AWS Big Data Blog
What’s new in Amazon Redshift – 2021, a year in review
Amazon Redshift is the cloud data warehouse of choice for tens of thousands of customers who use it to analyze exabytes of data to gain business insights. Customers have asked for more capabilities in Redshift to make it easier, faster, and secure to store, process, and analyze all of their data. We announced Redshift in 2012 as the first cloud data warehouse to remove the complexity around provisioning, managing, and scaling data warehouses. Since then, we have launched capabilities such as Concurrency scaling, Spectrum, and RA3 nodes to help customers analyze all of their data and support growing analytics demands across all users in the organization. We continue to innovate with Redshift on our customers’ behalf and launched more than 50 significant features in 2021. This post covers some of those features, including use cases and benefits.
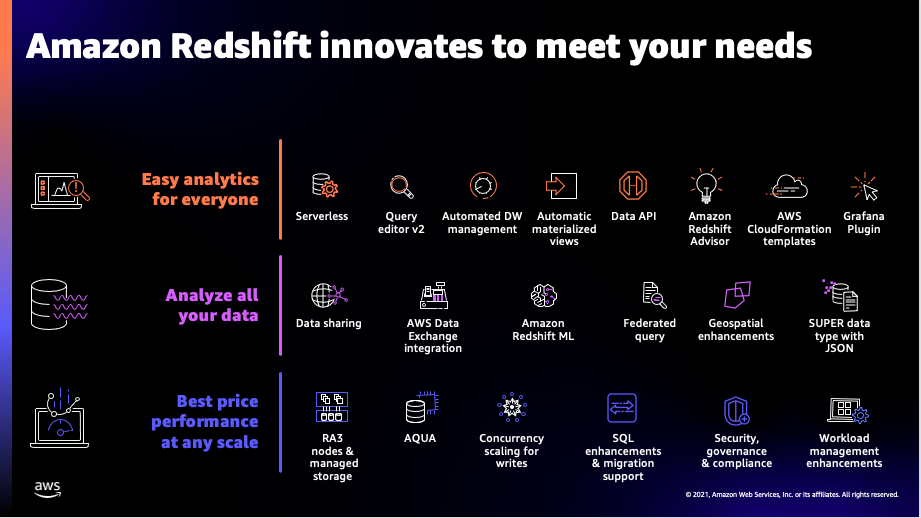
Working backwards from customer requirements, we are investing in Redshift to bring out new capabilities in three main areas:
- Easy analytics for everyone
- Analyze all of your data
- Performance at any scale
Customers told us that the data warehouse users in their organizations are expanding from administrators, developers, analysts, and data scientists to the Line of Business (LoB) users, so we continue to invest to make Redshift easier to use for everyone. Customers also told us that they want to break free from data silos and access data across their data lakes, databases, and data warehouses and analyze that data with SQL and machine learning (ML). So we continue to invest in letting customers analyze all of their data. And finally, customers told us that they want the best price performance for analytics at any scale from Terabytes to Petabytes of data. So we continue to bring out new capabilities for performance at any scale. Let’s dive into each of these pillars and cover the key capabilities that we launched in 2021.
Amazon Redshift key innovations
Redshift delivers easy analytics for everyone
Easy analytics for everyone requires a simpler getting-started experience, automated manageability, and visual user interfaces that make is easier, simpler, and faster for both technical and non-technical users to quickly get started, operate, and analyze data in a data warehouse. We launched new features such as Redshift Serverless (in preview), Query Editor V2, and automated materialized views (in preview), as well as enhanced the Data API in 2021 to make it easier for customers to run their data warehouses.
Redshift Serverless (in preview) makes it easy to run and scale analytics in seconds without having to provision and manage data warehouse clusters. The serverless option lets all users, including data analysts, developers, business users, and data scientists use Redshift to get insights from data in seconds by simply loading and querying data into the data warehouse. Customers can launch a data warehouse and start analyzing the data with the Redshift Serverless option through just a few clicks in the AWS Management Console. There is no need to choose node types, node count, or other configurations. Customers can take advantage of pre-loaded sample data sets along with sample queries to kick start analytics immediately. They can create databases, schemas, tables, and load their own data from their desktop, Amazon Simple Storage Service (S3), via Amazon Redshift data shares, or restore an existing Amazon Redshift provisioned cluster snapshot. They can also directly query data in open formats, such as Parquet or ORC, in their Amazon S3 data lakes, as well as data in their operational databases, such as Amazon Aurora and Amazon RDS. Customers pay only for what they use, and they can manage their costs with granular cost controls.
