AWS Big Data Blog
Category: Amazon Redshift

Harnessing the Power of Nested Materialized Views and exploring Cascading Refresh
In this post, we explore how to maximize Amazon Redshift query performance through nested materialized views and implementing cascading refresh strategies. We demonstrate how to create materialized views based on other materialized views, enabling a hierarchical structure of precomputed results that significantly enhances query performance and data processing efficiency, particularly useful for reusing precomputed joins with different aggregate options.
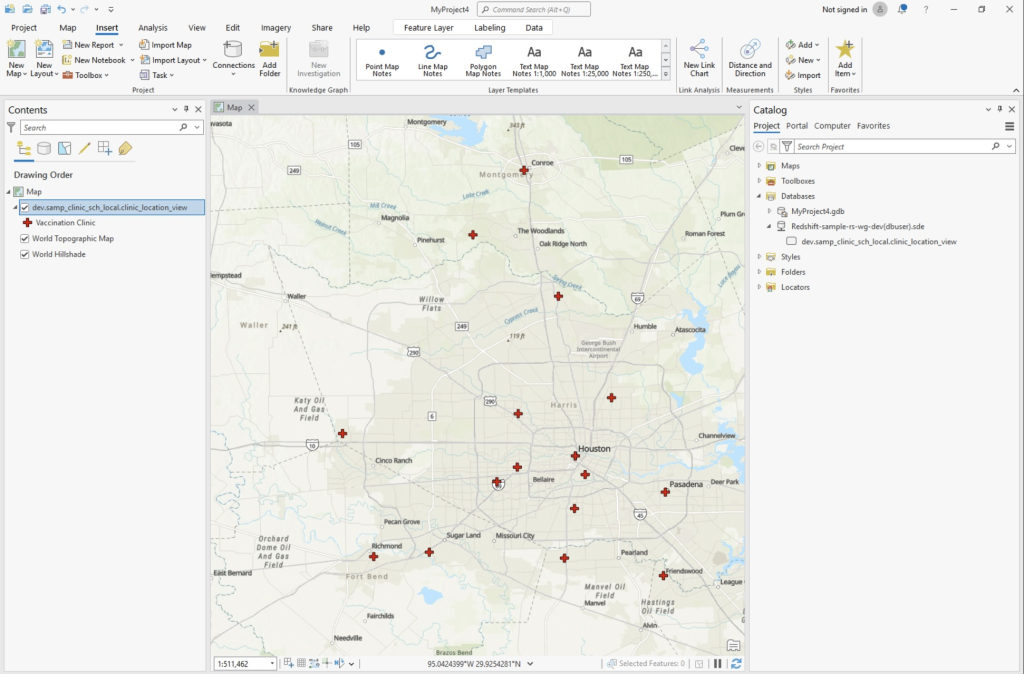
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

Amazon Redshift Python user-defined functions will reach end of support after June 30, 2026
The Amazon Redshift integration with AWS Lambda provides the capability to create Amazon Redshift Lambda user-defined functions (UDFs). Because Lambda UDFs provide these significant advantages in integration, flexibility, scalability, and security, we will be ending support for Python UDFs in Amazon Redshift. In this post, we walk you through how to migrate your existing Python UDFs to Lambda UDFs, set up monitoring and cost evaluations, and review key considerations for a smooth transition.

Enhance data ingestion performance in Amazon Redshift with concurrent inserts
Amazon Redshift employs columnar storage for database tables, reducing overall disk I/O requirements. This storage method significantly improves analytic query performance by minimizing data read during queries. This post showcases the key improvements in Amazon Redshift concurrent data ingestion operations.

How Skroutz handles real-time schema evolution in Amazon Redshift with Debezium
Skroutz chose Amazon Redshift to promote data democratization, empowering teams across the organization with seamless access to data, enabling faster insights and more informed decision-making. In this post, we share how we handled real-time schema evolution in Amazon Redshift with Debezium.

Build a multi-Region analytics solution with Amazon Redshift, Amazon S3, and Amazon QuickSight
This post explores how to effectively architect a solution that addresses this specific challenge: enabling comprehensive analytics capabilities for global teams while making sure that your data remains in the AWS Regions required by your compliance framework. We use a variety of AWS services, including Amazon Redshift, Amazon Simple Storage Service (Amazon S3), and Amazon QuickSight.

Reduce time to access your transactional data for analytical processing using the power of Amazon SageMaker Lakehouse and zero-ETL
In this post, we demonstrate how you can bring transactional data from AWS OLTP data stores like Amazon Relational Database Service (Amazon RDS) and Amazon Aurora flowing into Redshift using zero-ETL integrations to SageMaker Lakehouse Federated Catalog (Bring your own Amazon Redshift into SageMaker Lakehouse). With this integration, you can now seamlessly onboard the changed data from OLTP systems to a unified lakehouse and expose the same to analytical applications for consumptions using Apache Iceberg APIs from new SageMaker Unified Studio.

Architecture patterns to optimize Amazon Redshift performance at scale
In this post, we will show you five Amazon Redshift architecture patterns that you can consider to optimize your Amazon Redshift data warehouse performance at scale using features such as Amazon Redshift Serverless, Amazon Redshift data sharing, Amazon Redshift Spectrum, zero-ETL integrations, and Amazon Redshift streaming ingestion.

Powering global payout intelligence: How MassPay uses Amazon Redshift Serverless and zero-ETL to drive deeper analytics.
In this blog post we shall cover how understanding real-time payout performance, identifying customer behavior patterns across regions, and optimizing internal operations required more than traditional business intelligence and analytics tools. And how since implementing Amazon Redshift and Zero-ETL, MassPay has seen 90% reduction in data availability latency, payments data available for analytics 1.5x faster, leading to 45% reduction in time-to-insight and 37% fewer support tickets related to transaction visibility and payment inquiries.

Scalable analytics and centralized governance for Apache Iceberg tables using Amazon S3 Tables and Amazon Redshift
In this post, we’ll build on the first post in this series to show you how to set up an Apache Iceberg data lake catalog using Amazon S3 Tables and provide different levels of access control to your data. Through this example, you’ll set up fine-grained access controls for multiple users and see how this works using Amazon Redshift. We’ll also review an example with simultaneously using data that resides both in Amazon Redshift and Amazon S3 Tables, enabling a unified analytics experience.