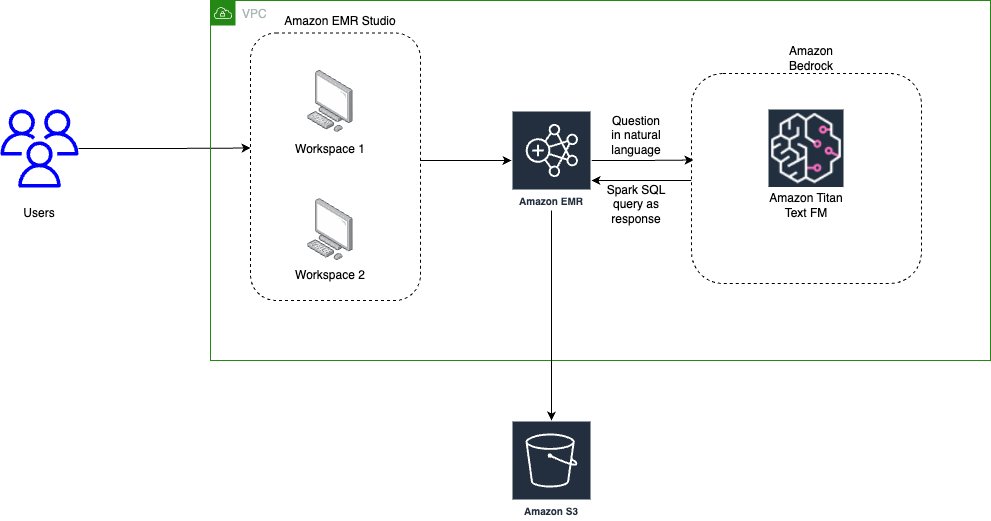
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]
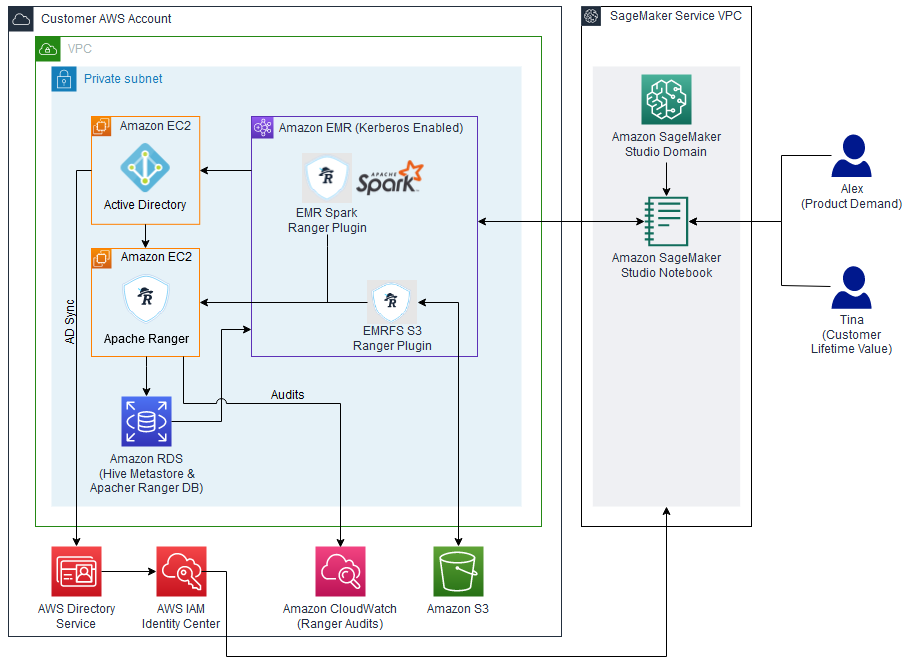
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools such as Spark UI and YARN Timeline Server via […]

GoDaddy benchmarking results in up to 24% better price-performance for their Spark workloads with AWS Graviton2 on Amazon EMR Serverless
This is a guest post co-written with Mukul Sharma, Software Development Engineer, and Ozcan IIikhan, Director of Engineering from GoDaddy. GoDaddy empowers everyday entrepreneurs by providing all the help and tools to succeed online. With more than 20 million customers worldwide, GoDaddy is the place people come to name their ideas, build a professional website, […]

Run Apache Hive workloads using Spark SQL with Amazon EMR on EKS
Apache Hive is a distributed, fault-tolerant data warehouse system that enables analytics at a massive scale. Using Spark SQL to run Hive workloads provides not only the simplicity of SQL-like queries but also taps into the exceptional speed and performance provided by Spark. Spark SQL is an Apache Spark module for structured data processing. One […]

Define per-team resource limits for big data workloads using Amazon EMR Serverless
Customers face a challenge when distributing cloud resources between different teams running workloads such as development, testing, or production. The resource distribution challenge also occurs when you have different line-of-business users. The objective is not only to ensure sufficient resources be consistently available to production workloads and critical teams, but also to prevent adhoc jobs […]

Query big data with resilience using Trino in Amazon EMR with Amazon EC2 Spot Instances for less cost
New enhancements in Trino with Amazon EMR provide improved resiliency for running ETL and batch workloads on Spot Instances with reduced costs. This post showcases the resilience of Amazon EMR with Trino using fault-tolerant configuration to run long-running queries on Spot Instances to save costs. We simulate Spot interruptions on Trino worker nodes by using AWS Fault Injection Simulator (AWS FIS).

Apache Iceberg optimization: Solving the small files problem in Amazon EMR
Currently, Iceberg provides a compaction utility that compacts small files at a table or partition level. But this approach requires you to implement the compaction job using your preferred job scheduler or manually triggering the compaction job. In this post, we discuss the new Iceberg feature that you can use to automatically compact small files while writing data into Iceberg tables using Spark on Amazon EMR or Amazon Athena.

Capacity Management and Amazon EMR Managed Scaling improvements for Amazon EMR on EC2 clusters
In 2022, we told you about the new enhancements we made in Amazon EMR Managed Scaling, which helped improve cluster utilization as well as reduced cluster costs. In 2023, we are happy to report that the Amazon EMR team has been hard at work. We worked backward from customer requirements and launched multiple new features to enhance your Amazon EMR on EC2 clusters capacity management and scaling experience. Let’s dive deeper and discuss the new Amazon EMR on EC2 features in detail.

Monitor Apache Spark applications on Amazon EMR with Amazon Cloudwatch
To improve a Spark application’s efficiency, it’s essential to monitor its performance and behavior. In this post, we demonstrate how to publish detailed Spark metrics from Amazon EMR to Amazon CloudWatch. This will give you the ability to identify bottlenecks while optimizing resource utilization.