AWS Big Data Blog
Category: Analytics

Orchestrate data processing jobs, querybooks, and notebooks using visual workflow experience in Amazon SageMaker
Today, we are excited to launch a new visual workflows builder in SageMaker Unified Studio. With the new visual workflow experience, you don’t need to code the Python DAGs manually. Instead, you can visually define the orchestration workflow in SageMaker Unified Studio, and the visual definition is automatically converted to a Python DAG definition that is supported in Airflow.This post demonstrates the new visual workflow experience in SageMaker Unified Studio.

Revenue NSW modernises analytics with AWS, enabling unified and scalable data management, processing, and access
Revenue NSW, Australia’s principal revenue management agency, successfully modernized its analytics infrastructure using AWS services. In this blog post, we show how the organization transformed its on-premises data environment into a unified, scalable cloud-based solution using Amazon Redshift, AWS Database Migration Service, Amazon AppFlow, and AWS Glue.

Harnessing the Power of Nested Materialized Views and exploring Cascading Refresh
In this post, we explore how to maximize Amazon Redshift query performance through nested materialized views and implementing cascading refresh strategies. We demonstrate how to create materialized views based on other materialized views, enabling a hierarchical structure of precomputed results that significantly enhances query performance and data processing efficiency, particularly useful for reusing precomputed joins with different aggregate options.

Realizing ocean data democratization: Furuno Electric’s initiatives using Amazon DataZone
In this post, we explore how Furuno Electric built a comprehensive data management foundation using Amazon DataZone and other AWS services to transform from a traditional manufacturing company to a data-driven business.
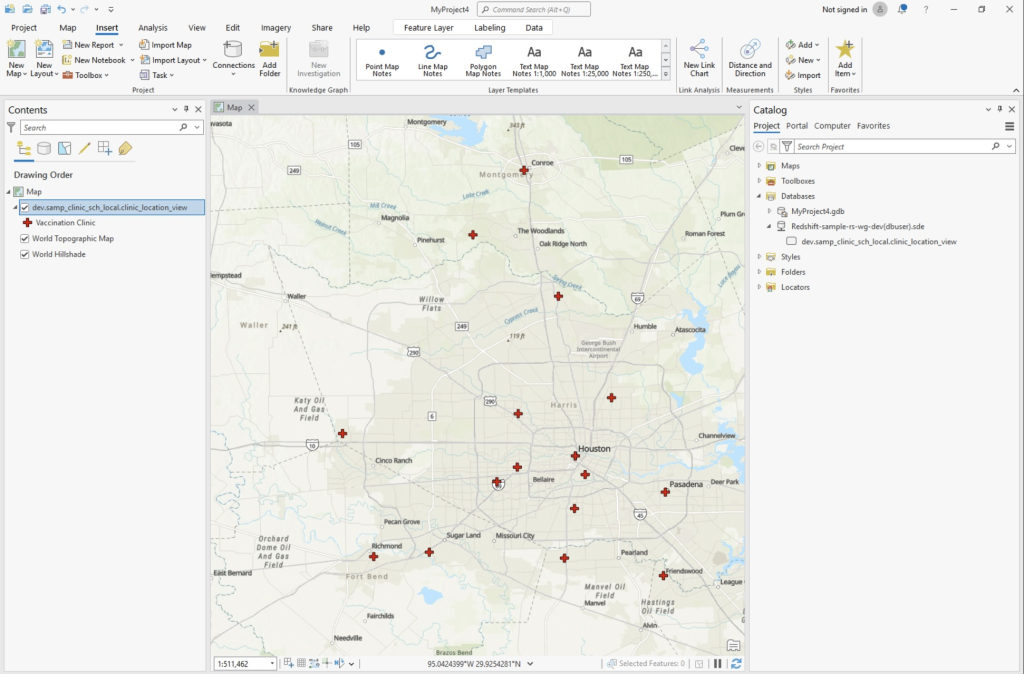
Geospatial data lakes with Amazon Redshift
In this post, we review how to set up Redshift Serverless to use geospatial data contained within a data lake to enhance maps in ArcGIS Pro. This technique helps builders and GIS analysts use available datasets in data lakes and transform it in Amazon Redshift to further enrich the data before presenting it on a map.

Develop and monitor a Spark application using existing data in Amazon S3 with Amazon SageMaker Unified Studio
In this post, we demonstrate how to develop and monitor a Spark application using existing data in Amazon S3 using SageMaker Unified Studio. The solution addresses key challenges organizations face in managing big data analytics workloads through an integrated development environment where data teams can develop, test, and refine Spark applications while leveraging EMR Serverless for dynamic resource allocation and built-in monitoring tools.

Perform per-project cost allocation in Amazon SageMaker Unified Studio
Amazon SageMaker Unified Studio enables per-project cost allocation through resource tagging, allowing organizations to track and manage costs across different projects and domains effectively. This post demonstrates how to implement cost tracking using AWS Billing and Cost Management tools, including Cost Explorer and Data Exports, to help finance and business analysts follow FinOps best practices for controlling cloud infrastructure costs.

Near real-time baggage operational insights for airlines using Amazon Kinesis Data Streams
This post explores a framework developed by IBM to modernize baggage analytics using AWS managed services like Amazon Kinesis Data Streams, DynamoDB Streams, and other AWS services within a serverless architecture. The solution enables near real-time baggage operational insights for airlines, delivering cost savings, enhanced scalability, and improved performance while providing better security and operational efficiency to meet evolving airline needs.

Overcome your Kafka Connect challenges with Amazon Data Firehose
We’re happy to announce a new feature in the Amazon Data Firehose integration with Amazon MSK. You can now specify the Firehose stream to either read from the earliest position on the Kafka topic or from a custom timestamp to begin reading from your MSK topic. In this post of this series, we focus on managed data delivery from Kafka to your data lake.

How Stifel built a modern data platform using AWS Glue and an event-driven domain architecture
In this post, we show you how Stifel implemented a modern data platform using AWS services and open data standards, building an event-driven architecture for domain data products while centralizing the metadata to facilitate discovery and sharing of data products.