AWS Big Data Blog
Category: Advanced (300)

Power neural search with AI/ML connectors in Amazon OpenSearch Service
With the launch of the neural search feature for Amazon OpenSearch Service in OpenSearch 2.9, it’s now effortless to integrate with AI/ML models to power semantic search and other use cases. OpenSearch Service has supported both lexical and vector search since the introduction of its k-nearest neighbor (k-NN) feature in 2020; however, configuring semantic search […]

Accelerate analytics on Amazon OpenSearch Service with AWS Glue through its native connector
As the volume and complexity of analytics workloads continue to grow, customers are looking for more efficient and cost-effective ways to ingest and analyse data. Data is stored from online systems such as the databases, CRMs, and marketing systems to data stores such as data lakes on Amazon Simple Storage Service (Amazon S3), data warehouses […]

Build efficient ETL pipelines with AWS Step Functions distributed map and redrive feature
AWS Step Functions is a fully managed visual workflow service that enables you to build complex data processing pipelines involving a diverse set of extract, transform, and load (ETL) technologies such as AWS Glue, Amazon EMR, and Amazon Redshift. You can visually build the workflow by wiring individual data pipeline tasks and configuring payloads, retries, […]

Visualize Amazon DynamoDB insights in Amazon QuickSight using the Amazon Athena DynamoDB connector and AWS Glue
May 2025: This post was reviewed for accuracy. Amazon DynamoDB is a fully managed, serverless, key-value NoSQL database designed to run high-performance applications at any scale. DynamoDB offers built-in security, continuous backups, automated multi-Region replication, in-memory caching, and data import and export tools. The scalability and flexible data schema of DynamoDB make it well-suited for […]

Power enterprise-grade Data Vaults with Amazon Redshift – Part 1
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than other cloud data warehouses. As with all AWS […]
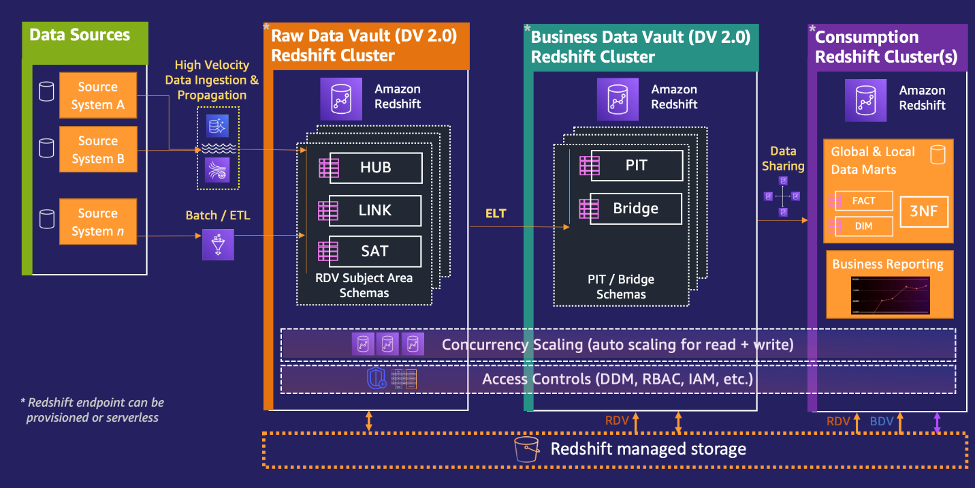
Power enterprise-grade Data Vaults with Amazon Redshift – Part 2
Amazon Redshift is a popular cloud data warehouse, offering a fully managed cloud-based service that seamlessly integrates with an organization’s Amazon Simple Storage Service (Amazon S3) data lake, real-time streams, machine learning (ML) workflows, transactional workflows, and much more—all while providing up to 7.9x better price-performance than any other cloud data warehouses. As with all […]

Implement Apache Flink real-time data enrichment patterns
You can use several approaches to enrich your real-time data in Amazon Managed Service for Apache Flink depending on your use case and Apache Flink abstraction level. Each method has different effects on the throughput, network traffic, and CPU (or memory) utilization. For a general overview of data enrichment patterns, refer to Common streaming data enrichment patterns in Amazon Managed Service for Apache Flink. This post covers how you can implement data enrichment for real-time streaming events with Apache Flink and how you can optimize performance. To compare the performance of the enrichment patterns, we ran performance testing based on synthetic data. The result of this test is useful as a general reference. It’s important to note that the actual performance for your Flink workload will depend on various and different factors, such as API latency, throughput, size of the event, and cache hit ratio.

Clean up your Excel and CSV files without writing code using AWS Glue DataBrew
Managing data within an organization is complex. Handling data from outside the organization adds even more complexity. As the organization receives data from multiple external vendors, it often arrives in different formats, typically Excel or CSV files, with each vendor using their own unique data layout and structure. In this blog post, we’ll explore a […]

Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools such as Spark UI and YARN Timeline Server via […]

Implement model versioning with Amazon Redshift ML
Amazon Redshift ML allows data analysts, developers, and data scientists to train machine learning (ML) models using SQL. In previous posts, we demonstrated how you can use the automatic model training capability of Redshift ML to train classification and regression models. Redshift ML allows you to create a model using SQL and specify your algorithm, […]