Artificial Intelligence
Automate caption creation and search for images at enterprise scale using generative AI and Amazon Kendra
Amazon Kendra is an intelligent search service powered by machine learning (ML). Amazon Kendra reimagines search for your websites and applications so your employees and customers can easily find the content they are looking for, even when it’s scattered across multiple locations and content repositories within your organization.
Amazon Kendra supports a variety of document formats, such as Microsoft Word, PDF, and text from various data sources. In this post, we focus on extending the document support in Amazon Kendra to make images searchable by their displayed content. Images can often be searched using supplemented metadata such as keywords. However, it takes a lot of manual effort to add detailed metadata to potentially thousands of images. Generative AI can be helpful in generating the metadata automatically. By generating textual captions, the Generative AI caption predictions offer descriptive metadata for images. The Amazon Kendra index can then be enriched with the generated metadata during document ingestion to enable searching the images without any manual effort.
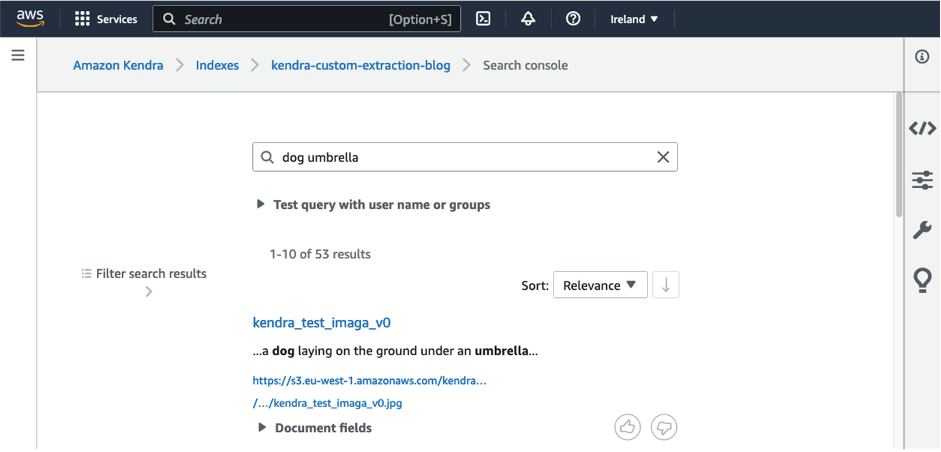
As an example, a Generative AI model can be used to generate a textual description for the following image as “a dog laying on the ground under an umbrella” during document ingestion of the image.

An object recognition model can still detect keywords such as “dog” and “umbrella,” but a Generative AI model offers deeper understanding of what is represented in the image by identifying that the dog lies under the umbrella. This helps us build more refined searches in the image search process. The textual description is added as metadata to an Amazon Kendra search index via an automated custom document enrichment (CDE). Users searching for terms like “dog” or “umbrella” will then be able to find the image, as shown in the following screenshot.
In this post, we show how to use CDE in Amazon Kendra using a Generative AI model deployed on Amazon SageMaker. We demonstrate CDE using simple examples and provide a step-by-step guide for you to experience CDE in an Amazon Kendra index in your own AWS account. It allows users to quickly and easily find the images they need without having to manually tag or categorize them. This solution can also be customized and scaled to meet the needs of different applications and industries.
Image captioning with Generative AI
Image description with Generative AI involves using ML algorithms to generate textual descriptions of images. The process is also known as image captioning, and operates at the intersection of computer vision and natural language processing (NLP). It has applications in areas where data is multi-modal such as ecommerce, where data contains text in the form of metadata as well as images, or in healthcare, where data could contain MRIs or CT scans along with doctor’s notes and diagnoses, to name a few use cases.
Generative AI models learn to recognize objects and features within the images, and then generate descriptions of those objects and features in natural language. The state-of-the-art models use an encoder-decoder architecture, where the image information is encoded in the intermediate layers of the neural network and decoded into textual descriptions. These can be considered as two distinct stages: feature extraction from images and textual caption generation. In the feature extraction stage (encoder), the Generative AI model processes the image to extract relevant visual features, such as object shapes, colors, and textures. In the caption generation stage (decoder), the model generates a natural language description of the image based on the extracted visual features.
