AWS Compute Blog
Running Web Applications on Amazon EC2 Spot Instances
This post is contributed by Isaac Vallhonrat, Sr. EC2 Spot Specialist SA
Amazon EC2 Spot Instances allow customers to save up to 90% compared to On-Demand pricing by leveraging spare EC2 capacity. Spot Instances are a perfect fit for fault tolerant workloads that are flexible to run on multiple instance types such as batch jobs, code builds, load tests, containerized workloads, web applications, big data clusters, and High Performance Computing clusters. In this blog post, I walk you through how-to and best practices to run web applications on Spot Instances, so you can benefit from the scale and savings that they provide.
As Spot Instances are interruptible, your web application should be stateless, fault tolerant, loosely coupled, and rely on external data stores for persistent data, like Amazon ElastiCache, Amazon RDS, Amazon DynamoDB, etc.
Spot Instances recap
While Spot Instances have been around since 2009, recent updates and service integrations have made them easier than ever to integrate with your workloads. Before I get into the details of how to use them to host a web application, here is a brief recap of how Spot Instances work:
First, Spot Instances are a purchasing option within EC2. There is no difference in hardware when compared to On-Demand or Reserved Instances. The only difference is that these instances can be reclaimed with a two-minute notice if EC2 needs the capacity back.
A set of unused EC2 instances with the same instance type, operating system, and Availability Zone is a Spot capacity pool. Spot Instance pricing is set by Amazon EC2 and adjusts gradually based on long-term trends in supply and demand of EC2 instances in each pool. You can expect Spot pricing to be stable over time, meaning no sudden spikes or swings. You can view historical pricing data for the last three months in both the EC2 console and via the API. The following image is an example of the pricing history for m5.xlarge instances in the N. Virginia (us-east-1).
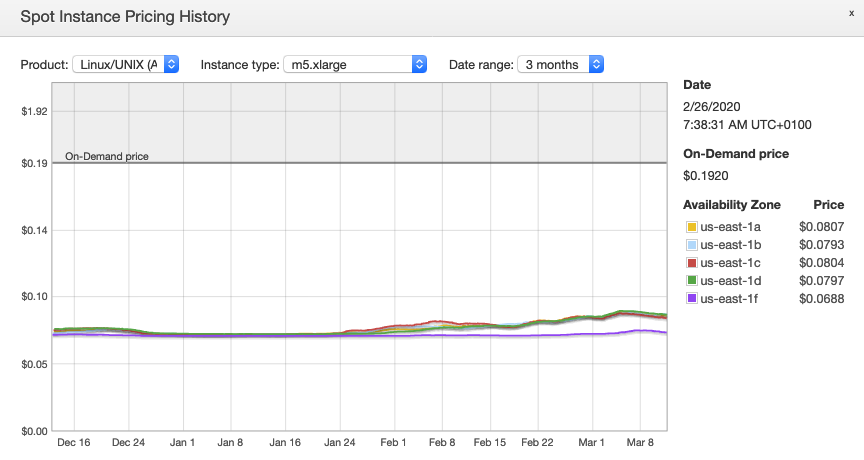
Spot Instance pricing history for an m5.xlarge Linux/UNIX instance in us-east-1. Price changes independently for each Availability Zone and in small increments over time based on long term supply and demand.
As each capacity pool is independent from each other, I recommend you spread the fleet of instances that power your workload across multiple Availability Zones (AZs) and be flexible to use multiple instance types. This way, you effectively increase the amount of spare capacity you can use to launch Spot Instances and are able to replace interrupted instances with instances from other pools.
The best way to adhere to Spot Instance flexibility best practices and managing your fleet of instances is using an Amazon EC2 Auto Scaling group. This allows you to combine multiple instance types and purchase options. Once you identify a list of suitable instance types for your workload, you can use Auto Scaling features to launch a combination of On-Demand and Spot Instances from optimal Spot Instance pools in each Availability Zone.
