AWS Big Data Blog
Category: Database
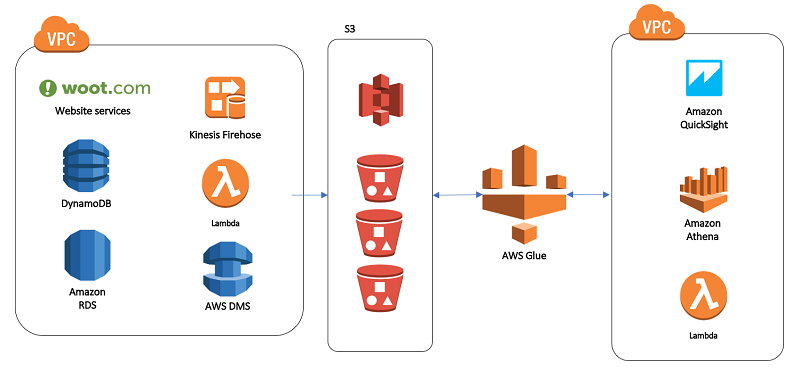
Our data lake story: How Woot.com built a serverless data lake on AWS
February 9, 2024: Amazon Kinesis Data Firehose has been renamed to Amazon Data Firehose. Read the AWS What’s New post to learn more. In this post, we talk about designing a cloud-native data warehouse as a replacement for our legacy data warehouse built on a relational database. At the beginning of the design process, the […]

Run Amazon payments analytics with 750 TB of data on Amazon Redshift
The Amazon Payments Data Engineering team is responsible for data ingestion, transformation, and storage of a growing dataset of more than 750 TB. The team makes these services available to more than 300 business customers around the globe. These customers include managers from the product, marketing, and programs domains; as well as data scientists, business analysts, […]
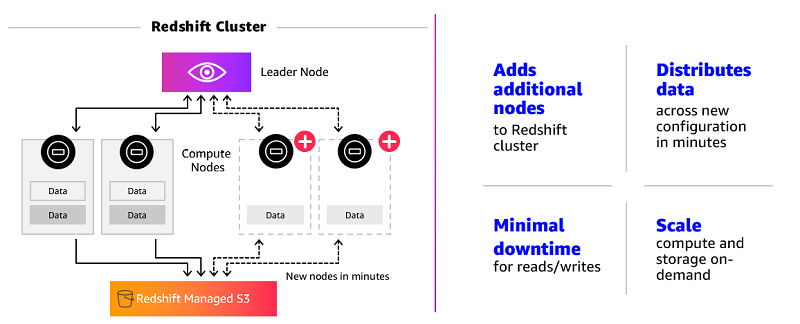
Scale your Amazon Redshift clusters up and down in minutes to get the performance you need, when you need it
Amazon Redshift is the cloud data warehouse of choice for organizations of all sizes—from fast-growing technology companies such as Turo and Yelp to Fortune 500 companies such as 21st Century Fox and Johnson & Johnson. With quickly expanding use cases, data sizes, and analyst populations, these customers have a critical need for scalable data warehouses. […]
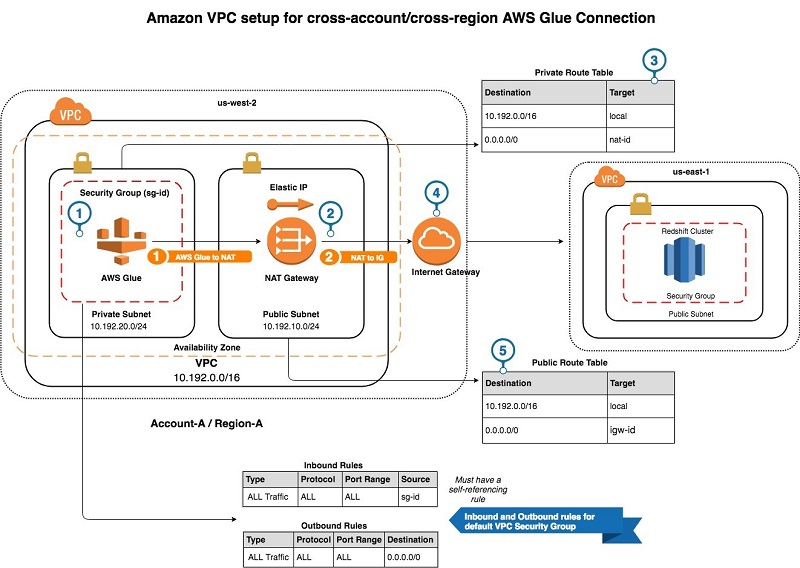
Create cross-account and cross-region AWS Glue connections
In this blog post, we describe how to configure the networking routes and interfaces to give AWS Glue access to a data store in an AWS Region different from the one with your AWS Glue resources. In our example, we connect AWS Glue, located in Region A, to an Amazon Redshift data warehouse located in Region B.
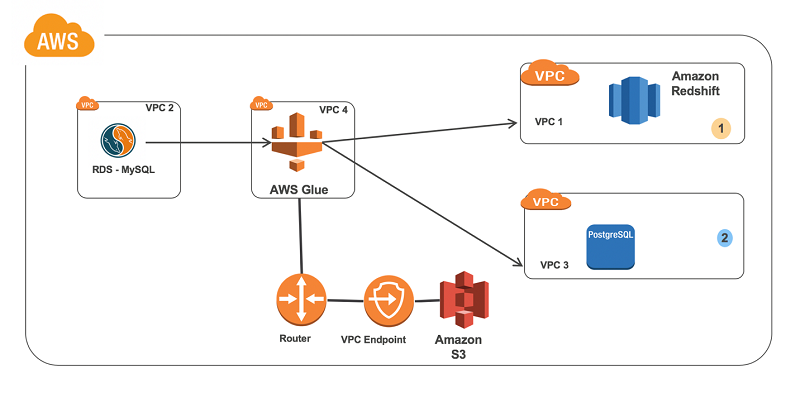
Connect to and run ETL jobs across multiple VPCs using a dedicated AWS Glue VPC
In this blog post, we’ll go through the steps needed to build an ETL pipeline that consumes from one source in one VPC and outputs it to another source in a different VPC. We’ll set up in multiple VPCs to reproduce a situation where your database instances are in multiple VPCs for isolation related to security, audit, or other purposes.

