AWS Big Data Blog
Category: Analytics

Improved performance with AWS Graviton2 instances on Amazon OpenSearch Service
Amazon OpenSearch Service is a fully managed service at AWS for OpenSearch. It’s an open-source search and analytics suite used for a broad set of use cases, like real-time application monitoring, log analytics, and website search. While running an OpenSearch Service domain, you can choose from a variety of instances for your primary nodes and […]

ETL orchestration using the Amazon Redshift Data API and AWS Step Functions with AWS SDK integration
Extract, transform, and load (ETL) serverless orchestration architecture applications are becoming popular with many customers. These applications offers greater extensibility and simplicity, making it easier to maintain and simplify ETL pipelines. A primary benefit of this architecture is that we simplify an existing ETL pipeline with AWS Step Functions and directly call the Amazon Redshift […]

Announcing the new Amazon QuickSight Community
On February 22, 2022, we launched our new Amazon QuickSight Community. Here you can ask and answer questions, network with and learn from other Business Intelligence (BI) users from across the globe, access learning content, and stay up to date with what’s new on Amazon QuickSight—all in one place! In this post, we discuss some […]

Audit AWS service events with Amazon EventBridge and Amazon Kinesis Data Firehose
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. Amazon EventBridge is a serverless event bus that makes it easy to build event-driven applications at scale using events generated from your applications, integrated software as a service (SaaS) applications, and AWS […]
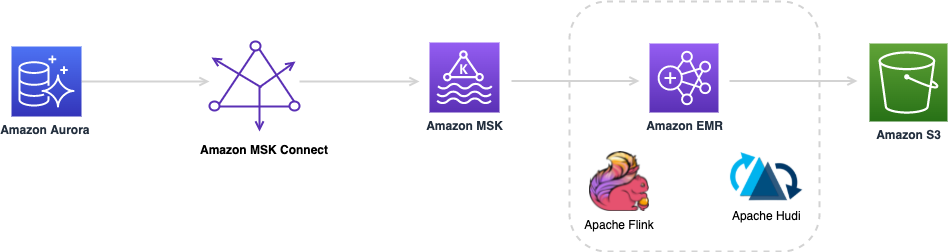
Create a low-latency source-to-data lake pipeline using Amazon MSK Connect, Apache Flink, and Apache Hudi
August 30, 2023: Amazon Kinesis Data Analytics has been renamed to Amazon Managed Service for Apache Flink. Read the announcement in the AWS News Blog and learn more. During the recent years, there has been a shift from monolithic to the microservices architecture. The microservices architecture makes applications easier to scale and quicker to develop, […]
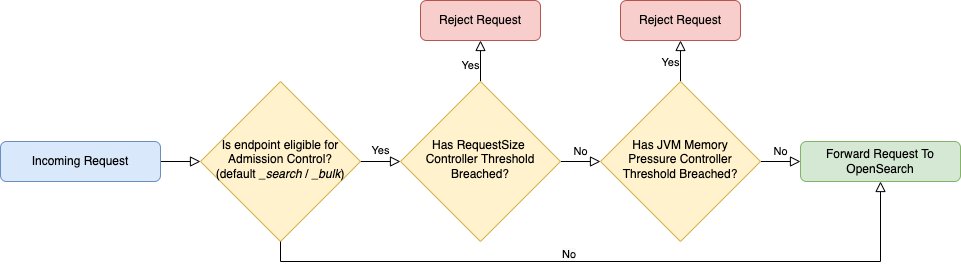
Enhance resiliency with admission control in Amazon OpenSearch Service
OpenSearch is a distributed, open-source search and analytics suite used for a broad set of use cases like real-time application monitoring, log analytics, and website search. Amazon OpenSearch Service is a managed service that makes it easy to secure, deploy, and operate OpenSearch clusters at scale. Amazon OpenSearch Service provides a broad range of cluster […]