Stateless web applications are a natural fit for Spot Instances as they are fault tolerant, used to handle interruptions through scale-in events in an Auto Scaling group, and commonly run across multiple Availability Zones. It’s also normally easy to implement instance type flexibility on web applications, so they tap on Spot Instance capacity from multiple pools.
Identifying suitable instance types for your web application
Being instance type flexible is key to being successful with Spot Instances. At the time of this writing, AWS provides more than 270 instance types, so it’s likely that your web application can run on multiple of them. For example, if your application runs on the m5.xlarge instance type, it can also run on the m5d.xlarge instance type as it is the same instance type, but with local SSDs. Also, running your application on the r5.xlarge or r5d.xlarge performs similarly since they use the same processor family. Instead, your application runs on an instance with more memory and you benefit from the savings Spot Instances provide.
You may be able to qualify additional similarly-sized instance types from other families or generations, like the AMD-based variants m5a.xlarge and r5a.xlarge, or the higher bandwidth variants m5n.xlarge and r5n.xlarge. These may present some performance differences compared to other types due to their hardware and/or the virtualization system. However, Application Load Balancer has mechanisms in place to spread the load across your instances according to the number of outstanding requests they are processing. This means, instances handling longer requests or that have lower processing power are not overloaded. This allows you to acquire capacity from even more Spot capacity pools regardless of hardware differences. Later in the blog post, I dive into the details on the load balancing mechanisms.
Configure your Auto Scaling group
Now that you have qualified multiple instance types to run your web application, you need to create an EC2 Auto Scaling group.
The first step is to create a Launch Template where you specify configuration for your fleet of instances including the AMI, Security Groups, Tags, user data scripts, etc. You configure a single instance type on the template, here you configure the instance type you commonly use to run your web application. Also, do not mark the Request Spot Instances checkbox on the template. You configure multiple instance types and the Spot Instance settings when configuring the Auto Scaling group. Here’s my Launch Template:
Launch templates console
Now, go to the EC2 Auto Scaling console to create an Auto Scaling group. In the wizard, select the launch template you created and then click next. Then, on the second step of the wizard, select Combine purchase options and instance types. You can see the configuration options in the following image.
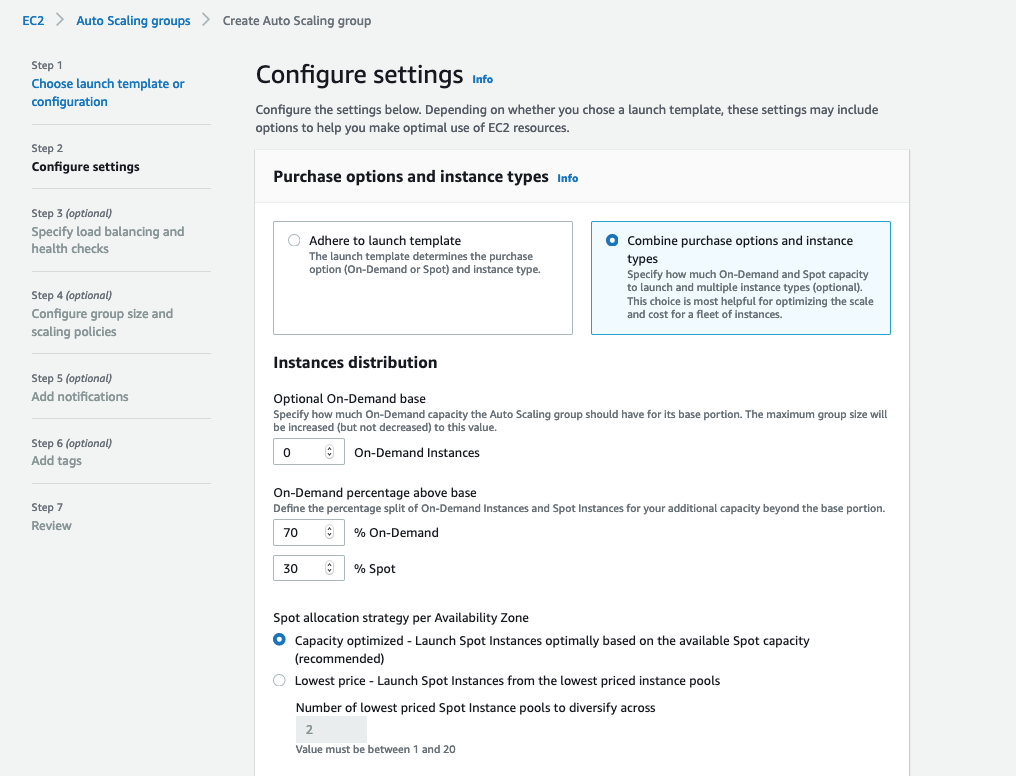
Combine purchase options and instance types configuration.
