AWS Big Data Blog
Category: Amazon RDS

How ZS created a multi-tenant self-service data orchestration platform using Amazon MWAA
This is post is co-authored by Manish Mehra, Anirudh Vohra, Sidrah Sayyad, and Abhishek I S (from ZS), and Parnab Basak (from AWS). The team at ZS collaborated closely with AWS to build a modern, cloud-native data orchestration platform. ZS is a management consulting and technology firm focused on transforming global healthcare and beyond. We […]

Optimize Federated Query Performance using EXPLAIN and EXPLAIN ANALYZE in Amazon Athena
Amazon Athena is an interactive query service that makes it easy to analyze data in Amazon Simple Storage Service (Amazon S3) using standard SQL. Athena is serverless, so there is no infrastructure to manage, and you pay only for the queries that you run. In 2019, Athena added support for federated queries to run SQL […]

How ENGIE scales their data ingestion pipelines using Amazon MWAA
ENGIE—one of the largest utility providers in France and a global player in the zero-carbon energy transition—produces, transports, and deals electricity, gas, and energy services. With 160,000 employees worldwide, ENGIE is a decentralized organization and operates 25 business units with a high level of delegation and empowerment. ENGIE’s decentralized global customer base had accumulated lots […]

Amazon QuickSight deployment models for cross-account and cross-Region access to Amazon Redshift and Amazon RDS
Many AWS customers use multiple AWS accounts and Regions across different departments and applications within the same company. However, you might deploy services like Amazon QuickSight using a single-account approach to centralize users, data source access, and dashboard management. This post explores how you can use different Amazon Virtual Private Cloud (Amazon VPC) private connectivity features to connect QuickSight […]
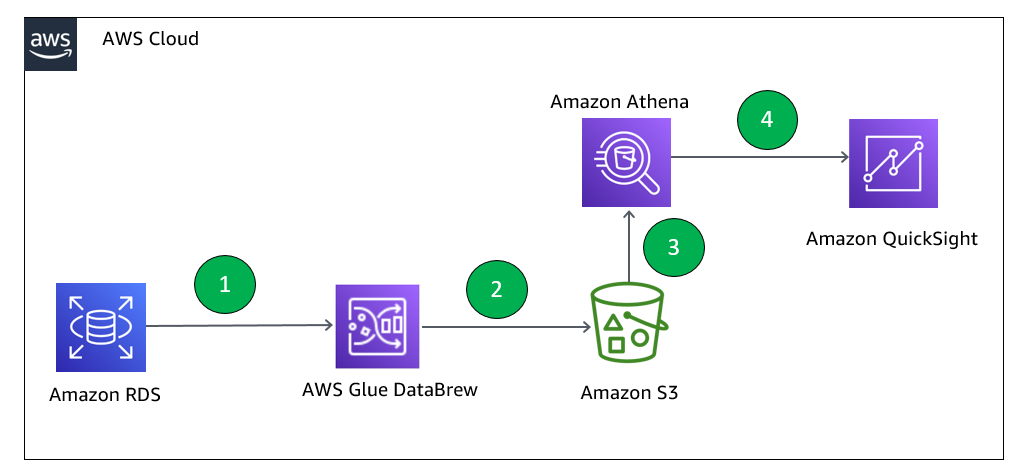
Data preparation using an Amazon RDS for MySQL database with AWS Glue DataBrew
With AWS Glue DataBrew, data analysts and data scientists can easily access and visually explore any amount of data across their organization directly from their Amazon Simple Storage Service (Amazon S3) data lake, Amazon Redshift data warehouse, or Amazon Aurora and Amazon Relational Database Service (Amazon RDS) databases. You can choose from over 250 built-in […]