Redshift Query Editor V2 is a web-based tool for data analysts, data scientists, and database developers to explore, analyze, and collaborate on data in Redshift data warehouses and data lake. Customers can use Query Editor’s visual interface to create and browse schema and tables, load data, author SQL queries and stored procedures, and visualize query results with charts. They can share and collaborate on queries and analysis, as well a track changes with built in version control. Query Editor V2 also supports SQL Notebooks (in preview), which provides a new Notebook interface that lets users such as data analysts and data scientists author queries, organize multiple SQL queries and annotations on a single document, and collaborate with their team members by sharing Notebooks.

Amazon Redshift Query Editor V2
Customers have long used Amazon Redshift materialized views (MV) for precomputed result sets, based on an SQL query over one or more base tables to improve query performance, particularly for frequently used queries such as those in dashboards and reports. In 2021, we launched Automated Materialized View (AutoMV) in preview to improve the performance of queries (reduce the total execution time) without any user effort by automatically creating and maintaining materialized views. Customers told us that while MVs offer significant performance benefits, analyzing the schema, data, and workload to determine which queries might benefit from having an MV or which MVs are no longer beneficial and should be dropped requires knowledge, time, and effort. AutoMV lets Redshift continually monitor the cluster to identify candidate MVs and evaluates the benefits vs costs. It creates MVs that have high benefit-to-cost ratios, while ensuring existing workloads are not negatively impacted by this process. AutoMV continually monitors the system and will drop MVs that are no longer beneficial. All of these are transparent to users and applications. Applications such as dashboards benefit without any code change thanks to automatic query re-write, which lets existing queries benefit from MVs even when not explicitly referenced. Customers can also set the MVs to autorefresh so that MVs always have up-to-date data for added convenience.
Customers have also asked us to simplify and automate data warehouse maintenance tasks, such as schema or table design, so that they can get optimal performance out of their clusters. Over the past few years, we have invested heavily to automate these maintenance tasks. For example, Automatic Table Optimization (ATO) selects the best sort and distribution keys to determine the optimal physical layout of data to maximize performance. We’ve extended ATO to modify column compression encodings to achieve high performance and reduce storage utilization. We have also introduced various features, such as auto vacuum delete and auto analyze, over the past few years to make sure that customer data warehouses continue to operate at peak performance.
Data API, which launched in 2020, has also seen major enhancements, such as multi-statement query execution, support for parameters to develop reusable code, and availability in more regions in 2021 to make it easier for customers to programmatically access data in Redshift. Data API lets Redshift enable customers to painlessly access data with all types of traditional, cloud-native, and containerized, serverless web services-based applications and event-driven applications. It simplifies data access, ingest, and egress from programming languages and platforms supported by the AWS SDK, such as Python, Go, Java, Node.js, PHP, Ruby, and C++. The Data API eliminates the need for configuring drivers and managing database connections. Instead, customers can run SQL commands to an Amazon Redshift cluster by simply calling a secured API endpoint provided by the Data API. The Data API takes care of managing database connections and buffering data. The Data API is asynchronous, so results can be retrieved later and are stored for 24 hours.
Finally in our easy analytics for everyone pillar, in 2021 we launched the Grafana Redshift Plugin to help customers gain a deeper understanding of their cluster’s performance. Grafana is a popular open-source tool for running analytics and monitoring systems online. The Grafana Redshift Plugin lets customers query system tables and views for the most complete set of operational metrics on their Redshift cluster. The Plugin is available in the Open Source Grafana repository, as well as in our Amazon Managed Grafana service. We also published a default in-depth operational dashboard to take advantage of this feature.
Redshift makes it possible for customers to analyze all of their data
Redshift gives customers the best of both data lakes and purpose-built data stores, such as databases and data warehouses. It enables customers to store any amount of data, at low cost, and in open, standards-based data formats such as parquet and JSON in data lakes, and run SQL queries against it without loading or transformations. Furthermore, it lets customers run complex analytic queries with high performance against terabytes to petabytes of structured and semi-structured data, using sophisticated query optimization, columnar storage on high-performance storage, and massively parallel query execution. Redshift lets customers access live data from the transactional databases as part of their business intelligence (BI) and reporting applications to enable operational analytics. Customers can break down data silos by seamlessly querying data in the data lakes, data warehouses, and databases; empower their teams to run analytics and ML using their preferred tool or technique; and manage who has access to data with the proper security and data governance controls. We launched new features in 2021, such as Data Sharing, AWS Data Exchange integration, and Redshift ML, to make it easier for customers to analyze all of their data.