Here is a detailed look at the configuration details:
- Optional On-Demand Base: This parameter specifies a baseline of On-Demand Instances within your Auto Scaling group. This is also handy if you have Reserved Instances or Savings Plans to cover your compute baseline, since On-Demand Instances apply towards your Savings Plans or the instances matching your reservation are billed as Reserved Instances.
- On-Demand percentage above base: Once the size of the Auto Scaling group grows over the (optional) On-Demand base capacity, this parameter defines the percentage of instances that are On-Demand and Spot Instances. The default settings are a good starting point, set at 70% On-Demand and 30% Spot. You can adjust these percentages as suitable for your workload.
- Spot Allocation Strategy per Availability Zone: This defines the logic that Auto Scaling uses to select which instance type to launch in each Availability Zone when launching Spot Instances. The possible Spot allocation strategies are:
- Capacity Optimized: This strategy allocates your instances from the Spot Instance pool with optimal capacity for the number of instances that are launching. This is the default selection and the recommended one, as launching from capacity pools with optimal capacity can lower the chance of interruption. Every time EC2 Auto Scaling scales out, the strategy is evaluated, so as your Auto Scaling group scales out and scales in, your instances are recycled and you make use of Spot Instances in the optimal pools.
- Lowest price: This strategy allocates your instances from the number (N) of Spot Instance pools that you specify and from the pools with the lowest price per unit at the time of fulfillment.
Next, you choose your instance types from the Instance Types section of the wizard. Here, there is a primary instance type inherited from your Launch Template. The console then automatically populates a list of same size instance types across other families and generations that could also fit your web application requirements. You can add or remove instance types as you see fit.
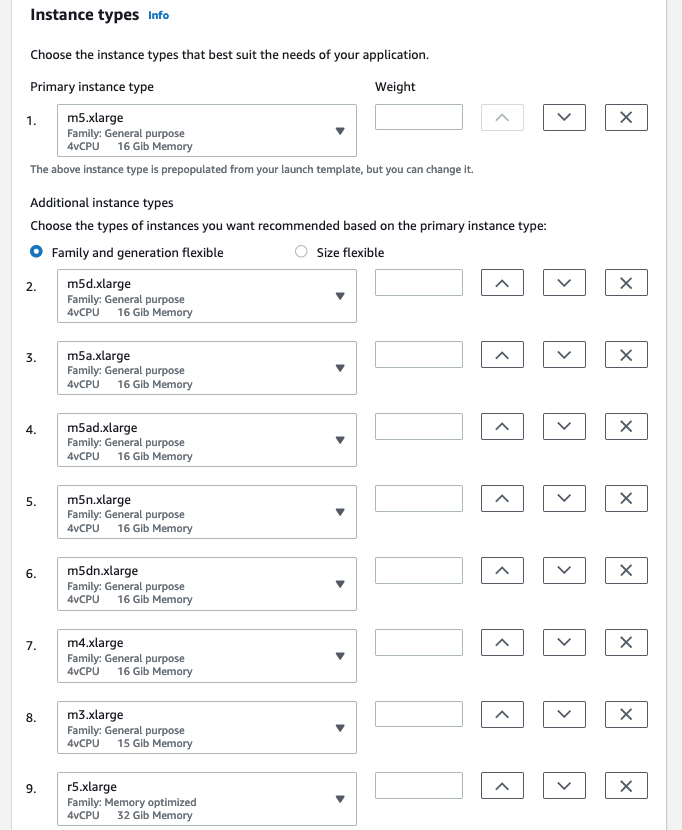
Selection of instance types
Note: There is an option to combine instance types of different sizes which is very helpful for queue worker nodes and similar workloads. We won’t cover this in this blog post as it is not relevant for web applications. You can read more about this feature here.
