AWS Big Data Blog
Data: The genesis for modern invention
It only takes one groundbreaking invention—one iconic idea that solves a widespread pain point for customers—to create or transform an industry forever. From the invention of the telegraph, to the discovery of GPS, to the earliest cloud computing services, history is filled with examples of these “eureka” moments that continue to have long-lasting impacts on the way we do business today.
Cognitive scientists John Kounios and Mark Beeman demonstrated that great inventors don’t simply stumble upon their epiphanies; in reality, an idea is preceded by a collection of life experiences, educational knowledge, or even past failures the human brain processes and assimilates over time. Their ideas are preceded by a collection of data points.
When we apply this concept to organizations, and the vast amount of data being produced on a daily basis, we realize there’s an incredible opportunity to ingest, store, process, analyze, and visualize data to create the next big thing.
Today—more than ever before—data is the genesis for modern invention. But to produce new ideas with our data, we need to build dynamic, end-to-end data strategies that lead to new customer experiences as the final output. Some of the biggest brands in the world like Formula 1, Toyota, and Georgia-Pacific are already leveraging AWS to do just that.
This week at AWS re:Invent 2022, I shared several key learnings we’ve collected after working with these brands and more than 1.5 million customers who are using AWS to build their data strategies.
I also revealed several new services and innovations for our customers. Here are a few highlights.
You need a comprehensive set of services to get the job done
Creating a data lake to perform analytics and machine learning (ML) is not an end-to-end data strategy. Your needs will inevitably grow and change over time, which is why we believe every customer should have access to a wide variety of tools based on data types, personas, and their specific use cases.
And our data supports this, with 94% of the top 1,000 AWS customers using more than 10 of our databases and analytics services. A one-size-fits-all approach just doesn’t work in the long run.
You need a comprehensive set of services that enable you to store and query data in your databases, data lakes, and data warehouses; services that help you act on your data with analytics, business intelligence, and machine learning; and services that help you catalog and govern your data across your organization.
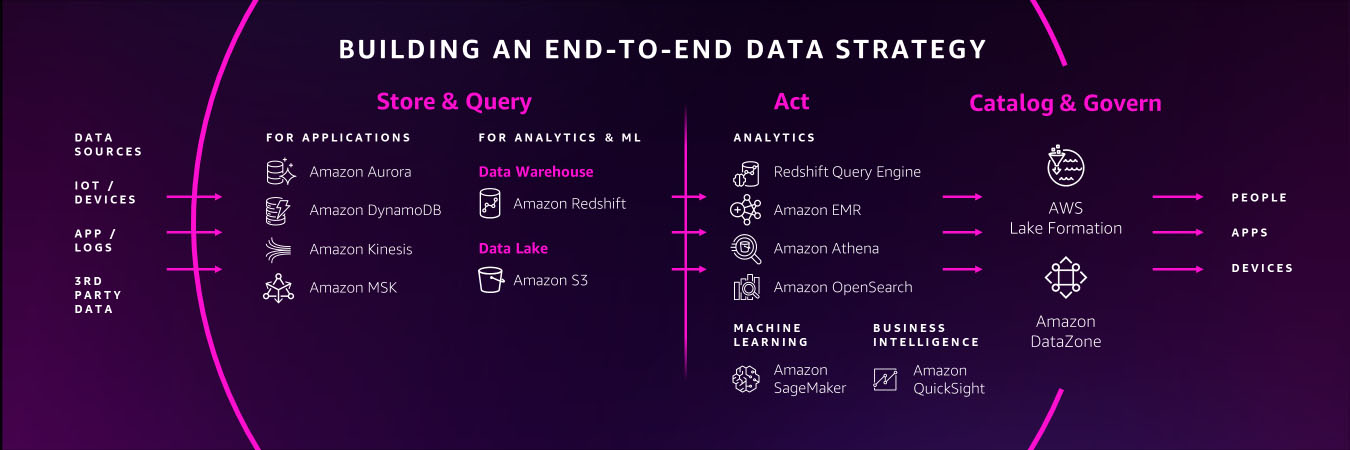
You should also have access to services that support a variety of data types for your future use cases, whether you’re working with financial data, clinical data, or retail data. Many of our customers are also using their data to create machine learning models, but some data types are still too cumbersome to work with and prepare for ML.