Chasing earthquakes: How to prepare an unstructured dataset for visualization via ETL processing with Amazon Redshift
As organizations expand analytics practices and hire data scientists and other specialized roles, big data pipelines are growing increasingly complex. Sophisticated models are being built using the troves of data being collected every second. The bottleneck today is often not the know-how of analytical techniques. Rather, it’s the difficulty of building and maintaining ETL (extract, transform, and load) jobs using tools that might be unsuitable for the cloud. In this post, I demonstrate a solution to this challenge.
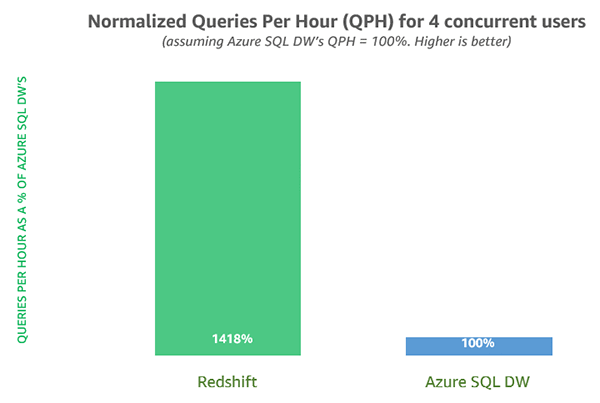
Performance matters: Amazon Redshift is now up to 3.5x faster for real-world workloads
Since we launched Amazon Redshift, thousands of customers have trusted us to get uncompromising speed for their most complex analytical workloads. Over the course of 2017, our customers benefited from a 3x to 5x performance gain, resulting from short query acceleration, result caching, late materialization, and many other under-the-hood improvements. In this post, we highlight […]
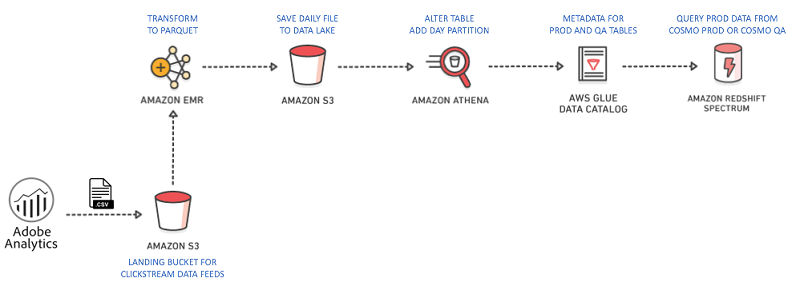
Close the customer journey loop with Amazon Redshift at Equinox Fitness Clubs
Clickstream analysis tools handle their data well, and some even have impressive BI interfaces. However, analyzing clickstream data in isolation comes with many limitations. For example, a customer is interested in a product or service on your website. They go to your physical store to purchase it. The clickstream analyst asks, “What happened after they […]
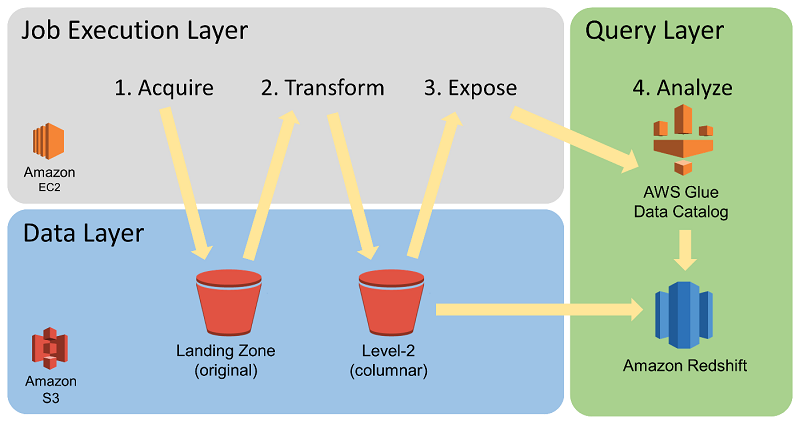
How Annalect built an event log data analytics solution using Amazon Redshift
By establishing a data warehouse strategy using Amazon S3 for storage and Redshift Spectrum for analytics, we increased the size of the datasets we support by over an order of magnitude. In addition, we improved our ability to ingest large volumes of data quickly, and maintained fast performance without increasing our costs. Our analysts and modelers can now perform deeper analytics to improve ad buying strategies and results.

How to build a front-line concussion monitoring system using AWS IoT and serverless data lakes – Part 2
August 2024: This post was reviewed and updated for accuracy. In part 1 of this series, we demonstrated how to build a data pipeline in support of a data lake. We used key AWS services such as Amazon Kinesis Data Streams, Kinesis Data Analytics, Kinesis Data Firehose, and AWS Lambda. In part 2, we discuss […]