Once you select your instance types, your Auto Scaling group uses the configured Spot Instance allocation strategy to decide which Spot Instance types to launch on each Availability Zone. By specifying multiple instance types, EC2 Auto Scaling replenishes capacity from other Spot Instance pools applying your configured allocation strategy if some of your instances get interrupted. This maintains the size of your fleet and keeps your service available.
For the On-Demand part of your Auto Scaling group, the allocation strategy is prioritized. This means that EC2 Auto Scaling launches the primary instance type, and moves to the next types in the order you selected, in the unlikely event it cannot launch the capacity. If you have Reserved Instances to cover your compute baseline, set the instance type you reserved as the primary instance type in your Auto Scaling group, so the On-Demand Instances get the reservation discounts. You can learn more about how Reserved Instances are applied here.
After completing this step, complete the Auto Scaling group creation wizard, and you can move on to set up your Application Load Balancer.
Load balancing with Application Load Balancer
To balance the load across the fleet of instances running your web application you use an Application Load Balancer (ALB). EC2 Auto Scaling groups are fully integrated with ALB and Target Groups that manage the fleet of instances fronted by ALB.
Target groups are set up by default with a deregistration delay of 300 seconds. This means that when EC2 Auto Scaling needs to remove an instance out of the fleet, it first puts the instance in draining state, informs ALB to stop sending new requests to it, and allows the configured time for in-flight requests to complete before the instance is finally deregistered. This way, removing an instance from the fleet is not perceptible to your end users.
As Spot Instances are interrupted with a 2 minute warning, you need to adjust this setting to a slightly lower time. Recommended values are 90 seconds or less. This allows time for in-flight requests to complete and gracefully close existing connections before the instance is interrupted.
At the time of this writing, EC2 Auto Scaling is not aware of Spot Instance interruptions and does not trigger draining automatically when a Spot Instance is going to be interrupted. However, you can put the instance in draining state by catching the interruption notice and calling the EC2 Auto Scaling API. I cover this in more detail in the next section.
Target Groups allow you to configure a routing algorithm, which by default is Round Robin. As with Spot Instances you combine multiple instance types in your fleet, your web application may see some performance differences if they use different hardware and in some cases a different virtualization platform (Xen for the older generation instances and AWS Nitro for the newer ones). While the impact to response time may be negligible to the end user, you need to ensure your instances handle load fairly accounting for the processing power differences of each instance type.
With the Least Outstanding Requests load balancing algorithm, instead of distributing the requests across your fleet in a round-robin fashion, as a new request comes in, the load balancer sends it to the target with the least number of outstanding requests. This way backend instances with lower processing capabilities or processing long-standing requests are not burdened with more requests and the load is spread evenly across targets. This also helps the new targets effectively take load from overloaded targets.
