AWS Big Data Blog
Category: Amazon Redshift

Amazon Redshift Serverless at 4 RPUs: High-value analytics at low cost
Amazon Redshift Serverless now supports 4 RPU configurations, helping you get started with a lower base capacity that runs scalable analytics workloads beginning at $1.50 per hour. In this post, we examine how this new sizing option makes Redshift Serverless accessible to smaller organizations while providing enterprises with cost-effective environments for development, testing, and variable workloads.

Build data pipelines with dbt in Amazon Redshift using Amazon MWAA and Cosmos
In this post, we explore a streamlined, configuration-driven approach to orchestrate dbt Core jobs using Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Cosmos, an open source package. These jobs run transformations on Amazon Redshift. With this setup, teams can collaborate effectively while maintaining data quality, operational efficiency, and observability.

Near real-time streaming analytics on protobuf with Amazon Redshift
In this post, we explore an end-to-end analytics workload for streaming protobuf data, by showcasing how to handle these data streams with Amazon Redshift Streaming Ingestion, deserializing and processing them using AWS Lambda functions, so that the incoming streams are immediately available for querying and analytical processing on Amazon Redshift.

Amazon Redshift out-of-the-box performance innovations for data lake queries
In this post, we first briefly review how planner statistics are collected and what impact they have on queries. Then, we discuss Amazon Redshift features that deliver optimal plans on Iceberg tables and Parquet data even with the lack of statistics. Finally, we review some example queries that now execute faster because of these latest Amazon Redshift innovations.

Secure generative SQL with Amazon Q
In this post, we discuss the design and security controls in place when using generative SQL and its use in both Amazon SageMaker Unified Studio and Amazon Redshift Query Editor v2.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.

Harnessing the Power of Nested Materialized Views and exploring Cascading Refresh
In this post, we explore how to maximize Amazon Redshift query performance through nested materialized views and implementing cascading refresh strategies. We demonstrate how to create materialized views based on other materialized views, enabling a hierarchical structure of precomputed results that significantly enhances query performance and data processing efficiency, particularly useful for reusing precomputed joins with different aggregate options.
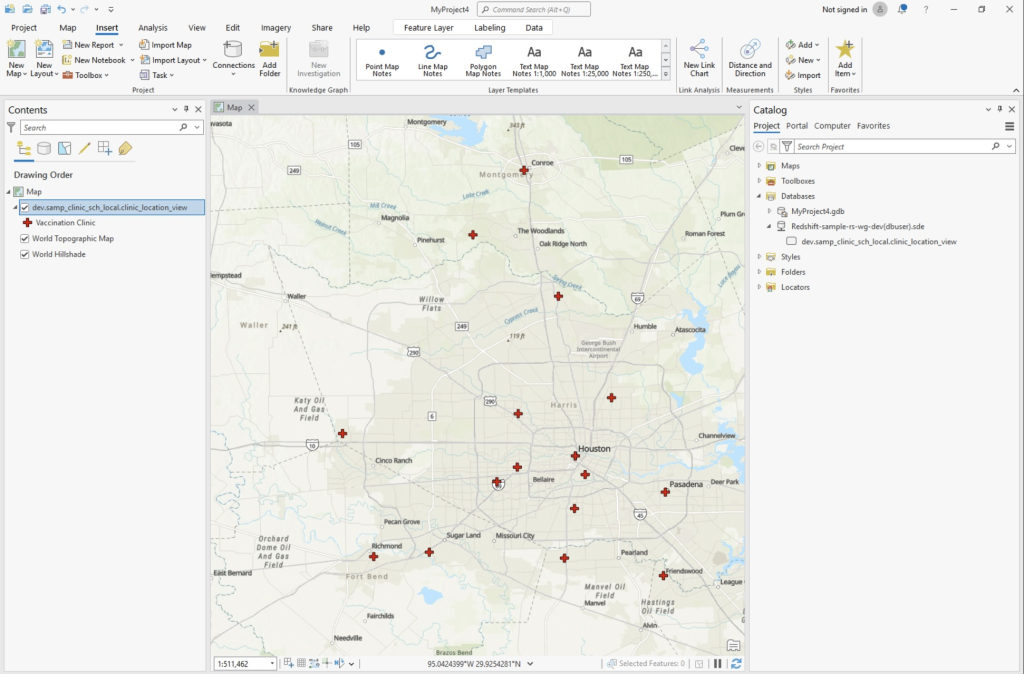
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

Amazon Redshift Python user-defined functions will reach end of support after June 30, 2026
The Amazon Redshift integration with AWS Lambda provides the capability to create Amazon Redshift Lambda user-defined functions (UDFs). Because Lambda UDFs provide these significant advantages in integration, flexibility, scalability, and security, we will be ending support for Python UDFs in Amazon Redshift. In this post, we walk you through how to migrate your existing Python UDFs to Lambda UDFs, set up monitoring and cost evaluations, and review key considerations for a smooth transition.

Enhance data ingestion performance in Amazon Redshift with concurrent inserts
Amazon Redshift employs columnar storage for database tables, reducing overall disk I/O requirements. This storage method significantly improves analytic query performance by minimizing data read during queries. This post showcases the key improvements in Amazon Redshift concurrent data ingestion operations.