Generative AI models are typically trained on vast amounts of data, which make them suitable for various tasks without additional training. Adapting to custom datasets and new domains is also easily achievable through few-shot learning. Pre-training methods allow multi-modal applications to be easily trained using state-of-the-art language and image models. These pre-training methods also allow you to mix and match the vision model and language model that best fits your data.
The quality of the generated image descriptions depends on the quality and size of the training data, the architecture of the Generative AI model, and the quality of the feature extraction and caption generation algorithms. Although image description with Generative AI is an active area of research, it shows very good results in a wide range of applications, such as image search, visual storytelling, and accessibility for people with visual impairments.
Use cases
Generative AI image captioning is useful in the following use cases:
- Ecommerce – A common industry use case where images and text occur together is retail. Ecommerce in particular stores vast amounts of data as product images along with textual descriptions. The textual description or metadata is important to ensure that the best products are displayed to the user based on the search queries. Moreover, with the trend of ecommerce sites obtaining data from 3P vendors, the product descriptions are often incomplete, amounting to numerous manual hours and huge overhead resulting from tagging the right information in the metadata columns. Generative-AI-based image captioning is particularly useful for automating this laborious process. Fine-tuning the model on custom fashion data such as fashion images along with text describing the attributes of fashion products can be used to generate metadata that then improves a user’s search experience.
- Marketing – Another use case of image search is digital asset management. Marketing firms store vast amounts of digital data that needs to be centralized, easily searchable, and scalable enabled by data catalogs. A centralized data lake with informative data catalogs would reduce duplication efforts and enable wider sharing of creative content and consistency between teams. For graphic design platforms popularly used for enabling social media content generation, or presentations in corporate settings, a faster search could result in an improved user experience by rendering the correct search results for the images that users want to look for and enabling users to search using natural language queries.
- Manufacturing – The manufacturing industry stores a lot of image data like architecture blueprints of components, buildings, hardware, and equipment. The ability to search through such data enables product teams to easily recreate designs from a starting point that already exists and eliminates a lot of design overhead, thereby speeding up the process of design generation.
- Healthcare – Doctors and medical researchers can catalog and search through MRIs and CT scans, specimen samples, images of the ailment such as rashes and deformities, along with doctor’s notes, diagnoses, and clinical trials details.
- Metaverse or augmented reality – Advertising a product is about creating a story that users can imagine and relate to. With AI-powered tools and analytics, it has become easier than ever to build not just one story but customized stories to appear to end-users’ unique tastes and sensibilities. This is where image-to-text models can be a game changer. Visual storytelling can assist in creating characters, adapting them to different styles, and captioning them. It can also be used to power stimulating experiences in the metaverse or augmented reality and immersive content including video games. Image search enables developers, designers, and teams to search their content using natural language queries, which can maintain consistency of content between various teams.
- Accessibility of digital content for blind and low vision – This is primarily enabled by assistive technologies such as screenreaders, Braille systems that allow touch reading and writing, and special keyboards for navigating websites and applications across the internet. Images, however, need to be delivered as textual content that can then be communicated as speech. Image captioning using Generative AI algorithms is a crucial piece for redesigning the internet and making it more inclusive by providing everyone a chance to access, understand, and interact with online content.
Model details and model fine-tuning for custom datasets
In this solution, we take advantage of the vit-gpt2-image-captioning model available from Hugging Face, which is licensed under Apache 2.0 without performing any further fine-tuning. Vit is a foundational model for image data, and GPT-2 is a foundational model for language. The multi-modal combination of the two offers the capability of image captioning. Hugging Face hosts state-of-the-art image captioning models, which can be deployed in AWS in a few clicks and offer simple-to-deploy inference endpoints. Although we can use this pre-trained model directly, we can also customize the model to fit domain-specific datasets, more data types such as video or spatial data, and unique use cases. There are several Generative AI models where some models perform best with certain datasets, or your team might already be using vision and language models. This solution offers the flexibility of choosing the best-performing vision and language model as the image captioning model through straightforward replacement of the model we have used.