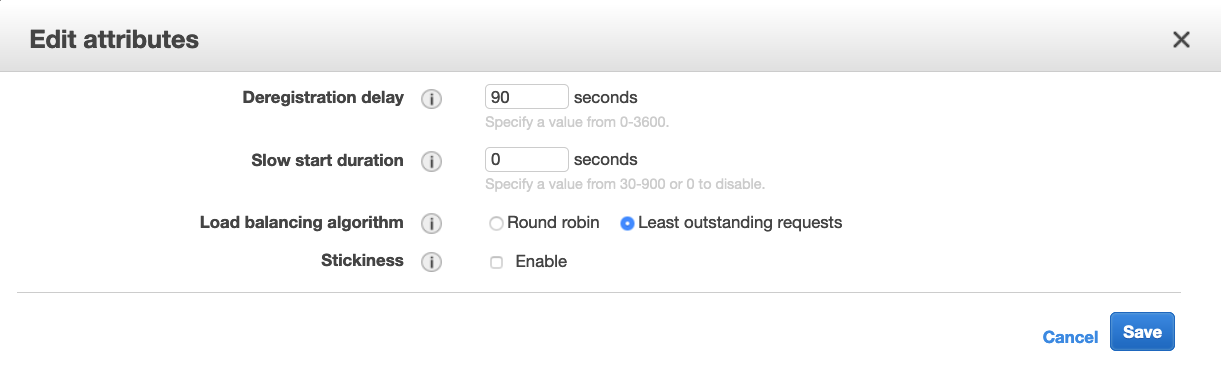
ALB Target group attribute configuration.
These settings can be configured on the Target Groups section of the EC2 Console and editing the attributes of your target group.
Your architecture will look like the following image.
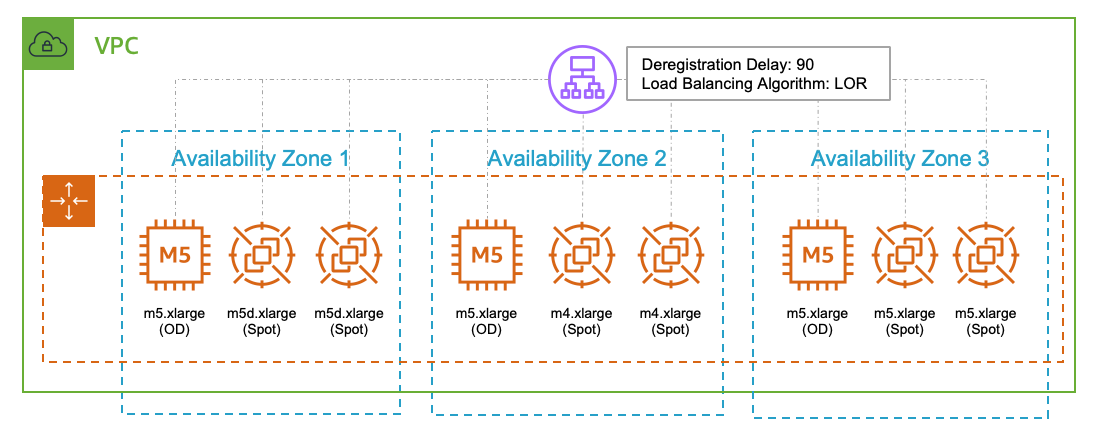
Stateless web application hosted on a combination of On-Demand and Spot Instances
Leveraging Instance Termination Notices for graceful termination
When a Spot Instance is going to be interrupted, EC2 triggers a Spot Instance interruption notice that is presented via the EC2 Metadata endpoint on the instance. It can also be caught by an Amazon EventBridge rule, for example, trigger an AWS Lambda function. You can find the specific documentation here.
By catching the interruption notice, you can take actions to gracefully take the instance out of the fleet without impacting your end users. For example, stop receiving new requests from the Load Balancer, allowing in-flight requests to finish and launch replacement capacity.
