AWS Big Data Blog
Category: Advanced (300)

On-demand and scheduled scaling of Amazon MSK Express based clusters
Amazon MSK Express brokers are a key component to dynamically scaling clusters to meet demand. Express based clusters deliver 3 times higher throughput, 20 times faster scaling capabilities, and 90% faster broker recovery compared to Amazon MSK Provisioned clusters. In addition, Express brokers support intelligent rebalancing for 180 times faster operation performance, so partitions are automatically and consistently well distributed across brokers. Intelligent rebalancing automatically tracks cluster health and triggers partition redistribution when resource imbalances are detected, maintaining performance across brokers. This post demonstrates how to use the intelligent rebalancing feature and build a custom solution that scales Express based clusters horizontally (adding and removing brokers) dynamically based on Amazon CloudWatch metrics and predefined schedules. The solution provides capacity management while maintaining cluster performance and minimizing overhead.
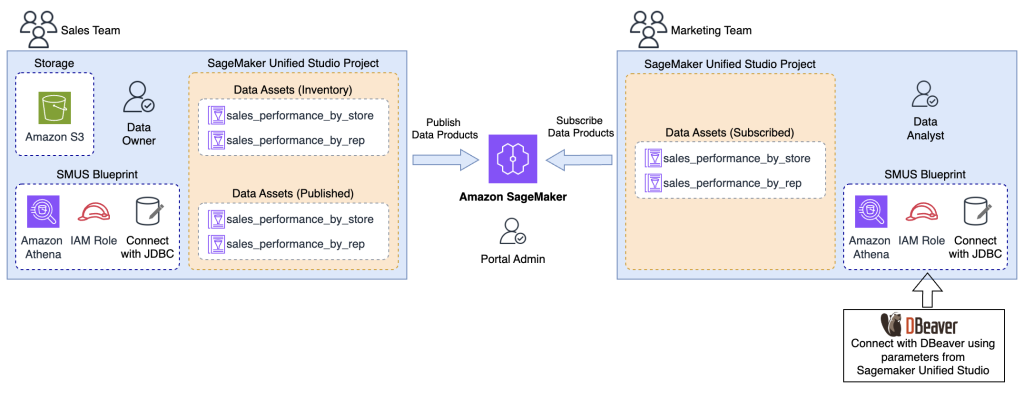
Power up your analytics with Amazon SageMaker Unified Studio integration with Tableau, Power BI, and more
In this post, we guide you through connecting various analytics tools to Amazon SageMaker Unified Studio using the Athena JDBC driver, enabling seamless access to your subscribed data within your Amazon SageMaker Unified Studio projects.

Accelerate context-aware data analysis and ML workflows with Amazon SageMaker Data Agent
In this post, we demonstrate the capabilities of SageMaker Data Agent, discuss the challenges it addresses, and explore a real-world example analyzing New York City taxi trip data to see the agent in action.
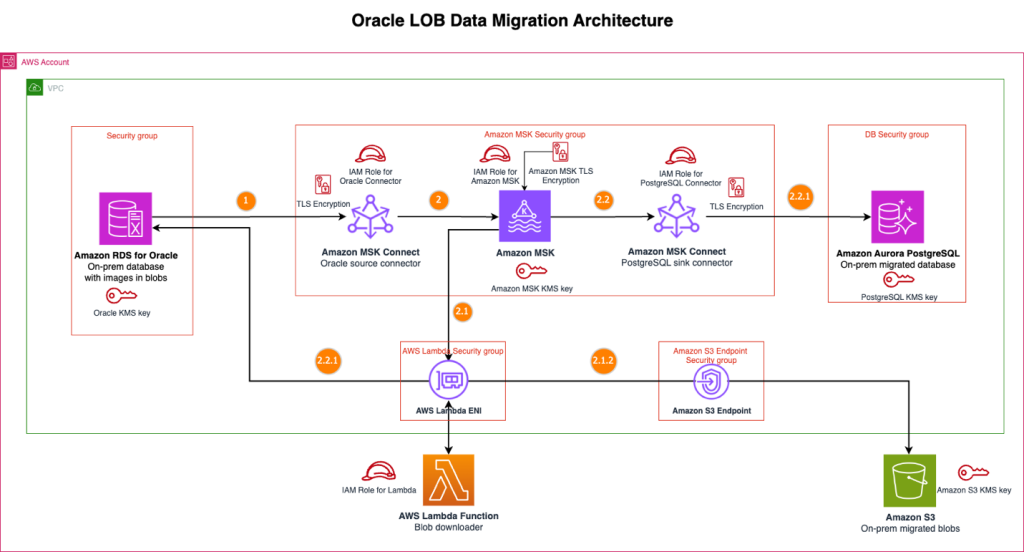
Streamline large binary object migrations: A Kafka-based solution for Oracle to Amazon Aurora PostgreSQL and Amazon S3
In this post, we present a scalable solution that addresses the challenge of migrating your large binary objects (LOBs) from Oracle to AWS by using a streaming architecture that separates LOB storage from structured data. This approach avoids size constraints, reduces Oracle licensing costs, and preserves data integrity throughout extended migration periods.

