AWS Big Data Blog
Category: Analytics
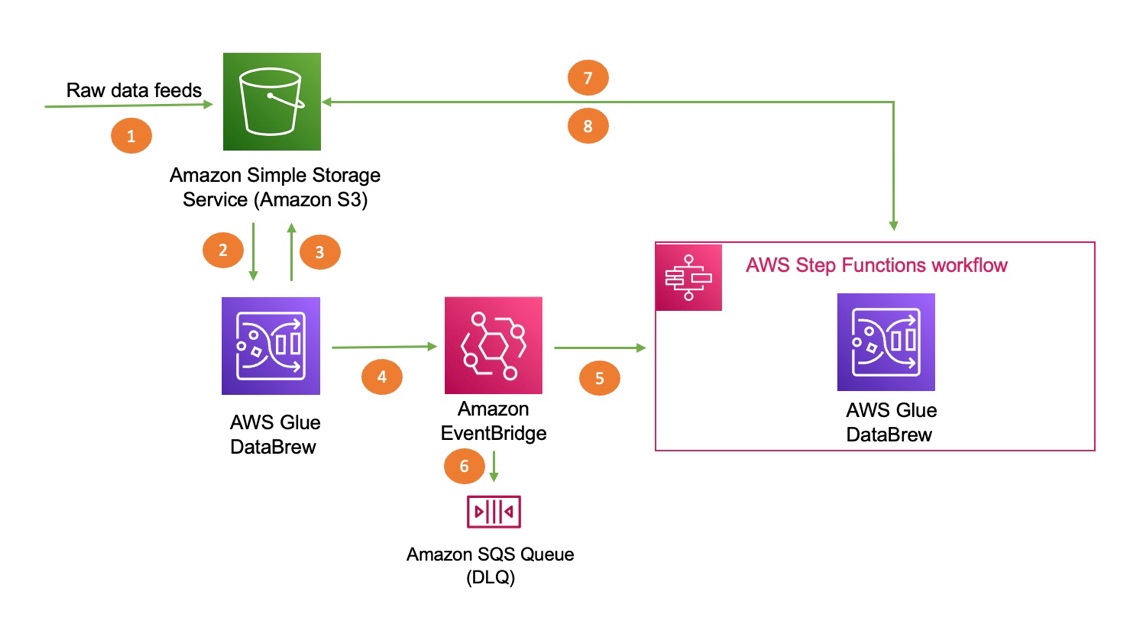
Trigger an AWS Glue DataBrew job based on an event generated from another DataBrew job
Organizations today have continuous incoming data, and analyzing this data in a timely fashion is becoming a common requirement for data analytics and machine learning (ML) use cases. As part of this, you need clean data in order to gain insights that can enable enterprises to get the most out of their data for business […]

Integrate AWS Glue Schema Registry with the AWS Glue Data Catalog to enable effective schema enforcement in streaming analytics use cases
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. Metadata is an integral part of data management and governance. The AWS Glue Data Catalog can provide a uniform repository to store and share metadata. The main […]

Supercharging Dream11’s Data Highway with Amazon Redshift RA3 clusters
This is a guest post by Dhanraj Gaikwad, Principal Engineer on Dream11 Data Engineering team. Dream11 is the world’s largest fantasy sports platform, with over 120 million users playing fantasy cricket, football, kabaddi, basketball, hockey, volleyball, handball, rugby, futsal, American football, and baseball. Dream11 is the flagship brand of Dream Sports, India’s leading Sports Technology […]

Visualize MongoDB data from Amazon QuickSight using Amazon Athena Federated Query
In this post, you will learn how to use Amazon Athena Federated Query to connect a MongoDB database to Amazon QuickSight in order to build dashboards and visualizations. Amazon Athena is a serverless interactive query service, based on Presto, that provides full ANSI SQL support to query a variety of standard data formats, including CSV, […]

Synchronize your AWS Glue Studio Visual Jobs to different environments
June 2023: This post was reviewed and updated for accuracy. AWS Glue has become a popular option for integrating data from disparate data sources due to its ability to integrate large volumes of data using distributed data processing frameworks. Many customers use AWS Glue to build data lakes and data warehouses. Data engineers who prefer […]
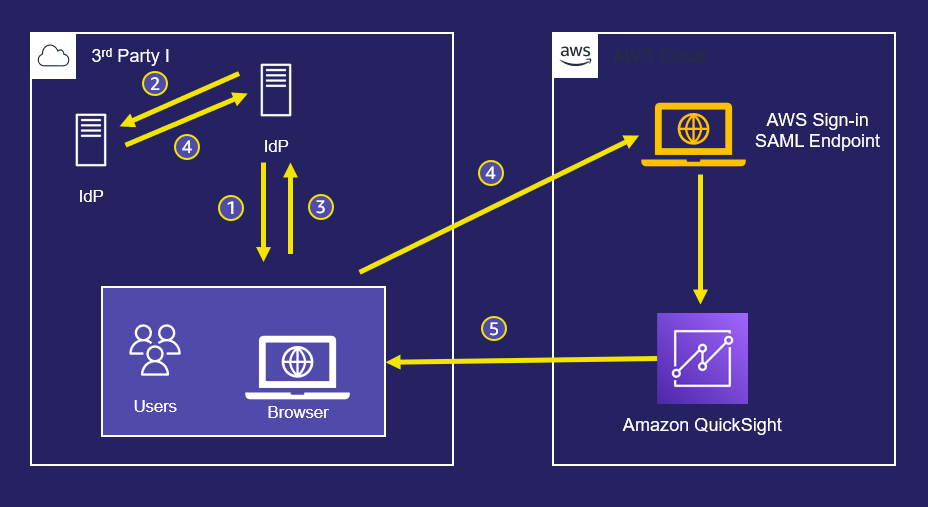
Enable Amazon Quick Sight federation with Google Workspace
October 2025: This post was reviewed for accuracy. Amazon Quick Sight is now an AWS IAM Identity Center enabled application. This capability allows administrators who subscribe to Quick Sight to use IAM Identity Center to enable their users to log in with Google Workspace and other external identity providers. For more information, see Simplify business intelligence […]