Below is a sample Spot Instance Interruption Notice caught by Amazon EventBridge:
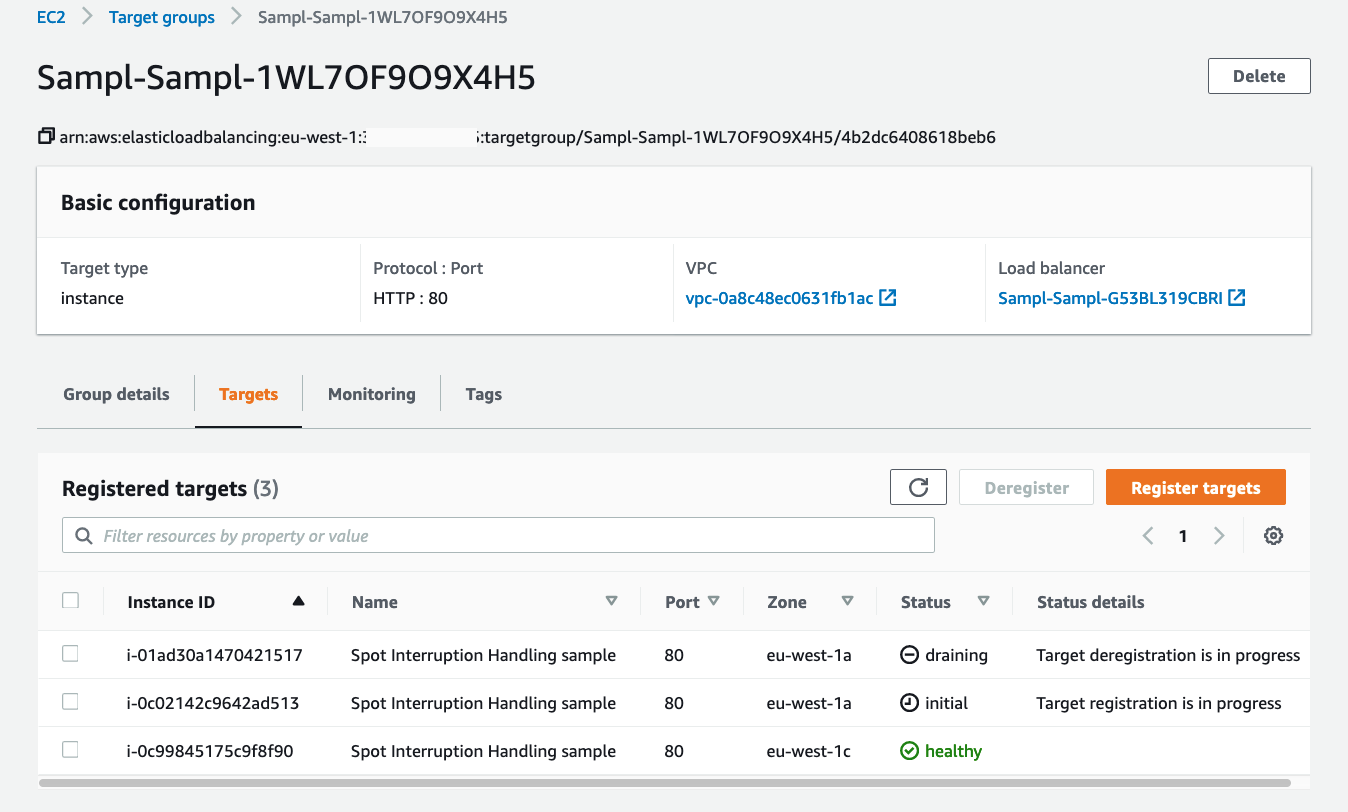
Target Group console showing instance draining.
Also, if you set the ShouldDecrementDesiredCapacity parameter of the API call to False, EC2 Auto Scaling attempts to launch replacement Spot Instance capacity according to your instance type selection and allocation strategy. Below is an example code snippet calling the Auto Scaling API using Python Boto3.
In some cases, you may also want to take actions at the operating system level when a Spot Instance is going to be interrupted. For example, you may want to gracefully stop your application so it closes open connections to a database, deregister agents running on the instance or other clean-up activities. You can leverage AWS Systems Manager Run Command to invoke commands on the instance that is going to be interrupted to perform these actions.