How Bazaarvoice modernized their Apache Kafka infrastructure with Amazon MSK
Bazaarvoice is an Austin-based company powering a world-leading reviews and ratings platform. Our system processes billions of consumer interactions through ratings, reviews, images, and videos, helping brands and retailers build shopper confidence and drive sales by using authentic user-generated content (UGC) across the customer journey. In this post, we show you the steps we took to migrate our workloads from self-hosted Kafka to Amazon Managed Streaming for Apache Kafka (Amazon MSK). We walk you through our migration process and highlight the improvements we achieved after this transition.

Enterprise scale in-place migration to Apache Iceberg: Implementation guide
Organizations managing large-scale analytical workloads increasingly face challenges with traditional Apache Parquet-based data lakes with Hive-style partitioning, including slow queries, complex file management, and limited consistency guarantees. Apache Iceberg addresses these pain points by providing ACID transactions, seamless schema evolution, and point-in-time data recovery capabilities that transform how enterprises handle their data infrastructure. In this post, we demonstrate how you can achieve migration at scale from existing Parquet tables to Apache Iceberg tables. Using Amazon DynamoDB as a central orchestration mechanism, we show how you can implement in-place migrations that are highly configurable, repeatable, and fault-tolerant.
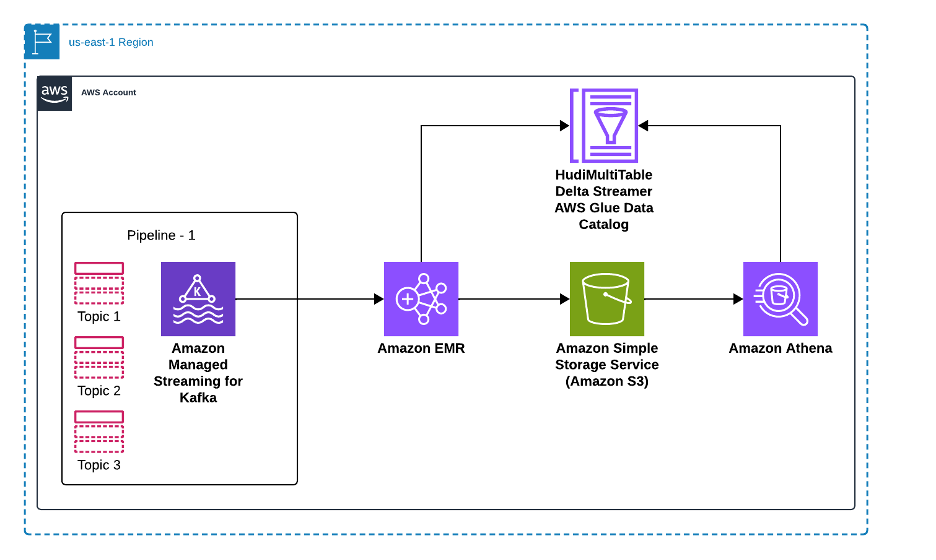
Using Amazon EMR DeltaStreamer to stream data to multiple Apache Hudi tables
In this post, we show you how to implement real-time data ingestion from multiple Kafka topics to Apache Hudi tables using Amazon EMR. This solution streamlines data ingestion by processing multiple Amazon Managed Streaming for Apache Kafka (Amazon MSK) topics in parallel while providing data quality and scalability through change data capture (CDC) and Apache Hudi.