Tips and tricks for high-performant dashboards in Amazon QuickSight
August 2025: This post was reviewed and updated for accuracy. Amazon QuickSight is cloud-native business intelligence (BI) service. QuickSight automatically optimizes queries and execution to help dashboards load quickly, but you can make your dashboard loads even faster and make sure you’re getting the best possible performance by following the tips and tricks outlined in […]

Analyze Amazon Ion datasets using Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. Amazon Ion is a richly typed, self-describing, hierarchical data serialization format […]

Use Amazon Redshift RA3 with managed storage in your modern data architecture
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. This enables you to use your data to acquire new insights for your business and customers. Over the years, Amazon Redshift has evolved a […]
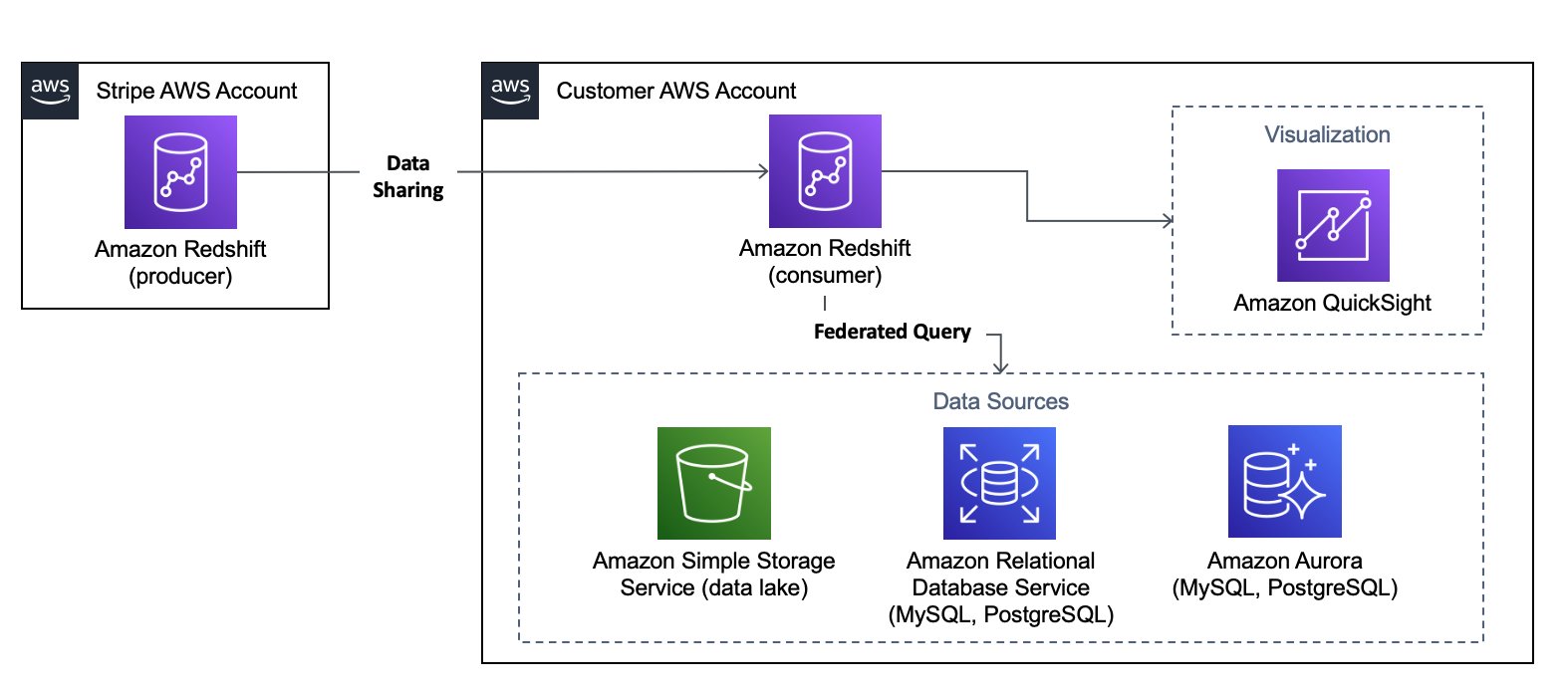
Ingest Stripe data in a fast and reliable way using Stripe Data Pipeline for Amazon Redshift
Enterprises typically host a myriad of business applications for varying data needs. As companies grow, so does the demand for insights from a complete set of business data. Having data from various applications that store data in disparate silos can delay the decision-making process. However, building and maintaining an API integration or a third-party extract, […]