For customization of the models to unique industry applications, open-source models available on AWS through Hugging Face offer several possibilities. A pre-trained model can be tested for the unique dataset or trained on samples of the labeled data to fine-tune it. Novel research methods also allow any combination of vision and language models to be combined efficiently and trained on your dataset. This newly trained model can then be deployed in SageMaker for the image captioning described in this solution.
An example of a customized image search is Enterprise Resource Planning (ERP). In ERP, image data collected from different stages of logistics or supply chain management could include tax receipts, vendor orders, payslips, and more, which need to be automatically categorized for the purview of different teams within the organization. Another example is to use medical scans and doctor diagnoses to predict new medical images for automatic classification. The vision model extracts features from the MRI, CT, or X-ray images and the text model captions it with the medical diagnoses.
Solution overview
The following diagram shows the architecture for image search with Generative AI and Amazon Kendra.
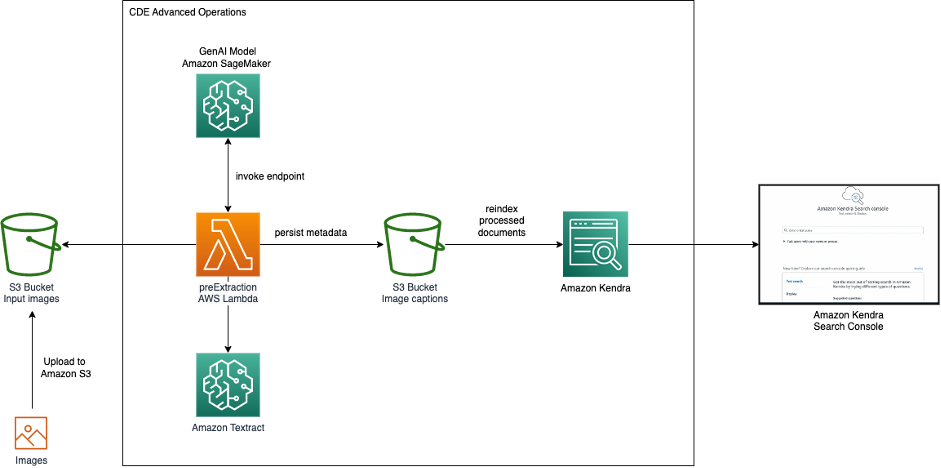
We ingest images from Amazon Simple Storage Service (Amazon S3) into Amazon Kendra. During ingestion to Amazon Kendra, the Generative AI model hosted on SageMaker is invoked to generate an image description. Additionally, text visible in an image is extracted by Amazon Textract. The image description and the extracted text are stored as metadata and made available to the Amazon Kendra search index. After ingestion, images can be searched via the Amazon Kendra search console, API, or SDK.
We use the advanced operations of CDE in Amazon Kendra to call the Generative AI model and Amazon Textract during the image ingestion step. However, we can use CDE for a wider range of use cases. With CDE, you can create, modify, or delete document attributes and content when you ingest your documents into Amazon Kendra. This means you can manipulate and ingest your data as needed. This can be achieved by invoking pre- and post-extraction AWS Lambda functions during ingestion, which allows for data enrichment or modification. For example, we can use Amazon Medical Comprehend when ingesting medical textual data to add ML-generated insights to the search metadata.
You can use our solution to search images through Amazon Kendra by following these steps:
- Upload images to an image repository like an S3 bucket.
- The image repository is then indexed by Amazon Kendra, which is a search engine that can be used to search for structured and unstructured data. During indexing, the Generative AI model as well as Amazon Textract are invoked to generate the image metadata. You can trigger the indexing manually or on a predefined schedule.
- You can then search for images using natural language queries, such as “Find images of red roses” or “Show me pictures of dogs playing in the park,” through the Amazon Kendra console, SDK, or API. These queries are processed by Amazon Kendra, which uses ML algorithms to understand the meaning behind the queries and retrieve relevant images from the indexed repository.
- The search results are presented to you, along with their corresponding textual descriptions, allowing you to quickly and easily find the images you are looking for.
Prerequisites
You must have the following prerequisites:
- An AWS account
- Permissions to provision and invoke the following services via AWS CloudFormation: Amazon S3, Amazon Kendra, Lambda, and Amazon Textract.