Amazon Redshift data sharing lets customers extend the ease of use, performance, and cost benefits that Amazon Redshift offers in a single cluster to multi-cluster deployments while being able to share data. It enables instant, granular, and fast data access across Amazon Redshift clusters without the need to copy or move data around. Data sharing provides live access to data so that your users always see the most up-to-date and consistent information as it’s updated in the data warehouse. Customers can securely share live data with Amazon Redshift clusters in the same or different AWS accounts within the same region or across regions. Data sharing features several performance enhancements, including result caching and concurrency scaling, which allow customers to support a broader set of analytics applications and meet critical performance SLAs when querying shared data. Customers can use data sharing for use cases such as workload isolation and offer chargeability, as well as provide secure and governed collaboration within and across teams and external parties.
Customers also asked us to help them with internal or external data marketplaces so that they can enable use cases such as data as a service and onboard 3rd-party data. We launched the public preview of AWS Data Exchange for Amazon Redshift, a new feature that enables customers to find and subscribe to third-party data in AWS Data Exchange that they can query in an Amazon Redshift data warehouse in minutes. Data providers can list and offer products containing Amazon Redshift data sets in the AWS Data Exchange catalog, granting subscribers direct, read-only access to the data stored in Amazon Redshift. This feature empowers customers to quickly query, analyze, and build applications with these third-party data sets. AWS Data Exchange for Amazon Redshift lets customers combine third-party data found on AWS Data Exchange with their own first-party data in their Amazon Redshift cloud data warehouse, with no ETL required. Since customers are directly querying provider data warehouses, they can be certain that they are using the latest data being offered. Additionally, entitlement, billing, and payment management are all automated: access to Amazon Redshift data is granted when a data subscription starts and is removed when it ends, invoices are automatically generated, and payments are automatically collected and disbursed through AWS Marketplace.
Customers also asked for our help to make it easy to train and deploy ML models such as prediction, natural language processing, object detection, and image classification directly on top of the data in purpose-built data stores without having to perform complex data movement or learn new tools. We launched Redshift ML earlier this year to enable customers to create, train, and deploy ML models using familiar SQL commands. Amazon Redshift ML lets customers leverage Amazon SageMaker, a fully managed ML service, without moving their data or learning new skills. Furthermore, Amazon Redshift ML powered by Amazon SageMaker lets customers use SQL statements to create and train ML models from their data in Amazon Redshift, and then use these models for use cases such as churn prediction and fraud risk scoring directly in their queries and reports. Amazon Redshift ML automatically discovers the best model and tunes it based on training data using Amazon SageMaker Autopilot. SageMaker Autopilot chooses between regression, binary, or multi-class classification models. Alternatively, customers can choose a specific model type such as Xtreme Gradient Boosted tree (XGBoost) or multilayer perceptron (MLP), a problem type like regression or classification, and preprocessors or hyperparameters. Amazon Redshift ML uses customer parameters to build, train, and deploy the model in the Amazon Redshift data warehouse. Customers can obtain predictions from these trained models using SQL queries as if they were invoking a user defined function (UDF), and leverage all of the benefits of Amazon Redshift, including massively parallel processing capabilities. Customers can also import their pre-trained SageMaker Autopilot, XGBoost, or MLP models into their Amazon Redshift cluster for local inference. Redshift ML supports both supervised and unsupervised ML for advanced analytics use cases ranging from forecasting to personalization.
Customers want to combine live data from operational databases with the data in Amazon Redshift data warehouse and the data in Amazon S3 data lake environment to get unified analytics views across all of the data in the enterprise. We launched Amazon Redshift federated query to let customers incorporate live data from the transactional databases as part of their BI and reporting applications to enable operational analytics. The intelligent optimizer in Amazon Redshift pushes down and distributes a portion of the computation directly into the remote operational databases to help speed up performance by reducing data moved over the network. Amazon Redshift complements subsequent execution of the query by leveraging its massively parallel processing capabilities for further speed up. Federated query also makes it easier to ingest data into Amazon Redshift by letting customers query operational databases directly, applying transformations on the fly, and loading data into the target tables without requiring complex ETL pipelines. In 2021, we added support for Amazon Aurora MySQL and Amazon RDS for MySQL databases in addition to the existing Amazon Aurora PostgreSQL and Amazon RDS for PostgreSQL databases for federated query to enable customers to access more data sources for richer analytics.
Finally in our analyze all your data pillar in 2021, we added data types such as SUPER, GEOGRAPHY, and VARBYTE to enable customers to store semi-structured data natively in the Redshift data warehouse so that they can analyze all of their data at scale and with performance. The SUPER data type lets customers ingest and store JSON and semi-structured data in their Amazon Redshift data warehouses. Amazon Redshift also includes support for PartiQL for SQL-compatible access to relational, semi-structured, and nested data. Using the SUPER data type and PartiQL in Amazon Redshift, customers can perform advanced analytics that combine classic structured SQL data (such as string, numeric, and timestamp) with the semi-structured SUPER data (such as JSON) with superior performance, flexibility, and ease-of-use. The GEOGRAPHY data type builds on Redshift’s support of spatial analytics, opening-up support for many more third-party spatial and GIS applications. Moreover, it adds to the GEOMETRY data type and over 70 spatial functions that are already available in Redshift. The GEOGRAPHY data type is used in queries requiring higher precision results for spatial data with geographic features that can be represented with a spheroid model of the Earth and referenced using latitude and longitude as a spatial coordinate system. VARBYTE is a variable size data type for storing and representing variable-length binary strings.