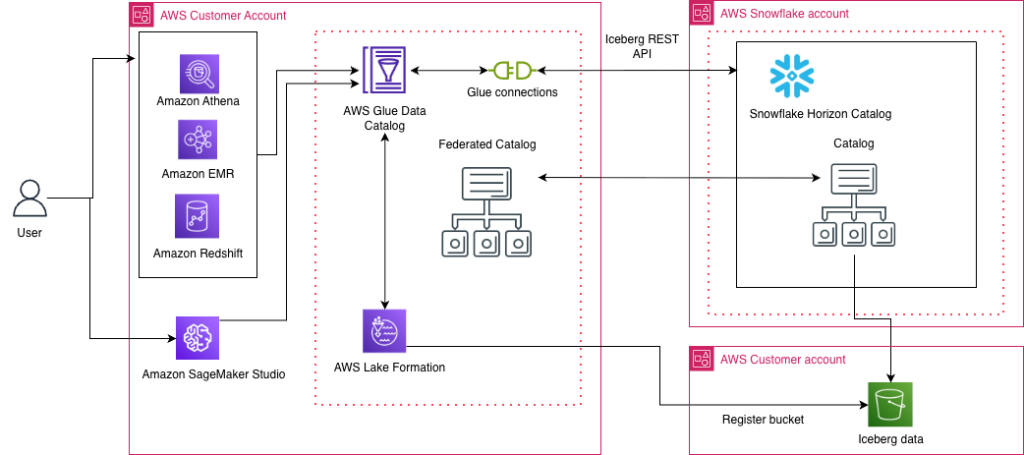
Access Snowflake Horizon Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has introduced a new catalog federation feature that enables direct access to Snowflake Horizon Catalog data through AWS Glue Data Catalog. This integration allows organizations to discover and query data in Iceberg format while maintaining security through AWS Lake Formation. This post provides a step-by-step guide to establishing this integration, including configuring Snowflake Horizon Catalog, setting up authentication, creating necessary IAM roles, and implementing AWS Lake Formation permissions. Learn how to enable cross-platform analytics while maintaining robust security and governance across your data environment.
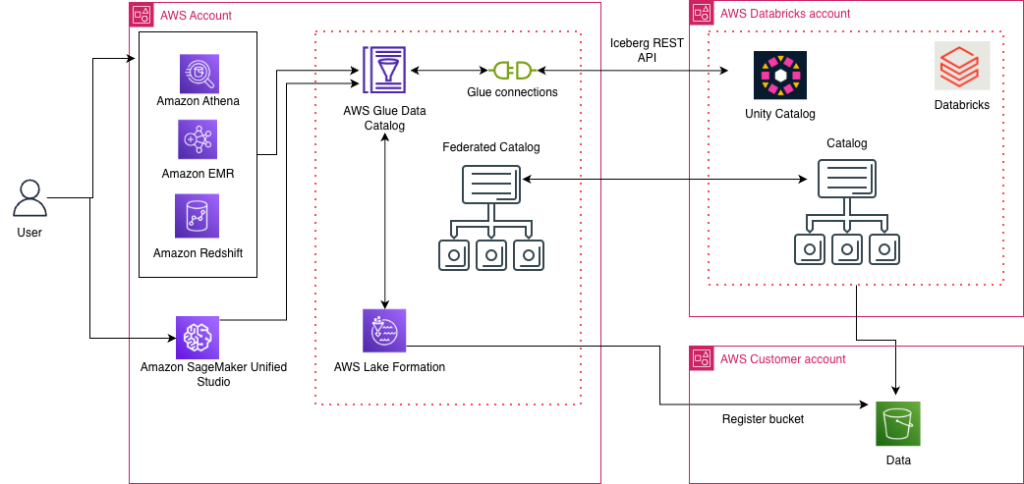
Access Databricks Unity Catalog data using catalog federation in the AWS Glue Data Catalog
AWS has launched the catalog federation capability, enabling direct access to Apache Iceberg tables managed in Databricks Unity Catalog through the AWS Glue Data Catalog. With this integration, you can discover and query Unity Catalog data in Iceberg format using an Iceberg REST API endpoint, while maintaining granular access controls through AWS Lake Formation. In this post, we demonstrate how to set up catalog federation between the Glue Data Catalog and Databricks Unity Catalog, enabling data querying using AWS analytics services.

Use Amazon SageMaker custom tags for project resource governance and cost tracking
Amazon SageMaker announced a new feature that you can use to add custom tags to resources created through an Amazon SageMaker Unified Studio project. This helps you enforce tagging standards that conform to your organization’s service control policies (SCPs) and helps enable cost tracking reporting practices on resources created across the organization. In this post, we look at use cases for custom tags and how to use the AWS Command Line Interface (AWS CLI) to add tags to project resources.