AWS Big Data Blog

Simplifying data processing at Capitec with Amazon Redshift integration for Apache Spark
This post is co-written with Preshen Goobiah and Johan Olivier from Capitec. Apache Spark is a widely-used open source distributed processing system renowned for handling large-scale data workloads. It finds frequent application among Spark developers working with Amazon EMR, Amazon SageMaker, AWS Glue and custom Spark applications. Amazon Redshift offers seamless integration with Apache Spark, […]

Create a modern data platform using the Data Build Tool (dbt) in the AWS Cloud
Building a data platform involves various approaches, each with its unique blend of complexities and solutions. A modern data platform entails maintaining data across multiple layers, targeting diverse platform capabilities like high performance, ease of development, cost-effectiveness, and DataOps features such as CI/CD, lineage, and unit testing. In this post, we delve into a case […]

Real-time streaming data top picks you cannot miss at AWS re:Invent 2023
This post will help you plan your re:Invent experience by highlighting the essential sessions on real-time streaming data and beyond that you shouldn’t miss. To attend these sessions, be sure to register for re:Invent and access the session catalog. Register now!

How Gilead used Amazon Redshift to quickly and cost-effectively load third-party medical claims data
This post was co-written with Rajiv Arora, Director of Data Science Platform at Gilead Life Sciences. Gilead Sciences, Inc. is a biopharmaceutical company committed to advancing innovative medicines to prevent and treat life-threatening diseases, including HIV, viral hepatitis, inflammation, and cancer. A leader in virology, Gilead historically relied on these drugs for growth but now […]
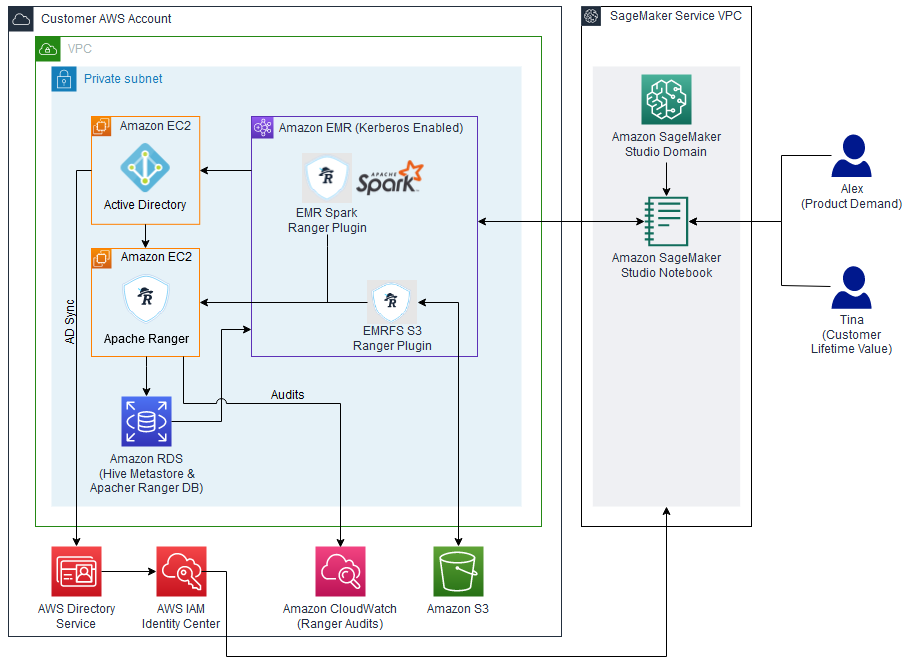
Implement fine-grained access control in Amazon SageMaker Studio and Amazon EMR using Apache Ranger and Microsoft Active Directory
In this post, we show how you can authenticate into SageMaker Studio using an existing Active Directory (AD), with authorized access to both Amazon S3 and Hive cataloged data using AD entitlements via Apache Ranger integration and AWS IAM Identity Center (successor to AWS Single Sign-On). With this solution, you can manage access to multiple SageMaker environments and SageMaker Studio notebooks using a single set of credentials. Subsequently, Apache Spark jobs created from SageMaker Studio notebooks will access only the data and resources permitted by Apache Ranger policies attached to the AD credentials, inclusive of table and column-level access.

Configure dynamic tenancy for Amazon OpenSearch Dashboards
Amazon OpenSearch Service securely unlocks real-time search, monitoring, and analysis of business and operational data for use cases like application monitoring, log analytics, observability, and website search. In this post, we talk about new configurable dashboards tenant properties. OpenSearch Dashboards tenants in Amazon OpenSearch Service are spaces for saving index patterns, visualizations, dashboards, and other […]

Connect your data for faster decisions with AWS
The most impactful data-driven insights come from connecting the dots between all your data sources—across departments, services, on-premises tools, and third-party applications. But typically, connecting data requires complex extract, transform, and load (ETL) pipelines, taking hours or days. That’s too slow for decision-making speed. ETL needs to be easier and sometimes eliminated. AWS is investing […]
Introducing Amazon MWAA support for Apache Airflow version 2.7.2 and deferrable operators
Today, we are announcing the availability of Apache Airflow version 2.7.2 environments and support for deferrable operators on Amazon MWAA. In this post, we provide an overview of deferrable operators and triggers, including a walkthrough of an example showcasing how to use them. We also delve into some of the new features and capabilities of Apache Airflow, and how you can set up or upgrade your Amazon MWAA environment to version 2.7.2.

Use IAM runtime roles with Amazon EMR Studio Workspaces and AWS Lake Formation for cross-account fine-grained access control
Amazon EMR Studio is an integrated development environment (IDE) that makes it straightforward for data scientists and data engineers to develop, visualize, and debug data engineering and data science applications written in R, Python, Scala, and PySpark. EMR Studio provides fully managed Jupyter notebooks and tools such as Spark UI and YARN Timeline Server via […]

Deploy Amazon QuickSight dashboards to monitor AWS Glue ETL job metrics and set alarms
No matter the industry or level of maturity within AWS, our customers require better visibility into their AWS Glue usage. Better visibility can lend itself to gains in operational efficiency, informed business decisions, and further transparency into your return on investment (ROI) when using the various features available through AWS Glue. As your company grows, […]