For example, geospatial data, which supports use cases like self-driving cars, urban planning, or even crop yield in agricultural farms, can be incredibly difficult to access, prepare, and visualize for ML. That’s why this week we announced new capabilities for Amazon SageMaker that make it easier for data scientists to work with geospatial data.
Performance and security are paramount
Performance and security continue to be critical components of our customers’ data strategies.
You’ll need to perform at scale across your data warehouses, databases, and data lakes, or when you want to quickly analyze and visualize your data. We’ve built our business on high-performing services like Amazon Aurora, Amazon DynamoDB, and Amazon Redshift, and this week, we announced several new capabilities to continue building on our performance innovations to date.
For our serverless, interactive query service, Amazon Athena, we announced a new integration with Apache Spark that enables you to spin up Spark workloads up to 75 times faster than other serverless Spark offerings. We also introduced a new feature called Elastic Clusters within our fully managed document database, Amazon DocumentDB, that enables customers to easily scale out or shard their data across multiple database instances.
To help our customers protect their data from potential compromises, we announced Amazon GuardDuty RDS Protection to intelligently detect potential threats for their data stored in Aurora, as well as a new open-source project that allows developers to safely use PostgreSQL extensions in their core databases without worrying about unintended security impacts.
Connecting data is critical for deeper insights
To get the most of your data, you need to combine data silos for deeper insights. However, connecting data across siloes typically requires complex extract, transform, and load (ETL) pipelines, which means creating a manual integration every time you want to ask a different question of your data or build a different ML model. This isn’t fast enough to keep up with the speed that businesses need to move today.
Zero ETL is the future. And we’ve been making strides in this zero-ETL future for several years by deepening integrations between our services. But this week, we’re getting closer to a zero-ETL future by announcing Aurora now supports zero-ETL integration with Amazon Redshift to bring transactional data in Aurora and the analytical capabilities in Amazon Redshift together.
We also announced a new auto-copy feature from Amazon Simple Storage Service (Amazon S3) to Amazon Redshift that removes the need for you to build and manage ETL pipelines whenever you want to use your data for analytics. And we’re not stopping here. With AWS, you can now connect to hundreds of data sources, from software as a service (SaaS) applications to on-premises data stores.
We’ll continue to build no zero-ETL capabilities into our services to help our customers easily analyze all their data, no matter where it resides.
Data governance unleashes innovation
Governance was historically used as a defensive measure, which meant locking down data in silos. But in reality, the right governance strategy helps you move and innovate faster with guardrails that give the right people access to your data, when and where they need it.
In addition to fine-grained access controls within AWS Lake Formation, this week we’re making it easier for customers to govern access and privileges within more of our data services with new capabilities announced in Amazon Redshift and Amazon SageMaker.
Our customers also told us they want an end-to-end strategy that enables them to govern their data across the entire data journey. That’s why this week we announced Amazon DataZone, a new data management service that helps you catalog, discover, analyze, share, and govern data across the organization.
When you properly manage secure access to your data, it can flow to the right places and connect the dots across siloed teams and departments.
Build with AWS
With the introduction of these new services and features this week, as well as our comprehensive set of data services, it’s important to remember that support is available as you build your end-to-end data strategy. In fact, we have an entire team at AWS, as well as an extensive network of partners to help our customers build data foundations that will meet their needs now—and well into the future.
For more information about re:Invent 2022, please visit our event page.
About the Author
 Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.
Swami Sivasubramanian is the Vice President of AWS Data and Machine Learning.