Query your Oracle database using Athena Federated Query and join with data in your Amazon S3 data lake
This post was last reviewed and updated July, 2022 with updates in Athena federation connector. If you use data lakes in Amazon Simple Storage Service (Amazon S3) and use Oracle as your transactional data store, you may need to join the data in your data lake with Oracle on Amazon Relational Database Service (Amazon RDS), Oracle running on Amazon […]
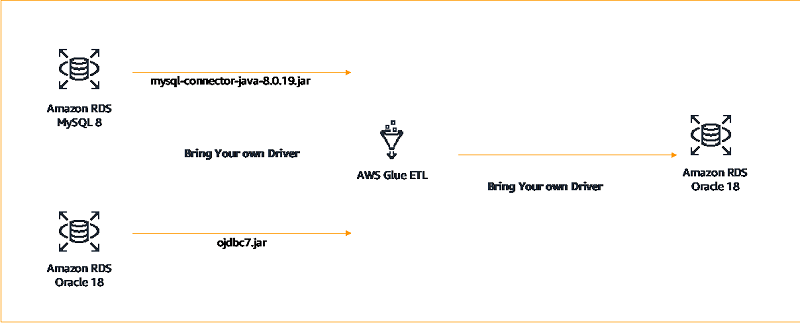
Building AWS Glue Spark ETL jobs by bringing your own JDBC drivers for Amazon RDS
AWS Glue is a fully managed extract, transform, and load (ETL) service that makes it easy to prepare and load your data for analytics. AWS Glue has native connectors to connect to supported data sources either on AWS or elsewhere using JDBC drivers. Additionally, AWS Glue now enables you to bring your own JDBC drivers […]

Sharing Amazon Redshift data securely across Amazon Redshift clusters for workload isolation
Amazon Redshift data sharing allows for a secure and easy way to share live data for read purposes across Amazon Redshift clusters. Amazon Redshift is a fast, fully managed cloud data warehouse that makes it simple and cost-effective to analyze all your data using standard SQL and your existing business intelligence (BI) tools. It allows […]
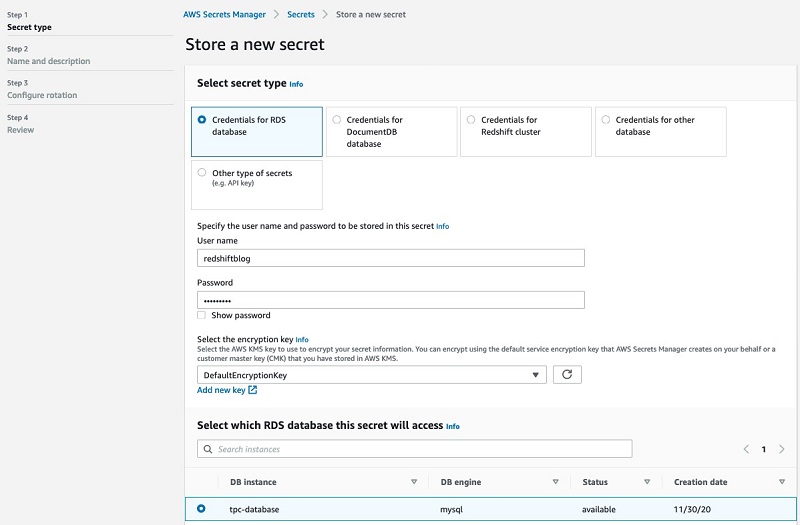
Announcing Amazon Redshift federated querying to Amazon Aurora MySQL and Amazon RDS for MySQL
Since we launched Amazon Redshift as a cloud data warehouse service more than seven years ago, tens of thousands of customers have built analytics workloads using it. We’re always listening to your feedback and, in April 2020, we announced general availability for federated querying to Amazon Aurora PostgreSQL and Amazon Relational Database Service (Amazon RDS) […]

Accessing and visualizing external tables in an Apache Hive metastore with Amazon Athena and Amazon QuickSight
Many organizations have an Apache Hive metastore that stores the schemas for their data lake. You can use Amazon Athena due to its serverless nature; Athena makes it easy for anyone with SQL skills to quickly analyze large-scale datasets. You may also want to reliably query the rich datasets in the lake, with their schemas […]