AWS Big Data Blog
Category: Amazon Simple Storage Service (S3)
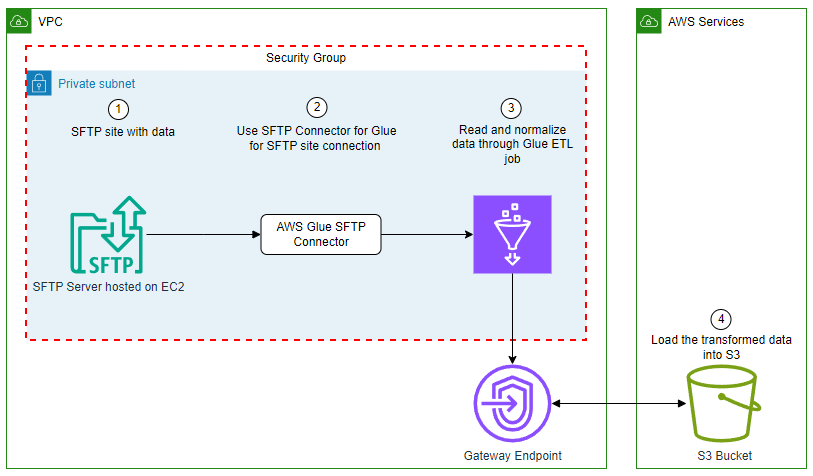
Use AWS Glue to streamline SFTP data processing
In this blog post, we explore how to use the SFTP Connector for AWS Glue from the AWS Marketplace to efficiently process data from Secure File Transfer Protocol (SFTP) servers into Amazon Simple Storage Service (Amazon S3), further empowering your data analytics and insights.

Stream data to Amazon S3 for real-time analytics using the Oracle GoldenGate S3 handler
Modern business applications rely on timely and accurate data with increasing demand for real-time analytics. There is a growing need for efficient and scalable data storage solutions. Data at times is stored in different datasets and needs to be consolidated before meaningful and complete insights can be drawn from the datasets. This is where replication […]

Migrate data from an on-premises Hadoop environment to Amazon S3 using S3DistCp with AWS Direct Connect
This post demonstrates how to migrate nearly any amount of data from an on-premises Apache Hadoop environment to Amazon Simple Storage Service (Amazon S3) by using S3DistCp on Amazon EMR with AWS Direct Connect. To transfer resources from a target EMR cluster, the traditional Hadoop DistCp must be run on the source cluster to move […]

Disaster recovery strategies for Amazon MWAA – Part 2
Amazon Managed Workflows for Apache Airflow (Amazon MWAA) is a fully managed orchestration service that makes it straightforward to run data processing workflows at scale. Amazon MWAA takes care of operating and scaling Apache Airflow so you can focus on developing workflows. However, although Amazon MWAA provides high availability within an AWS Region through features […]

Modernize your data observability with Amazon OpenSearch Service zero-ETL integration with Amazon S3
We are excited to announce the general availability of Amazon OpenSearch Service zero-ETL integration with Amazon Simple Storage Service (Amazon S3) for domains running 2.13 and above. The integration is new way for customers to query operational logs in Amazon S3 and Amazon S3-based data lakes without needing to switch between tools to analyze operational data. By querying across OpenSearch Service and S3 datasets, you can evaluate multiple data sources to perform forensic analysis of operational and security events. The new integration with OpenSearch Service supports AWS’s zero-ETL vision to reduce the operational complexity of duplicating data or managing multiple analytics tools by enabling you to directly query your operational data, reducing costs and time to action.

Implement a full stack serverless search application using AWS Amplify, Amazon Cognito, Amazon API Gateway, AWS Lambda, and Amazon OpenSearch Serverless
Designing a full stack search application requires addressing numerous challenges to provide a smooth and effective user experience. This encompasses tasks such as integrating diverse data from various sources with distinct formats and structures, optimizing the user experience for performance and security, providing multilingual support, and optimizing for cost, operations, and reliability. Amazon OpenSearch Serverless […]

Simplify data lake access control for your enterprise users with trusted identity propagation in AWS IAM Identity Center, AWS Lake Formation, and Amazon S3 Access Grants
Many organizations use external identity providers (IdPs) such as Okta or Microsoft Azure Active Directory to manage their enterprise user identities. These users interact with and run analytical queries across AWS analytics services. To enable them to use the AWS services, their identities from the external IdP are mapped to AWS Identity and Access Management […]

Use Apache Iceberg in your data lake with Amazon S3, AWS Glue, and Snowflake
Customers are using AWS and Snowflake to develop purpose-built data architectures that provide the performance required for modern analytics and artificial intelligence (AI) use cases. Implementing these solutions requires data sharing between purpose-built data stores. This is why Snowflake and AWS are delivering enhanced support for Apache Iceberg to enable and facilitate data interoperability between data services. Apache Iceberg is an open-source table format that provides reliability, simplicity, and high performance for large datasets with transactional integrity between various processing engines.

Petabyte-scale log analytics with Amazon S3, Amazon OpenSearch Service, and Amazon OpenSearch Ingestion
Organizations often need to manage a high volume of data that is growing at an extraordinary rate. At the same time, they need to optimize operational costs to unlock the value of this data for timely insights and do so with a consistent performance. With this massive data growth, data proliferation across your data stores, […]

Use AWS Glue ETL to perform merge, partition evolution, and schema evolution on Apache Iceberg
As enterprises collect increasing amounts of data from various sources, the structure and organization of that data often need to change over time to meet evolving analytical needs. However, altering schema and table partitions in traditional data lakes can be a disruptive and time-consuming task, requiring renaming or recreating entire tables and reprocessing large datasets. […]