AWS Big Data Blog
Category: AWS Lambda
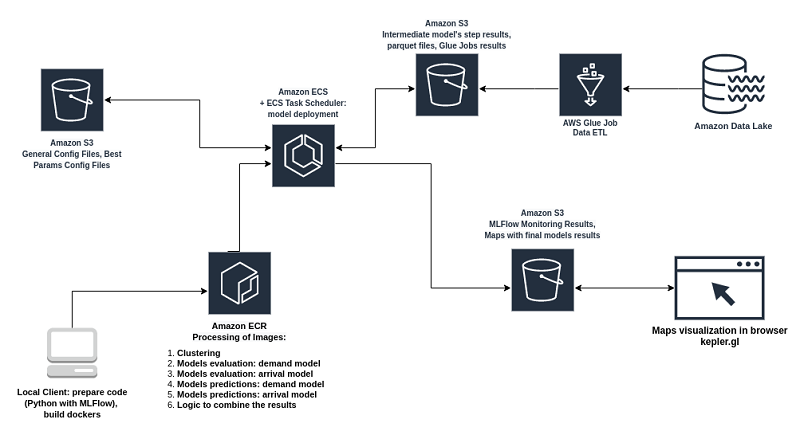
How Wind Mobility built a serverless data architecture
We parse through millions of scooter and user events generated daily (over 300 events per second) to extract actionable insight. We selected AWS Glue to perform this task. Our primary ETL job reads the newly added raw event data from Amazon S3, processes it using Apache Spark, and writes the results to our Amazon Redshift data warehouse. AWS Glue plays a critical role in our ability to scale on demand. After careful evaluation and testing, we concluded that AWS Glue ETL jobs meet all our needs and free us from procuring and managing infrastructure.

Ingest Excel data automatically into Amazon QuickSight
Amazon QuickSight is a fast, cloud-powered, business intelligence (BI) service that makes it easy to deliver insights to everyone in your organization. This post demonstrates how to build a serverless data ingestion pipeline to automatically import frequently changed data into a SPICE (Super-fast, Parallel, In-memory Calculation Engine) dataset of Amazon QuickSight dashboards. It is sometimes […]

How Siemens built a fully managed scheduling mechanism for updates on Amazon S3 data lakes
Siemens is a global technology leader with more than 370,000 employees and 170 years of experience. To protect Siemens from cybercrime, the Siemens Cyber Defense Center (CDC) continuously monitors Siemens’ networks and assets. To handle the resulting enormous data load, the CDC built a next-generation threat detection and analysis platform called ARGOS. ARGOS is a […]
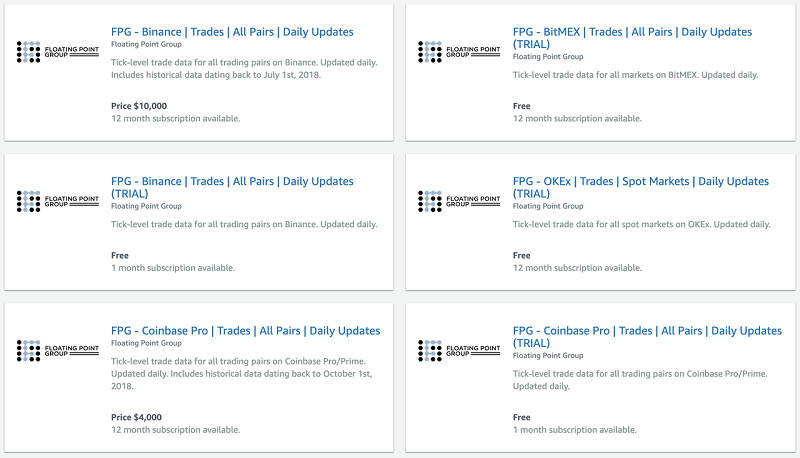
Collect and distribute high-resolution crypto market data with ECS, S3, Athena, Lambda, and AWS Data Exchange
This is a guest post by Floating Point Group. In their own words, “Floating Point Group is on a mission to bring institutional-grade trading services to the world of cryptocurrency.” The need and demand for financial infrastructure designed specifically for trading digital assets may not be obvious. There’s a rather pervasive narrative that these coins […]

Optimize downstream data processing with Amazon Data Firehose and Amazon EMR running Apache Spark
This blog post shows how to use Amazon Kinesis Data Firehose to merge many small messages into larger messages for delivery to Amazon S3, which results in faster processing with Amazon EMR running Spark. This post also shows how to read the compressed files using Apache Spark that are in Amazon S3, which does not have a proper file name extension and store back in Amazon S3 in parquet format.

Optimize Amazon EMR costs with idle checks and automatic resource termination using advanced Amazon CloudWatch metrics and AWS Lambda
Many customers use Amazon EMR to run big data workloads, such as Apache Spark and Apache Hive queries, in their development environment. Data analysts and data scientists frequently use these types of clusters, known as analytics EMR clusters. Users often forget to terminate the clusters after their work is done. This leads to idle running […]

Build and automate a serverless data lake using an AWS Glue trigger for the Data Catalog and ETL jobs
September 2022: This post was reviewed and updated with latest screenshots and instructions. Today, data is flowing from everywhere, whether it is unstructured data from resources like IoT sensors, application logs, and clickstreams, or structured data from transaction applications, relational databases, and spreadsheets. Data has become a crucial part of every business. This has resulted […]
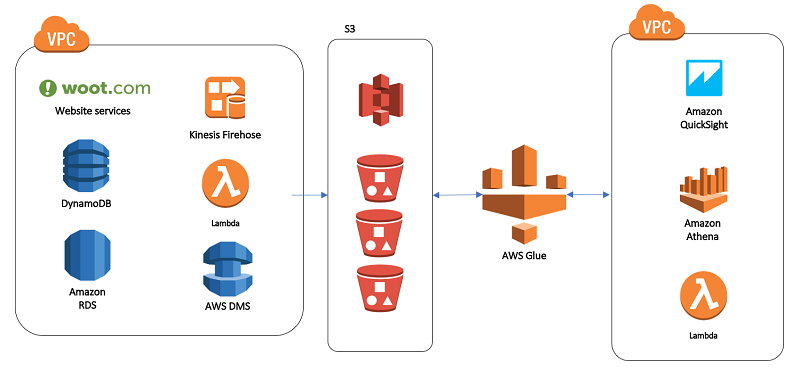
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 1
In this two-part series, we show you how to build a data pipeline in support of a data lake. We use key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we focus on generating simple inferences from that data that can support RTP parameters.