AWS Big Data Blog
Category: Analytics
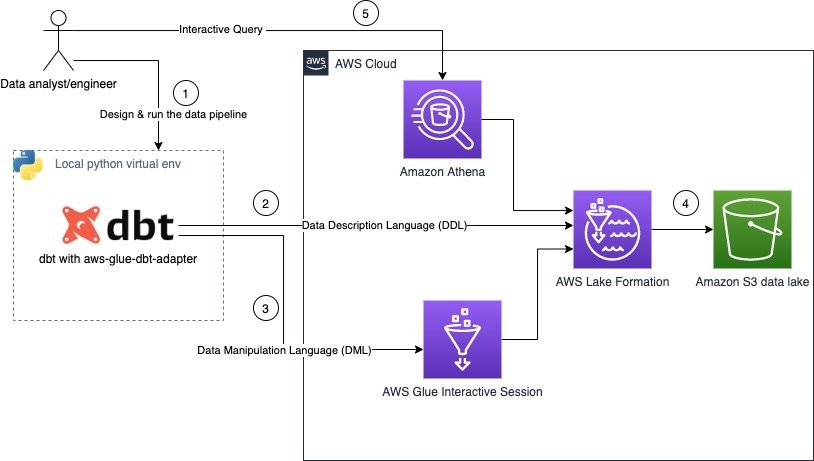
Build your data pipeline in your AWS modern data platform using AWS Lake Formation, AWS Glue, and dbt Core
dbt has established itself as one of the most popular tools in the modern data stack, and is aiming to bring analytics engineering to everyone. The dbt tool makes it easy to develop and implement complex data processing pipelines, with mostly SQL, and it provides developers with a simple interface to create, test, document, evolve, […]

Amazon QuickSight 1-click public embedding
Amazon QuickSight is a fully managed, cloud-native business intelligence (BI) service that makes it easy to connect to your data, create interactive dashboards, and share these with tens of thousands of users, either directly within a QuickSight application, or embedded in web apps and portals. QuickSight Enterprise Edition now supports 1-click public embedding, a feature […]

Introducing AWS Glue Auto Scaling: Automatically resize serverless computing resources for lower cost with optimized Apache Spark
October 2024: This post has been updated along with Interactive Sessions support for AWS Glue Auto scaling. June 2023: This post was reviewed and updated for accuracy. Data created in the cloud is growing fast in recent days, so scalability is a key factor in distributed data processing. Many customers benefit from the scalability of […]

Enhance analytics with Google Trends data using AWS Glue, Amazon Athena, and Amazon QuickSight
In today’s market, business success often lies in the ability to glean accurate insights and predictions from data. However, data scientists and analysts often find that the data they have at their disposal isn’t enough to help them make accurate predictions for their use cases. A variety of factors might alter an outcome and should […]

Scale Amazon Redshift to meet high throughput query requirements
August 2024: This post was reviewed and updated for accuracy. Many enterprise customers have demanding query throughput requirements for their data warehouses. Some may be able to address these requirements through horizontally or vertically scaling a single cluster. Others may have a short duration where they need extra capacity to handle peaks that can be […]

Amazon Redshift continues its price-performance leadership
Data is a strategic asset. Getting timely value from data requires high-performance systems that can deliver performance at scale while keeping costs low. Amazon Redshift is the most popular cloud data warehouse that is used by tens of thousands of customers to analyze exabytes of data every day. We continue to add new capabilities to […]

Automate notifications on Slack for Amazon Redshift query monitoring rule violations
In this post, we walk you through how to set up automatic notifications of query monitoring rule (QMR) violations in Amazon Redshift to a Slack channel, so that Amazon Redshift users can take timely action. Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. With Amazon Redshift, you can analyze your […]

Share data securely across Regions using Amazon Redshift data sharing
July 2023: This post was reviewed for accuracy. Today’s global, data-driven organizations treat data as an asset and use it across different lines of business (LOBs) to drive timely insights and better business decisions. This requires you to seamlessly share and consume live, consistent data as a single source of truth without copying the data, […]

Write prepared data directly into JDBC-supported destinations using AWS Glue DataBrew
July 2023: This post was reviewed for accuracy. AWS Glue DataBrew offers over 250 pre-built transformations to automate data preparation tasks (such as filtering anomalies, standardizing formats, and correcting invalid values) that would otherwise require days or weeks writing hand-coded transformations. You can now write cleaned and normalized data directly into JDBC-supported databases and data […]

Develop and test AWS Glue version 3.0 and 4.0 jobs locally using a Docker container
Mar 2025: This post was written for AWS Glue 3.0 and 4.0. For AWS Glue 5.0, visit Develop and test AWS Glue 5.0 jobs locally using a Docker container. Apr 2023: This post was reviewed and updated with enhanced support for Glue 4.0 Streaming jobs. Jan 2023: This post was reviewed and updated with enhanced […]