You may also want to delay the execution of commands to capitalize on the two minute warning. As a first step, you can check the instance termination time on the instance metadata and wait, for example, until 30 seconds before the interruption. Then, gracefully stop your application and issue other termination commands. Note that there are no charges for using Run Command (limits apply) and the API call is asynchronous so it doesn’t hold your Lambda function running.
Note: To use Run Command you must have the AWS Systems Manager agent running on your instance and meet a set of pre-requisites, like configuring an IAM instance profile. You can find more information here.
We provide you with a sample solution that handles all the steps outlined above here that you can easily deploy on your AWS account.
The sample solution also allows you to optionally execute commands upon Spot Instance interruption by creating an AWS Systems Manager parameter in Parameter Store specific to each Auto Scaling group with the commands you want to run, so you can easily customize termination commands to the needs of each application. You can find detailed configuration instructions in the README.md file. The high-level architecture of this solution is detailed below:
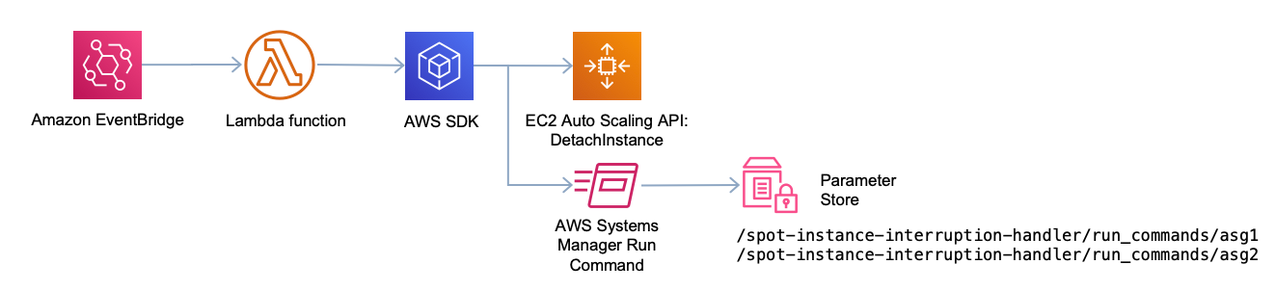
Serverless architecture to handle Spot Instance interruptions
Tying it all together
Now, that I covered all the relevant features to run web applications on Spot Instances, let’s put them all together and summarize:
- Using mixed instance types and purchase options in EC2 Auto Scaling groups you can configure a combination of On-Demand and Spot Instances. Leverage this feature to configure multiple instance types to run your web application on Spot Instances, so you can leverage unused capacity from multiple Spot capacity pools and replace interrupted instances.
- Using the capacity-optimized Spot Instance allocation strategy you can launch Spot Instances from your instance type selection based on the most available Spot Instance capacity pools. This reduces the chances of interruptions. Auto Scaling then replenishes Spot Instance capacity from the optimal pools if some of your instances are interrupted as Spot Instance capacity fluctuates.
- With Application Load Balancer you can adjust the deregistration delay of your Target Group to a slightly lower time than the Spot Instance termination notice time (e.g. 90 seconds), so when an instance is going to be interrupted, you stop sending new requests to it and leverage the notice time to let in-flight requests complete and avoid impact to your end users. You can also configure the Least Outstanding Requests load balancing algorithm in your ALB Target Group so the load is distributed evenly across your fleet accounting for differences in processing power for different instance families.
- You can leverage Amazon EventBridge, AWS Lambda and AWS Systems Manager Run Command to take interruption handling actions like put the instance in draining state, request EC2 Auto Scaling to launch a replacement instance and run commands to gracefully shutdown your application or trigger clean-up activities. You can also subscribe an SNS topic or other Lambda functions to the interruption event for alarming, logging or other purposes.
I hope you found this blog post useful, and if you are not using Spot Instances to run your stateless web applications today, I encourage you to try them to get the cost savings and scale they provide.