Artificial Intelligence
Category: Learning Levels

Transcribe, translate, and summarize live streams in your browser with AWS AI and generative AI services
In this post, we explore the approach behind building an AWS AI-powered Chrome extension that aims to revolutionize the live streaming experience by providing real-time transcription, translation, and summarization capabilities directly within your browser.

Accelerate your financial statement analysis with Amazon Bedrock and generative AI
In this post, we demonstrate how to deploy a generative AI application that can accelerate your financial statement analysis on AWS.

Build a reverse image search engine with Amazon Titan Multimodal Embeddings in Amazon Bedrock and AWS managed services
In this post, you will learn how to extract key objects from image queries using Amazon Rekognition and build a reverse image search engine using Amazon Titan Multimodal Embeddings from Amazon Bedrock in combination with Amazon OpenSearch Serverless Service.

Deliver personalized marketing with Amazon Bedrock Agents
In this post, we demonstrate a solution using Amazon Bedrock Agents, Amazon Bedrock Knowledge Bases, Amazon Bedrock Developer Experience, and Amazon Personalize that allow marketers to save time and deliver efficient personalized advertising using a generative AI enhanced solution. Our solution is a marketing agent that shows how Amazon Personalize can effectively segment target customers based on relevant characteristics and behaviors. Additionally, by using Amazon Bedrock Agents and foundation models (FMs), our tool generates personalized creative content specifically tailored to each purpose. It customizes the tone, creative style, and individual preferences according to each customer’s specific prompt, providing highly customized and effective marketing communications.

Fine-tune Meta Llama 3.2 text generation models for generative AI inference using Amazon SageMaker JumpStart
In this post, we demonstrate how to fine-tune Meta’s latest Llama 3.2 text generation models, Llama 3.2 1B and 3B, using Amazon SageMaker JumpStart for domain-specific applications. By using the pre-built solutions available in SageMaker JumpStart and the customizable Meta Llama 3.2 models, you can unlock the models’ enhanced reasoning, code generation, and instruction-following capabilities to tailor them for your unique use cases.

Build a multi-tenant generative AI environment for your enterprise on AWS
While organizations continue to discover the powerful applications of generative AI, adoption is often slowed down by team silos and bespoke workflows. To move faster, enterprises need robust operating models and a holistic approach that simplifies the generative AI lifecycle. In the first part of the series, we showed how AI administrators can build a […]

Integrate foundation models into your code with Amazon Bedrock
The rise of large language models (LLMs) and foundation models (FMs) has revolutionized the field of natural language processing (NLP) and artificial intelligence (AI). These powerful models, trained on vast amounts of data, can generate human-like text, answer questions, and even engage in creative writing tasks. However, training and deploying such models from scratch is […]
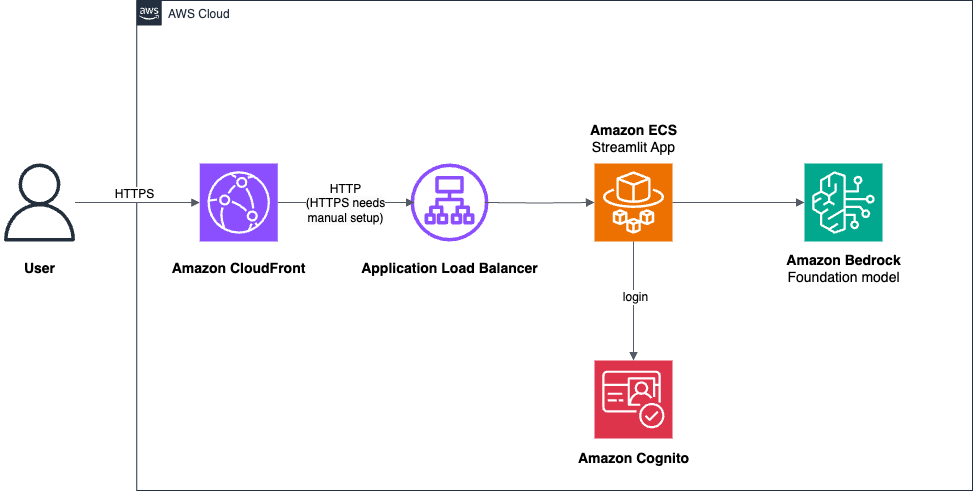
Build and deploy a UI for your generative AI applications with AWS and Python
AWS provides a powerful set of tools and services that simplify the process of building and deploying generative AI applications, even for those with limited experience in frontend and backend development. In this post, we explore a practical solution that uses Streamlit, a Python library for building interactive data applications, and AWS services like Amazon Elastic Container Service (Amazon ECS), Amazon Cognito, and the AWS Cloud Development Kit (AWS CDK) to create a user-friendly generative AI application with authentication and deployment.

Unearth insights from audio transcripts generated by Amazon Transcribe using Amazon Bedrock
In this post, we examine how to create business value through speech analytics with some examples focused on the following: 1) automatically summarizing, categorizing, and analyzing marketing content such as podcasts, recorded interviews, or videos, and creating new marketing materials based on those assets, 2) automatically extracting key points, summaries, and sentiment from a recorded meeting (such as an earnings call), and 3) transcribing and analyzing contact center calls to improve customer experience.

Best practices and lessons for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock
In this post, we explore the best practices and lessons learned for fine-tuning Anthropic’s Claude 3 Haiku on Amazon Bedrock. We discuss the important components of fine-tuning, including use case definition, data preparation, model customization, and performance evaluation.