How Cynamics built a high-scale, near-real-time, streaming AI inference system using AWS
This post is co-authored by Dr. Yehezkel Aviv, Co-Founder and CTO of Cynamics and Sapir Kraus, Head of Engineering at Cynamics. Cynamics provides a new paradigm of cybersecurity — predicting attacks long before they hit by collecting small network samples (less than 1%), inferring from them how the full network (100%) behaves, and predicting threats […]
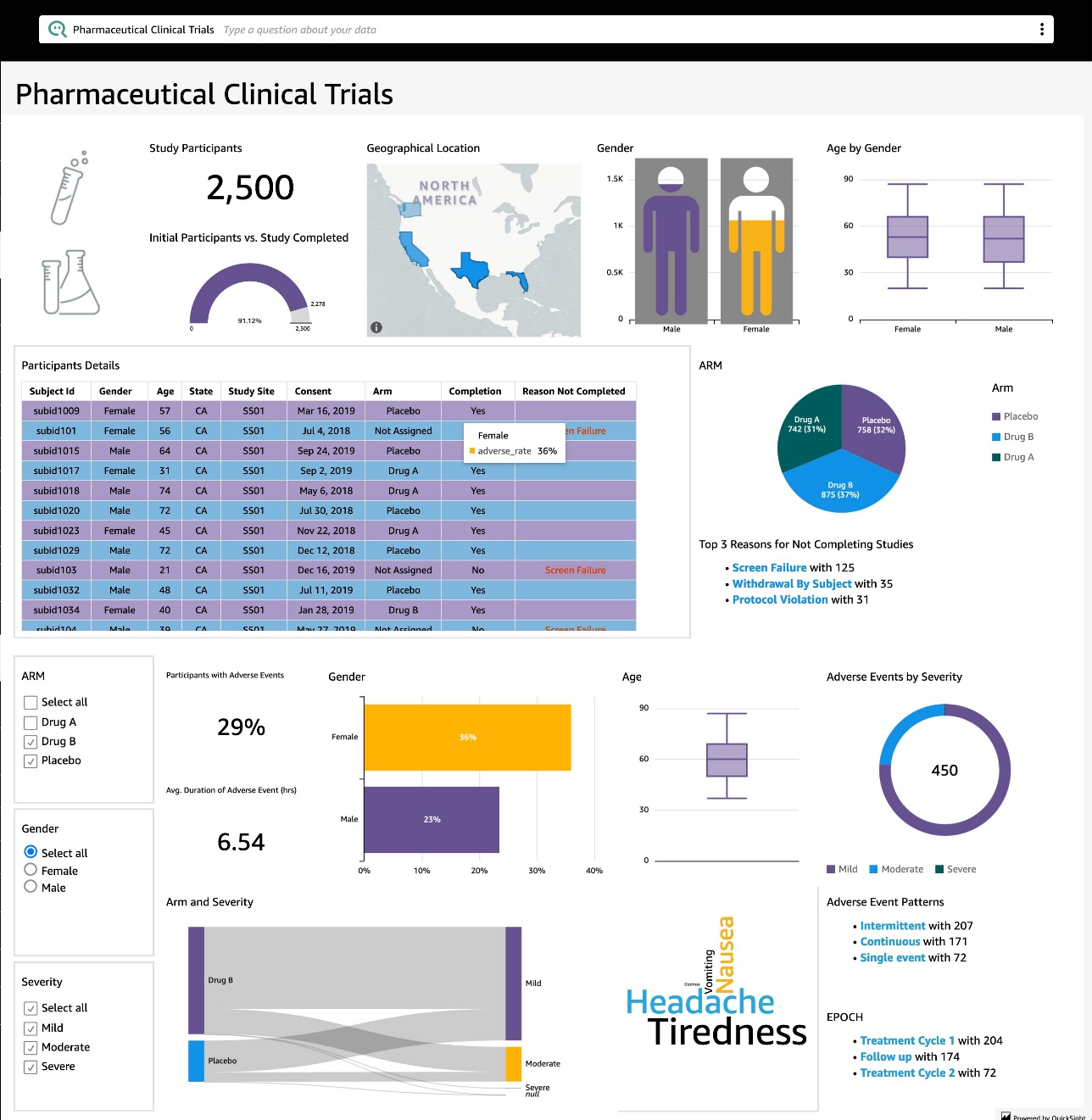
Enable users to ask questions about data using natural language within your applications by embedding Amazon QuickSight Q
Amazon QuickSight Q is a new machine learning-based capability in Amazon QuickSight that enables users to ask business questions in natural language and receive answers with relevant visualizations instantly to gain insights from data. QuickSight Q doesn’t depend on prebuilt dashboards or reports to answer questions, which removes the need for business intelligence (BI) teams […]

Detect anomalies on one million unique entities with Amazon OpenSearch Service
Amazon OpenSearch Service supports a highly performant, integrated anomaly detection engine that enables the real-time identification of anomalies in streaming data. Last year, we released high-cardinality anomaly detection (HCAD) to detect individual entities’ anomalies. With the 1.1 release, we have allowed you to monitor a million entities with steady, predictable performance. HCAD is easiest when […]

Export JSON data to Amazon S3 using Amazon Redshift UNLOAD
Amazon Redshift is a fast, scalable, secure, and fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL. Amazon Redshift offers up to three times better price performance than any other cloud data warehouse. Tens of thousands of customers use Amazon Redshift to process exabytes of […]