Cost estimate
The cost of deploying this solution as a proof of concept is projected in the following table. This is the reason we use Amazon Kendra with the Developer Edition, which is not recommended for production workloads, but provides a low-cost option for developers. We assume that the search functionality of Amazon Kendra is used for 20 working days for 3 hours each day, and therefore calculate associated costs for 60 monthly active hours.
| Service | Time Consumed | Cost Estimate per Month |
| Amazon S3 | Storage of 10 GB with data transfer | 2.30 USD |
| Amazon Kendra | Developer Edition with 60 hours/month | 67.90 USD |
| Amazon Textract | 100% detect document text on 10,000 images | 15.00 USD |
| Amazon SageMaker | Real-time inference with ml.g4dn.xlarge for one model deployed on one endpoint for 3 hours every day for 20 days | 44.00 USD |
| . | . | 129.2 USD |
Deploy resources with AWS CloudFormation
The CloudFormation stack deploys the following resources:
- A Lambda function that downloads the image captioning model from Hugging Face hub and subsequently builds the model assets
- A Lambda function that populates the inference code and zipped model artifacts to a destination S3 bucket
- An S3 bucket for storing the zipped model artifacts and inference code
- An S3 bucket for storing the uploaded images and Amazon Kendra documents
- An Amazon Kendra index for searching through the generated image captions
- A SageMaker real-time inference endpoint for deploying the Hugging Face image
- captioning model
- A Lambda function that is triggered while enriching the Amazon Kendra index on demand. It invokes Amazon Textract and a SageMaker real-time inference endpoint.
Additionally, AWS CloudFormation deploys all the necessary AWS Identity and Access
Management (IAM) roles and policies, a VPC along with subnets, a security group, and an internet gateway in which the custom resource Lambda function is run.
Complete the following steps to provision your resources:
- Choose Launch stack to launch the CloudFormation template in the
us-east-1Region:

- Choose Next.
- On the Specify stack details page, leave the template URL and S3 URI of the parameters file at their defaults, then choose Next.
- Continue to choose Next on the subsequent pages.
- Choose Create stack to deploy the stack.
Monitor the status of the stack. When the status shows as CREATE_COMPLETE, the deployment is complete.
Ingest and search example images
Complete the following steps to ingest and search your images:
- On the Amazon S3 console, create a folder called
imagesin thekendra-image-search-stack-imagecaptionsS3 bucket in theus-east-1Region. - Upload the following images to the
imagesfolder.




- Navigate to the Amazon Kendra console in
us-east-1Region. - In the navigation pane, choose Indexes, then choose your index (
kendra-index). - Choose Data sources, then choose
generated_image_captions. - Choose Sync now.
Wait for the synchronization to be complete before continuing to the next steps.
- In the navigation pane, choose Indexes, then choose
kendra-index. - Navigate to the search console.
- Try the following queries individually or combined: “dog,” “umbrella,” and “newsletter,” and find out which images are ranked high by Amazon Kendra.
Feel free to test your own queries that fit the uploaded images.
Clean up
To deprovisioning all the resources, complete the following step
- On the AWS CloudFormation console, choose Stacks in the navigation pane.
- Select the stack
kendra-genai-image-searchand choose Delete.
Wait until the stack status changes to DELETE_COMPLETE.
Conclusion
In this post, we saw how Amazon Kendra and Generative AI can be combined to automate the creation of meaningful metadata for images. State-of-the-art Generative AI models are extremely useful for generating text captions describing the content of an image. This has several industry use cases, ranging from healthcare and life sciences, retail and ecommerce, digital asset platforms, and media. Image captioning is also crucial for building a more inclusive digital world and redesigning the internet, metaverse, and immersive technologies to cater to the needs of visually challenged sections of society.
Image search enabled through captions enables digital content to be easily searchable without manual effort for these applications, and removes duplication efforts. The CloudFormation template we provided makes it straightforward to deploy this solution to enable image search using Amazon Kendra. A simple architecture of images stored in Amazon S3 and Generative AI to create textual descriptions of the images can be used with CDE in Amazon Kendra to power this solution.
