AWS Big Data Blog
Category: Analytics
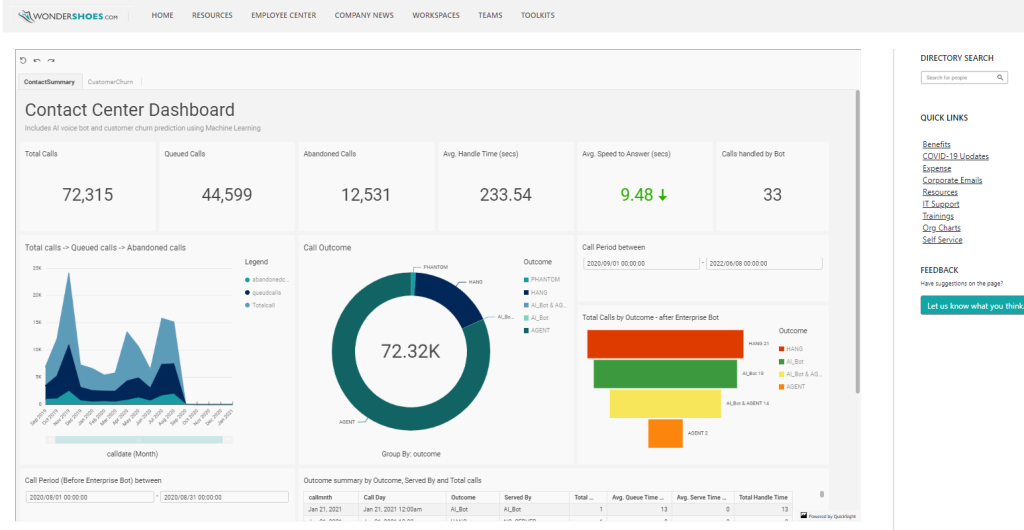
Top Amazon QuickSight features launched in Q2 2022
Amazon QuickSight is a serverless, cloud-based business intelligence (BI) service that brings data insights to your teams and end-users through machine learning (ML)-powered dashboards and data visualizations, which can be accessed via QuickSight or embedded in apps and portals that your users access. This post shares the top QuickSight features and updates launched in Q2 […]

Set up and monitor AWS Glue crawlers using the enhanced AWS Glue UI and crawler history
A data lake is a centralized, curated, and secured repository that stores all your data, both in its original form and prepared for analysis. Setting up and managing data lakes today involves a lot of manual, complicated, and time-consuming tasks. AWS Glue and AWS Lake Formation make it easy to build, secure, and manage data […]

Visualize Amazon S3 data using Amazon Athena and Amazon Managed Grafana
Grafana is a popular open-source analytics platform that you can employ to create, explore, and share your data through flexible dashboards. Its use cases include application and IoT device monitoring, and visualization of operational and business data, among others. You can create your dashboard with your own datasets or publicly available datasets related to your […]

New Powered by QuickSight program helps AWS partners embed interactive analytics in applications to enable data-driven experiences
Applications today generate enormous amounts of data. This provides an incredible opportunity for independent software vendors (ISVs) to deliver business intelligence (BI) offerings as a part of their application, providing visuals, dashboards, and self-service capabilities to customers. These insights are crucial for data-driven decision-making for end-users of these apps, especially if surfaced in the moments […]

How Fresenius Medical Care aims to save dialysis patient lives using real-time predictive analytics on AWS
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. This post is co-written by Kanti Singh, Director of Data & Analytics at Fresenius Medical Care. Fresenius Medical Care is the world’s leading provider of kidney care […]

Removing complexity to improve business performance: How Bridgewater Associates built a scalable, secure, Spark-based research service on AWS
This is a guest post co-written by Sergei Dubinin, Oleksandr Ierenkov, Illia Popov and Joel Thompson, from Bridgewater. Bridgewater’s core mission is to understand how the world works by analyzing the drivers of markets and turning that understanding into high-quality portfolios and investment advice for our clients. Within Bridgewater Technology, we strive to make our […]

Reduce network traffic costs of your Amazon MSK consumers with rack awareness
May 2025: This post was reviewed and the CloudFormation template was updated for accuracy Amazon Managed Streaming for Apache Kafka (Amazon MSK) runs Apache Kafka clusters for you in the cloud. Although using cloud services means you don’t have to manage racks of servers any more, we take advantage of rack aware features in Apache […]

How Fannie Mae built a data mesh architecture to enable self-service using Amazon Redshift data sharing
This post is co-written by Kiran Ramineni and Basava Hubli, from Fannie Mae. Amazon Redshift data sharing enables instant, granular, and fast data access across Amazon Redshift clusters without the need to copy or move data around. Data sharing provides live access to data so that users always see the most up-to-date and transactionally consistent […]

Set up federated access to Amazon Athena for Microsoft AD FS users using AWS Lake Formation and a JDBC client
Tens of thousands of AWS customers choose Amazon Simple Storage Service (Amazon S3) as their data lake to run big data analytics, interactive queries, high-performance computing, and artificial intelligence (AI) and machine learning (ML) applications to gain business insights from their data. On top of these data lakes, you can use AWS Lake Formation to […]

Amazon Redshift data sharing best practices and considerations
Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. Amazon Redshift data sharing allows for a secure and easy way to share live data for reading across Amazon Redshift clusters. It allows an […]