Redshift delivers performance at any scale
Since we announced Amazon Redshift in 2012, performance at any scale has been a foundational tenet for us to deliver value to tens of thousands of customers who trust us every day to gain business insights from their data. Our customers span all industries and sizes, from startups to Fortune 500 companies, and we work to deliver the best price performance for any use case. Over the years, we have launched features such as dynamically adding cluster capacity when you need it with concurrency scaling, making sure that you use cluster resources efficiently with automatic workload management (WLM), and automatically adjusting data layout, distribution keys, and query plans to provide optimal performance for a given workload. In 2021, we launched capabilities such as AQUA, concurrency scaling for writes, and further enhancements to RA3 nodes to continue to improve Redshift’ price performance.
We introduced the RA3 node types in 2019 as a technology that allows the independent scaling of compute and storage. We also described how customers, including Codeacademy, OpenVault, Yelp, and Nielsen, have taken advantage of Amazon Redshift RA3 nodes with managed storage to scale their cloud data warehouses and reduce costs. RA3 leverages Redshift Managed Storage (RMS) as its durable storage layer which allows near-unlimited storage capacity where data is committed back to Amazon S3. This enabled new capabilities, such as Data Sharing and AQUA, where RMS is used as a shared storage across multiple clusters. RA3 nodes are available in three sizes (16XL, 4XL, and XLPlus) to balance price/performance. In 2021, we launched single node RA3 XLPlus clusters to help customers cost-effectively migrate their smaller data warehouse workloads to RA3s and take advantage of better price performance. We also introduced a self-service DS2 to RA3 RI migration capability that lets RIs be converted at a flat cost between equivalent node types.
AQUA (Advanced Query Accelerator) for Amazon Redshift is a new distributed and hardware-accelerated cache that enables Amazon Redshift to run an order of magnitude faster than other enterprise cloud data warehouses by automatically boosting certain query types. AQUA uses AWS-designed processors with AWS Nitro chips adapted to speed up data encryption and compression, and custom analytics processors, implemented in FPGAs, to accelerate operations such as scans, filtering, and aggregation. AQUA is available with the RA3.16xlarge, RA3.4xlarge, or RA3.xlplus nodes at no additional charge and requires no code changes.
Concurrency Scaling was launched in 2019 to handle spiky and unpredictable read workloads without having to pre-provision any capacity. Redshift offers one hour of free Concurrency Scaling for every 24 hours of usage that your main cluster is running. It also offers cost controls to monitor and limit your usage and associated costs for Concurrency Scaling. In addition to read queries, supporting write queries has been a big ask from customers to support ETL workloads. In 2021, we launched Redshift Concurrency Scaling write queries support in preview with common operations such as INSERT, DELETE, UPDATE, and COPY to handle unpredictable spikes in ETL workloads. If you are currently using Concurrency Scaling, this new capability is automatically enabled in your cluster. You can monitor your Concurrency Scaling usage using the Amazon Redshift Console and get alerts on any usage exceeding your defined limits. You can also create, modify, and delete usage limits programmatically by using the AWS Command Line Interface (CLI) and AWS API.
Finally we continue to ensure that AWS has comprehensive security capabilities to satisfy the most demanding requirements, and Amazon Redshift continues to provides data security out-of-the-box at no extra cost. We introduced new security features in 2021, such as cross-VPC support and default IAM roles, to continue to make Redshift more secure for customer workloads.
Summary
When it comes to making it easier, simpler, and faster for customers to analyze all of their data, velocity matters and we are innovating at a rapid pace to bring new capabilities to Redshift. We continue to make Redshift features available in more AWS regions worldwide to make sure that all customers have access to all capabilities. We have covered the key features above and the complete list is available here. We look forward to how you will use some of these capabilities to continue innovating with data and analytics.
About the Author
 Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift & AQUA at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.
Manan Goel is a Product Go-To-Market Leader for AWS Analytics Services including Amazon Redshift & AQUA at AWS. He has more than 25 years of experience and is well versed with databases, data warehousing, business intelligence, and analytics. Manan holds a MBA from Duke University and a BS in Electronics & Communications engineering.