AWS Big Data Blog
Category: Artificial Intelligence

Entity resolution and fuzzy matches in AWS Glue using the Zingg open source library
In this post, we explore how to use Zingg’s entity resolution capabilities within an AWS Glue notebook, which you can later run as an extract, transform, and load (ETL) job. By integrating Zingg in your notebooks or ETL jobs, you can effectively address data governance challenges and provide consistent and accurate data across your organization.

AI recommendations for descriptions in Amazon DataZone for enhanced business data cataloging and discovery is now generally available
In March 2024, we announced the general availability of the generative artificial intelligence (AI) generated data descriptions in Amazon DataZone. In this post, we share what we heard from our customers that led us to add the AI-generated data descriptions and discuss specific customer use cases addressed by this capability. We also detail how the […]

Improve healthcare services through patient 360: A zero-ETL approach to enable near real-time data analytics
Healthcare providers have an opportunity to improve the patient experience by collecting and analyzing broader and more diverse datasets. This includes patient medical history, allergies, immunizations, family disease history, and individuals’ lifestyle data such as workout habits. Having access to those datasets and forming a 360-degree view of patients allows healthcare providers such as claim […]

Exploring real-time streaming for generative AI Applications
Foundation models (FMs) are large machine learning (ML) models trained on a broad spectrum of unlabeled and generalized datasets. FMs, as the name suggests, provide the foundation to build more specialized downstream applications, and are unique in their adaptability. They can perform a wide range of different tasks, such as natural language processing, classifying images, […]

Hybrid Search with Amazon OpenSearch Service
This post explains the internals of hybrid search and how to build a hybrid search solution using OpenSearch Service. We experiment with sample queries to explore and compare lexical, semantic, and hybrid search. All the code used in this post is publicly available in the GitHub repository.

Build a RAG data ingestion pipeline for large-scale ML workloads
For building any generative AI application, enriching the large language models (LLMs) with new data is imperative. This is where the Retrieval Augmented Generation (RAG) technique comes in. RAG is a machine learning (ML) architecture that uses external documents (like Wikipedia) to augment its knowledge and achieve state-of-the-art results on knowledge-intensive tasks. For ingesting these […]

Preprocess and fine-tune LLMs quickly and cost-effectively using Amazon EMR Serverless and Amazon SageMaker
Large language models (LLMs) are becoming increasing popular, with new use cases constantly being explored. In general, you can build applications powered by LLMs by incorporating prompt engineering into your code. However, there are cases where prompting an existing LLM falls short. This is where model fine-tuning can help. Prompt engineering is about guiding the […]

Power neural search with AI/ML connectors in Amazon OpenSearch Service
With the launch of the neural search feature for Amazon OpenSearch Service in OpenSearch 2.9, it’s now effortless to integrate with AI/ML models to power semantic search and other use cases. OpenSearch Service has supported both lexical and vector search since the introduction of its k-nearest neighbor (k-NN) feature in 2020; however, configuring semantic search […]

Build scalable and serverless RAG workflows with a vector engine for Amazon OpenSearch Serverless and Amazon Bedrock Claude models
In pursuit of a more efficient and customer-centric support system, organizations are deploying cutting-edge generative AI applications. These applications are designed to excel in four critical areas: multi-lingual support, sentiment analysis, personally identifiable information (PII) detection, and conversational search capabilities. Customers worldwide can now engage with the applications in their preferred language, and the applications […]
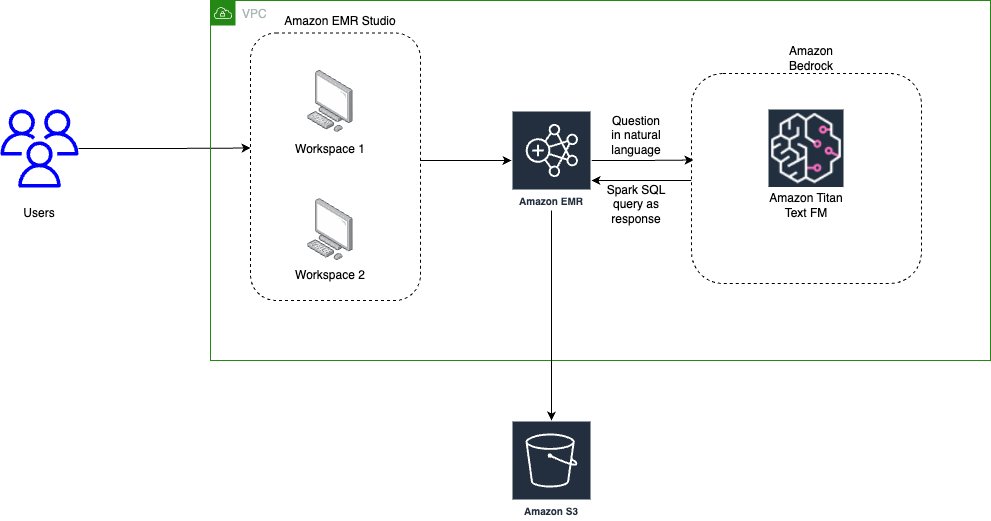
Use generative AI with Amazon EMR, Amazon Bedrock, and English SDK for Apache Spark to unlock insights
In this era of big data, organizations worldwide are constantly searching for innovative ways to extract value and insights from their vast datasets. Apache Spark offers the scalability and speed needed to process large amounts of data efficiently. Amazon EMR is the industry-leading cloud big data solution for petabyte-scale data processing, interactive analytics, and machine […]