AWS Big Data Blog
Category: Security, Identity, & Compliance

Simplify data lake access control for your enterprise users with trusted identity propagation in AWS IAM Identity Center, AWS Lake Formation, and Amazon S3 Access Grants
Many organizations use external identity providers (IdPs) such as Okta or Microsoft Azure Active Directory to manage their enterprise user identities. These users interact with and run analytical queries across AWS analytics services. To enable them to use the AWS services, their identities from the external IdP are mapped to AWS Identity and Access Management […]

Use your corporate identities for analytics with Amazon EMR and AWS IAM Identity Center
To enable your workforce users for analytics with fine-grained data access controls and audit data access, you might have to create multiple AWS Identity and Access Management (IAM) roles with different data permissions and map the workforce users to one of those roles. Multiple users are often mapped to the same role where they need […]

Simplify access management with Amazon Redshift and AWS Lake Formation for users in an External Identity Provider
Many organizations use identity providers (IdPs) to authenticate users, manage their attributes, and group memberships for secure, efficient, and centralized identity management. You might be modernizing your data architecture using Amazon Redshift to enable access to your data lake and data in your data warehouse, and are looking for a centralized and scalable way to […]

Build SAML identity federation for Amazon OpenSearch Service domains within a VPC
Amazon OpenSearch Service is a fully managed search and analytics service powered by the Apache Lucene search library that can be operated within a virtual private cloud (VPC). A VPC is a virtual network that’s dedicated to your AWS account. It’s logically isolated from other virtual networks in the AWS Cloud. Placing an OpenSearch Service […]

Integrate Identity Provider (IdP) with Amazon Redshift Query Editor V2 and SQL Client using AWS IAM Identity Center for seamless Single Sign-On
October 2024: This post was reviewed and updated to update SQL Client setup instructions. AWS IAM Identity Center allows you to manage single sign-on (SSO) access to all your AWS accounts and applications from a single location. We are pleased to announce that Amazon Redshift now integrates with AWS IAM Identity Center, and supports trusted identity propagation, allowing you […]

Introducing shared VPC support on Amazon MWAA
In this post, we demonstrate automating deployment of Amazon Managed Workflows for Apache Airflow (Amazon MWAA) using customer-managed endpoints in a VPC, providing compatibility with shared, or otherwise restricted, VPCs. Data scientists and engineers have made Apache Airflow a leading open source tool to create data pipelines due to its active open source community, familiar […]
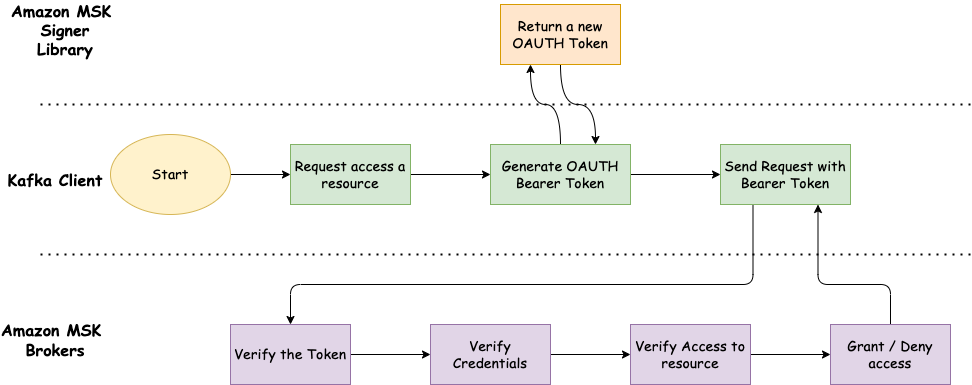
Amazon MSK IAM authentication now supports all programming languages
The AWS Identity and Access Management (IAM) authentication feature in Amazon Managed Streaming for Apache Kafka (Amazon MSK) now supports all programming languages. Administrators can simplify and standardize access control to Kafka resources using IAM. This support is based on SASL/OUATHBEARER, an open standard for authorization and authentication. Both Amazon MSK provisioned and serverless cluster […]

Enhance your security posture by storing Amazon Redshift admin credentials without human intervention using AWS Secrets Manager integration
Amazon Redshift is a fully managed, petabyte-scale data warehouse service in the cloud. You can start with just a few hundred gigabytes of data and scale to a petabyte or more. Today, tens of thousands of AWS customers—from Fortune 500 companies, startups, and everything in between—use Amazon Redshift to run mission-critical business intelligence (BI) dashboards, […]
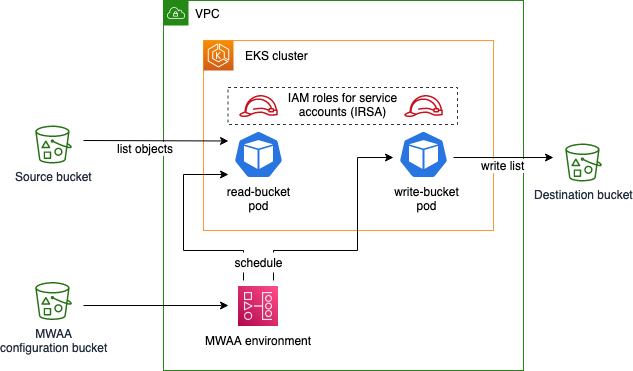
Set up fine-grained permissions for your data pipeline using MWAA and EKS
This blog post shows how to improve security in a data pipeline architecture based on Amazon Managed Workflows for Apache Airflow (Amazon MWAA) and Amazon Elastic Kubernetes Service (Amazon EKS) by setting up fine-grained permissions, using HashiCorp Terraform for infrastructure as code.

Build streaming data pipelines with Amazon MSK Serverless and IAM authentication
Amazon’s serverless Apache Kafka offering, Amazon Managed Streaming for Apache Kafka (Amazon MSK) Serverless, is attracting a lot of interest. It’s appreciated for its user-friendly approach, ability to scale automatically, and cost-saving benefits over other Kafka solutions. However, a hurdle encountered by many users is the requirement of MSK Serverless to use AWS Identity and Access Management (IAM) access control. At the time of writing, the Amazon MSK library for IAM is exclusive to Kafka libraries in Java, creating a challenge for users of other programming languages. In this post, we aim to address this issue and present how you can use Amazon API Gateway and AWS Lambda to navigate around this obstacle.