This is only one application of Generative AI with Amazon Kendra. To dive deeper into how to build Generative AI applications with Amazon Kendra, refer to Quickly build high-accuracy Generative AI applications on enterprise data using Amazon Kendra, LangChain, and large language models. For building and scaling Generative AI applications, we recommend checking out Amazon Bedrock.
About the Authors
 Charalampos Grouzakis is a Data Scientist within AWS Professional Services. He has over 11 years of experience in developing and leading data science, machine learning, and big data initiatives. Currently he is helping enterprise customers modernizing their AI/ML workloads within the cloud using industry best practices. Prior to joining AWS, he was consulting customers in various industries such as Automotive, Manufacturing, Telecommunications, Media & Entertainment, Retail and Financial Services. He is passionate about enabling customers to accelerate their AI/ML journey in the cloud and to drive tangible business outcomes.
Charalampos Grouzakis is a Data Scientist within AWS Professional Services. He has over 11 years of experience in developing and leading data science, machine learning, and big data initiatives. Currently he is helping enterprise customers modernizing their AI/ML workloads within the cloud using industry best practices. Prior to joining AWS, he was consulting customers in various industries such as Automotive, Manufacturing, Telecommunications, Media & Entertainment, Retail and Financial Services. He is passionate about enabling customers to accelerate their AI/ML journey in the cloud and to drive tangible business outcomes.
 Bharathi Srinivasan
is a Data Scientist at AWS Professional Services where she loves to build cool things on Sagemaker. She is passionate about driving business value from machine learning applications, with a focus on ethical AI. Outside of building new AI experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.
Bharathi Srinivasan
is a Data Scientist at AWS Professional Services where she loves to build cool things on Sagemaker. She is passionate about driving business value from machine learning applications, with a focus on ethical AI. Outside of building new AI experiences for customers, Bharathi loves to write science fiction and challenge herself with endurance sports.
 Jean-Michel Lourier is a Senior Data Scientist within AWS Professional Services. He leads teams implementing data driven applications side by side with AWS customers to generate business value out of their data. He’s passionate about diving into tech and learning about AI, machine learning, and their business applications. He is also an enthusiastic cyclist, taking long bike-packing trips.
Jean-Michel Lourier is a Senior Data Scientist within AWS Professional Services. He leads teams implementing data driven applications side by side with AWS customers to generate business value out of their data. He’s passionate about diving into tech and learning about AI, machine learning, and their business applications. He is also an enthusiastic cyclist, taking long bike-packing trips.
 Tanvi Singhal is a Data Scientist within AWS Professional Services. Her skills and areas of expertise include data science, machine learning, and big data. She supports customers in developing Machine learning models and MLops solutions within the cloud. Prior to joining AWS, she was also a consultant in various industries such as Transportation Networking, Retail and Financial Services. She is passionate about enabling customers on their data/AI journey to the cloud.
Tanvi Singhal is a Data Scientist within AWS Professional Services. Her skills and areas of expertise include data science, machine learning, and big data. She supports customers in developing Machine learning models and MLops solutions within the cloud. Prior to joining AWS, she was also a consultant in various industries such as Transportation Networking, Retail and Financial Services. She is passionate about enabling customers on their data/AI journey to the cloud.
 Abhishek Maligehalli Shivalingaiah is a Senior AI Services Solution Architect at AWS with focus on Amazon Kendra. He is passionate about building applications using Amazon Kendra ,Generative AI and NLP. He has around 10 years of experience in building Data & AI solutions to create value for customers and enterprises. He has built a (personal) chatbot for fun to answers questions about his career and professional journey. Outside of work he enjoys making portraits of family & friends, and loves creating artworks.
Abhishek Maligehalli Shivalingaiah is a Senior AI Services Solution Architect at AWS with focus on Amazon Kendra. He is passionate about building applications using Amazon Kendra ,Generative AI and NLP. He has around 10 years of experience in building Data & AI solutions to create value for customers and enterprises. He has built a (personal) chatbot for fun to answers questions about his career and professional journey. Outside of work he enjoys making portraits of family & friends, and loves creating artworks.